[Webinar] AI-Powered Innovation with Confluent & Microsoft Azure | Register Now
Defrag Your Data Architecture
With many operating systems you have to periodically run a disk defragmenter program (“defrag”) to restore your system efficiency. By reorganizing the data stored on disk, sequential data becomes more easily accessible and your system’s read performance increases. The same idea is true with your data architecture. Over time, as you accumulate new applications, data stores, systems, and computing environments, data silos emerge. This is conceptually similar to file fragmentation with disks. Your data architecture can be “defragged” in the same sense that disks can.
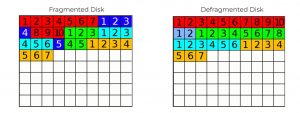
Source: Defragmentation
Fragmented data architectures are bad for business because they have a lot of costs. With no centralized way of bringing data from all of your systems together, your development teams can’t innovate. Data scientists are forced to use stale data provided by periodic batch jobs for analytics, if they can get the data they need at all. And your applications are not real time, which is a missed opportunity at best, and bad customer experience at worst.
To be clear, fragmentation in data architectures isn’t anybody’s fault or even the product of any sort of negligence. It’s the result of an incremental accumulation of data systems over time. As you add more and more components to your data architecture and connect them together using point-to-point solutions, fragmentation naturally occurs. The connections between individual systems grow organically into a giant spaghetti-like mess. It’s like packing boxes away into a warehouse, piece by piece. As time goes on, more and more boxes are put into the warehouse, but fewer and fewer people know what is stored where, who needs what, or how to access things that were packed away by other teams in the past. Nothing is ever removed or reorganized from fear it might cause a problem, but ultimately the lack of organization and accessibility is the problem.
Fragmented data architecture
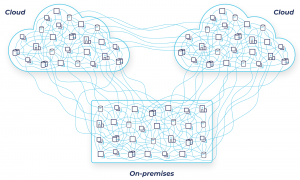
So what are you supposed to do in this situation? You can’t slow down and risk delaying projects. You also need to maintain your existing systems. How can you defrag your data architecture and clean up this mess of point-to-point connections, all while running your business and keeping costs down?
The first step is to envision the end state you’re solving for. Imagine what would be possible if you replaced all of these individual connections with a singular and real-time data plane that unified all of the systems across all parts of your global enterprise. Anybody from any part of your business could easily access and utilize all of your organization’s data in order to power innovative, new real-time applications. This would unlock an infinite number of use cases and position your business to crush your competitors, while reducing costs by eliminating inefficiencies.
Defragmented data architecture
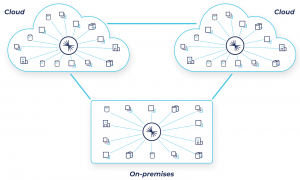
Now let’s look at what you need to turn this vision into reality. You need a solution that seamlessly integrates with your existing systems and doesn’t interrupt business operations. This is a key point. A robust ecosystem of pre-built connectors into whatever data platform you choose is essential. Otherwise, you’ll end up spending months on custom integration projects, which is exactly the opposite of what you’re looking to accomplish.
You should also choose a solution that runs everywhere. It doesn’t make sense to upgrade your data architecture to include different data platforms for each on-prem and cloud environment, if you can avoid it. It’s much better to standardize on one platform, one set of APIs, and one trusted partner. This also helps future-proof your technology stack by maximizing data mobility, giving you optionality. If you want to try some new cloud service in the future, you can easily do so.
And last but not least, you want to choose a solution that is fast. In today’s world, software is the business, and real-time software that operates on continuous streams of events wins over slow software that operates on periodic batch jobs, period. Customers and internal stakeholders have come to expect dynamic, personalized, and real-time experiences from software applications, and have little patience for slow apps or outdated information. Whatever solution you choose, make sure it’s lightning fast.
Defragging your data architecture is great because you can do it with zero downtime, using any combination of on-prem and cloud systems, over any timeline that works for you. Start onboarding workloads onto your new data platform using something like Kafka Connect to easily integrate your existing systems. As you move incrementally from batch to real time you can take advantage of stream processing engines like ksqlDB, which make it easy to add intelligence to streaming data as it flows between systems. And as an added benefit, the more workloads you onboard onto your data platform, the more valuable the platform becomes. New teams will want to leverage the platform because of all of the other data sources and syncs on the platform, so you’ll benefit from organic network effects.
At Confluent, we have built a platform for data in motion that is complete, cloud native, and everywhere. We partner with customers for the long term and provide our partners with the technology they need to defrag their data architectures along with our experience working with thousands of organizations across all industries to modernize their businesses. The end result is increased revenue, lower costs, less risk, and happier customers.
Learn more about Confluent’s solution for hybrid and multicloud architectures, or get started now with a free trial of Confluent Cloud! Get an additional $60 of free usage when you use the promo code CL60BLOG.*
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Beyond Boundaries: Leveraging Confluent for Secure Inter-Organizational Data Sharing
Discover how Confluent enables secure inter-organizational data sharing to maximize data value, strengthen partnerships, and meet regulatory requirements in real time.



Real-Time Toxicity Detection in Games: Balancing Moderation and Player Experience
Prevent toxic in-game chat without disrupting player interactions using a real-time AI-based moderation system powered by Confluent and Databricks.