[Webinar] AI-Powered Innovation with Confluent & Microsoft Azure | Register Now
Dawn of Kafka DevOps: Managing Multi-Cluster Kafka Connect and KSQL with Confluent Control Center
In anything but the smallest deployment of Apache Kafka®, there are often going to be multiple clusters of Kafka Connect and KSQL. Kafka Connect is used for building event streaming data pipelines between upstream and downstream systems with Kafka, and KSQL is used for building stream processing applications declared in a SQL-like language. People will have multiple clusters of these for various reasons, including:
- Resource isolation
- You don’t want a sudden influx of data from a source upstream to impact other connectors
- Capacity planning is easier
- Kafka Connect rebalances when connectors are added/removed, and this can impact the performance of other connectors on the same cluster
- Environment separation: For example, one cluster for production, another for non-production environments such as staging, UAT and development.
- Varying ownership and operations responsibility (important for avoiding recreating the ESB antipattern)
- Application separation: With KSQL we are building applications comprised of a discrete set of SQL statements—just as we deploy application services independently, so we can also consider doing the same with KSQL
- Security: KSQL servers and Kafka Connect authenticate to the Kafka cluster as a given user, and you may want to grant different applications/pipelines access to different topics
Both Kafka Connect and KSQL can be managed and interacted with using a REST API, but many people prefer a GUI. Confluent Control Center enables you to work with multiple clusters of each. Part of the Confluent Platform, Confluent Control Center is free to use forever under the developer license on single-broker Kafka clusters. Check out part 1 of this series how Confluent Control Center can be used to interact with the Schema Registry.
Multi-cluster in action
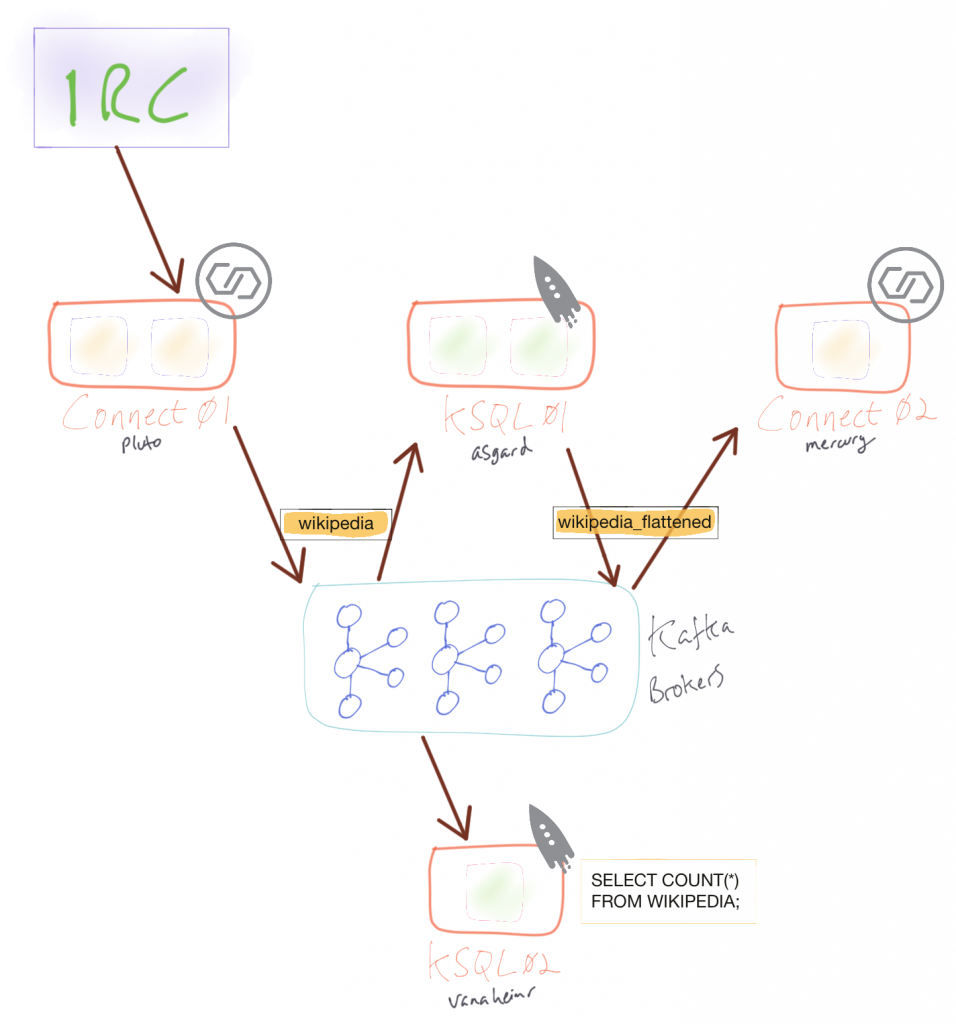
In this example, there are two clusters of Kafka Connect and two KSQL clusters. The Connect clusters are run by separate teams: one ingesting data from a source, the other taking transformed data and streaming it to a database. KSQL is used to provide two stream processing applications for different purposes. The first takes the ingested data and transforms the nested structures into a flat one suitable for event streaming to a database. The second KSQL application is used for calculating analytics on the data as it is ingested.
Streaming data into Kafka with Kafka Connect
First up we have Kafka Connect running as a cluster called pluto, which we select from the dropdown in the top-right corner.
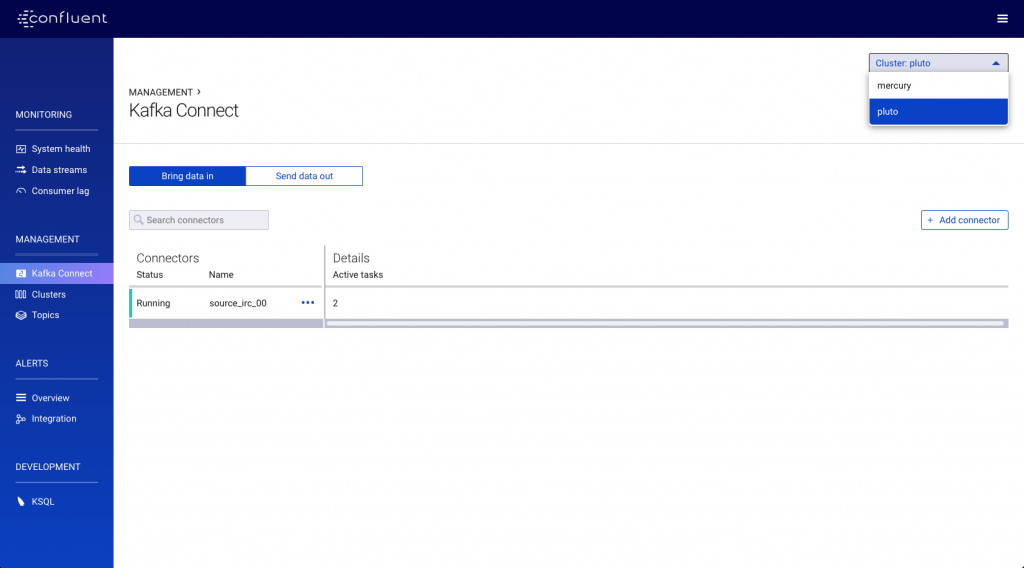
The cluster is running a single connector using the Kafka Connect IRC plugin to stream messages about edits made to Wikipedia to a topic called wikipedia:
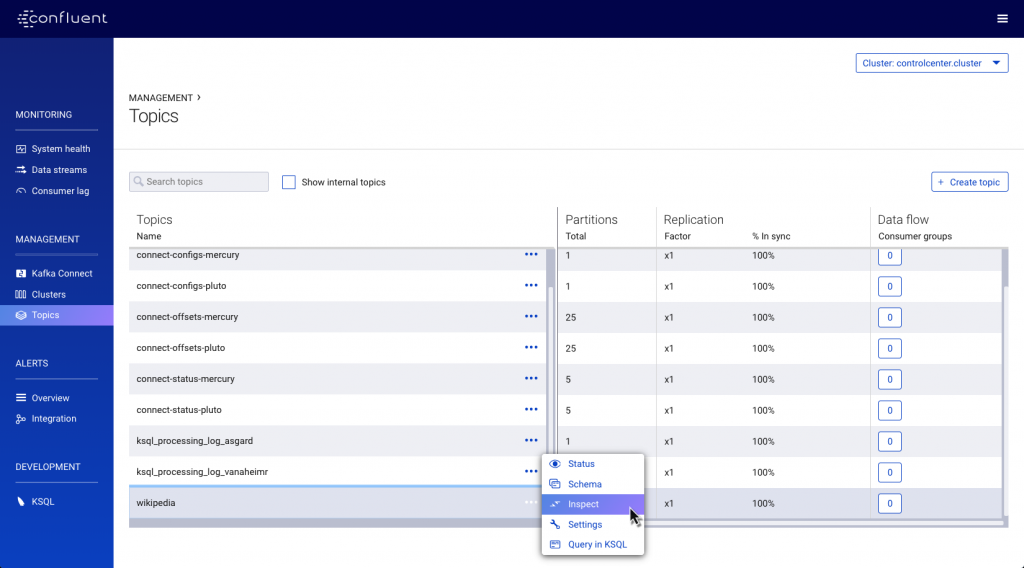
The data in the topic is easily inspected using Confluent Control Center:
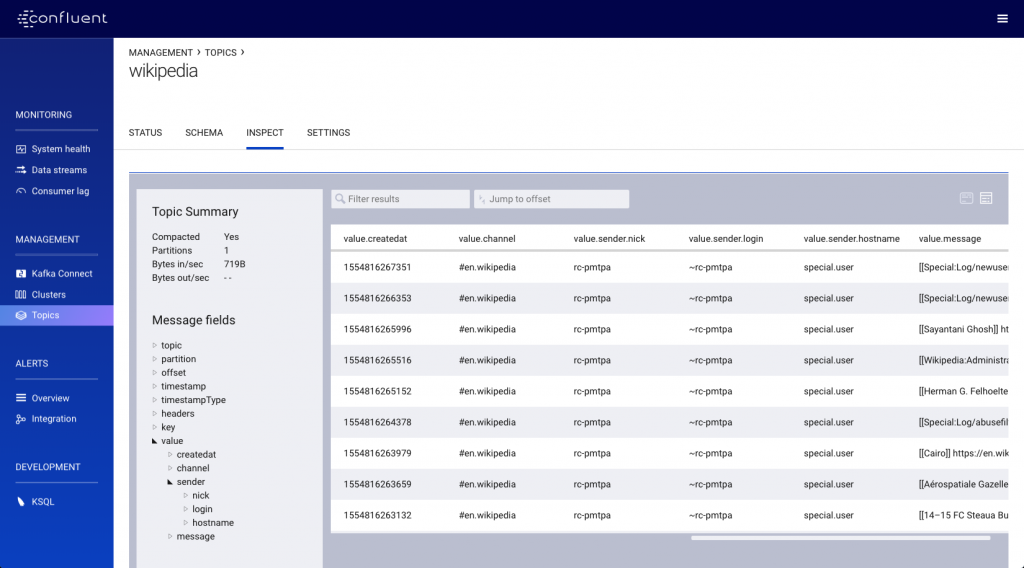
From this, we can see that the message data includes a nested element (sender), which we need to flatten out before landing it to the target database. For this, we’ll use KSQL.
Transforming data with KSQL
Defining the KSQL application is easy. First, we need to map the Kafka topic to a KSQL stream, selecting the desired KSQL cluster from the dropdown menu in the top-right of the screen:
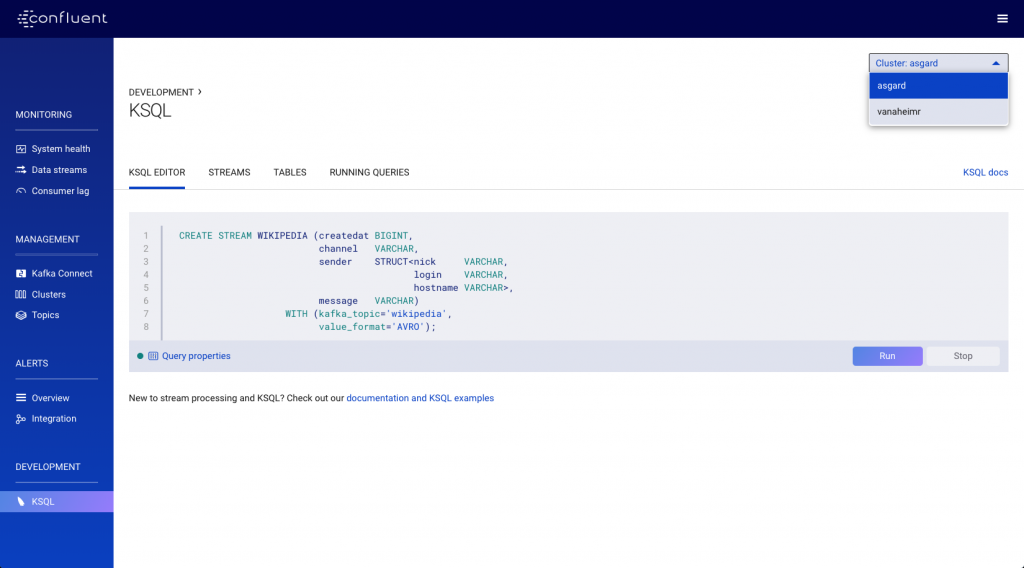
With the stream created, we can then specify the transformation:
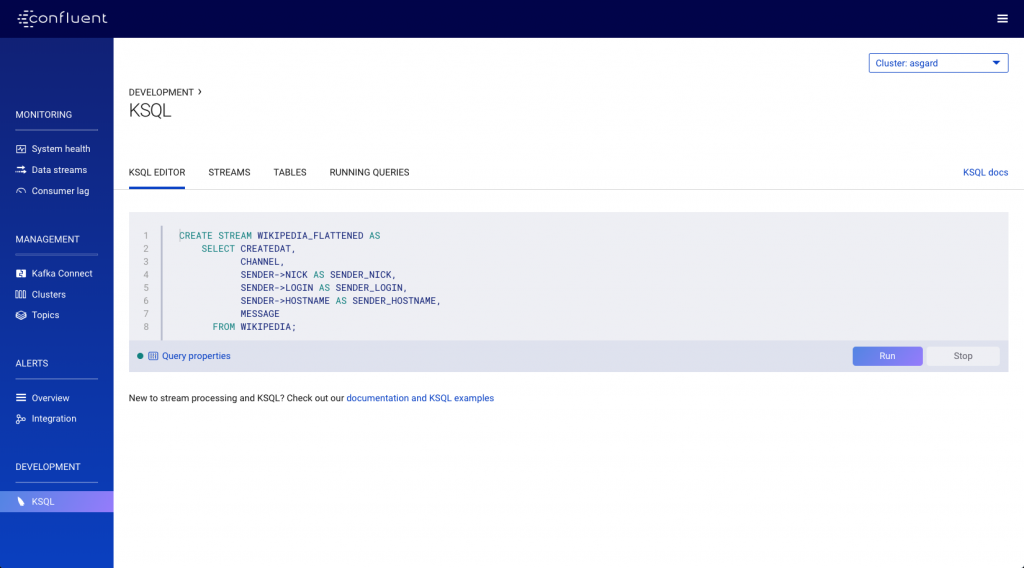
As each inbound message is received on the original wikipedia topic, it’s transformed and written to the new WIKIPEDIA_FLATTENED topic:
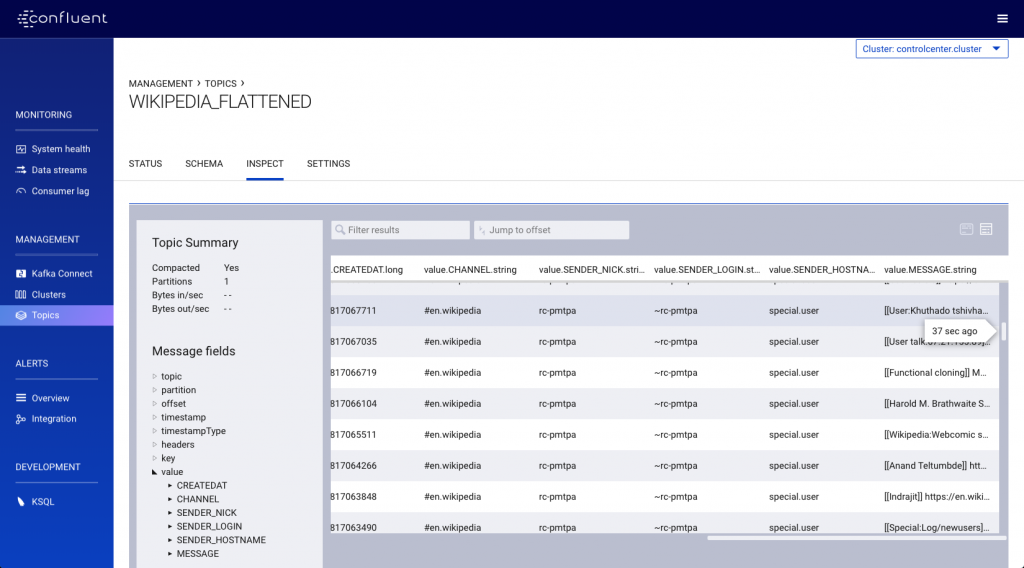
Streaming data from Kafka to a database with Kafka Connect
Now we have a stream of non-nested data we can stream it to the target database. We’re going to use a different Kafka Connect cluster here, selected as before from the dropdown menu in the top right of the screen:
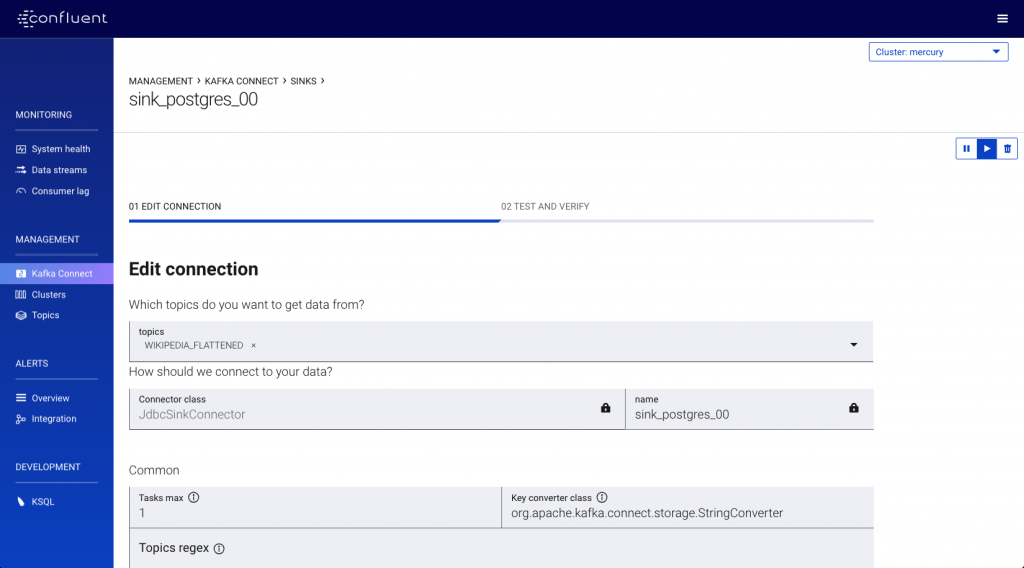
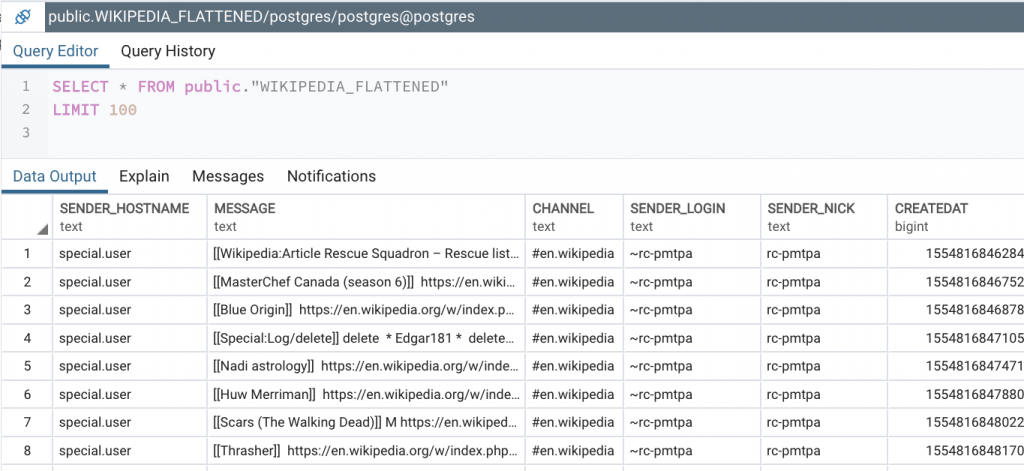
With the connector running, the data streams down to the target database as it arrives on the topic:
Streaming analytics with KSQL
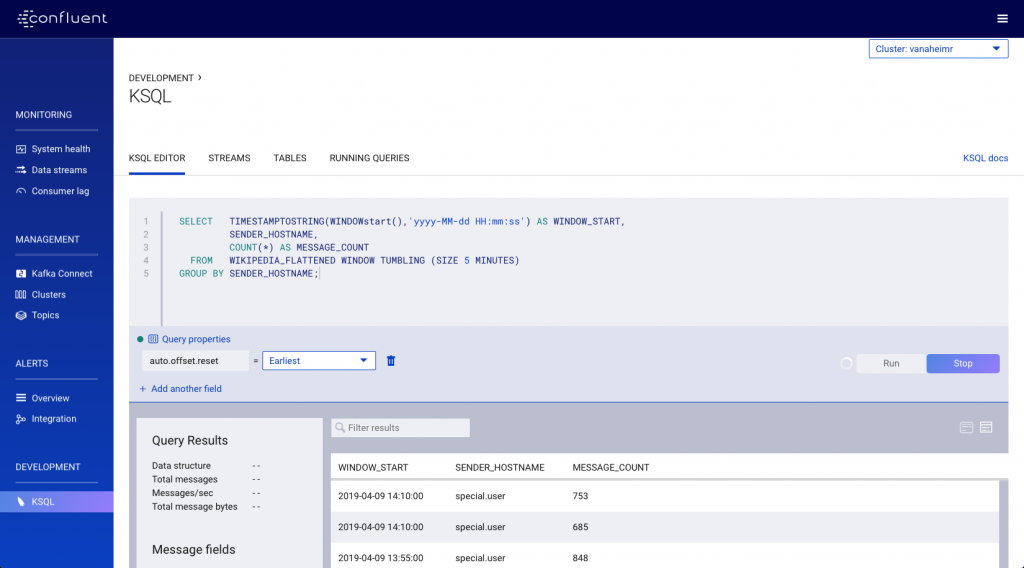
The KSQL application that we built above is responsible for one thing, and that is producing flattened messages. We may well decide to deploy that application on its own KSQL cluster, similarly to how we’d deploy a Java application on its own runtime for isolation, deployment and management purposes. We’ve got another KSQL application to run for analytical purposes to calculate the number of messages per five-minute time window that are received. We’re going to run it on a separate KSQL cluster.
We’ll map the KSQL stream on top of the Kafka topic directly, using the flattened topic created above. As before, select the appropriate cluster name from the top right of the window:
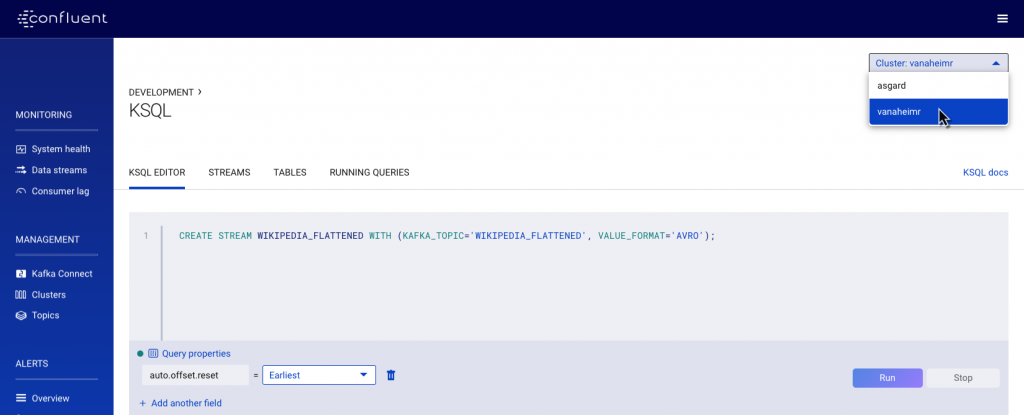
With the stream defined in the new cluster, we can run our analytics against it:
Interested in more?
Confluent Platform helps you build, monitor and manage event streaming pipelines on Apache Kafka. With the latest version of Confluent Control Center, you can now do that at enterprise scale from a single pane of glass.
If you’d like to know more, you can download the Confluent Platform to get started with the leading distribution of Apache Kafka.
Other articles in this series
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...