[Webinar] AI-Powered Innovation with Confluent & Microsoft Azure | Register Now
Confluent Platform 4.1 with Production-Ready KSQL Now Available
We are pleased to announce that Confluent Platform 4.1, our enterprise streaming platform built on Apache Kafka®, is available for download today. With Confluent Platform, you get the latest in streaming technology packaged into one integrated and production-ready platform.
Let’s dig in to what’s new.
New in Confluent Platform 4.1
KSQL is ready for production use, and integrated into CP
KSQL, the streaming SQL engine for Apache Kafka, is now ready for production use! We launched the developer preview in August 2017, and the uptake by the community since then has been tremendous. Thanks to the community’s inputs and rigorous testing, KSQL is now ready to power your production stream processing use cases.
CREATE TABLE possible_fraud AS
SELECT card_number, count(*)
FROM authorization_attempts
WINDOW TUMBLING (SIZE 5 SECONDS)
GROUP BY card_number
HAVING count(*) > 3;
KSQL is fully integrated into the Confluent Platform. That means you can use our getting started guide to launch the platform, load data into topics and write KSQL against that data in your development environment—then deploy those same KSQL queries on the production-ready Confluent Platform.
KSQL builds upon Kafka’s Streams API, which means it’s an elastically scalable, fault tolerant, distributed and real-time stream processing system. Additionally, Apache Kafka 1.1 provides a number of operational and performance improvements that contribute to the robustness of both Kafka’s Streams API and KSQL. If you’re interested in the details, check out KIPs 205, 210, 220, 224 and 239 for more information.
Manage topics with Confluent Control Center
With Confluent Control Center, you can now manage your Kafka topics through an intuitive web-based interface. It now takes just a few clicks to create, update, delete and list topics.
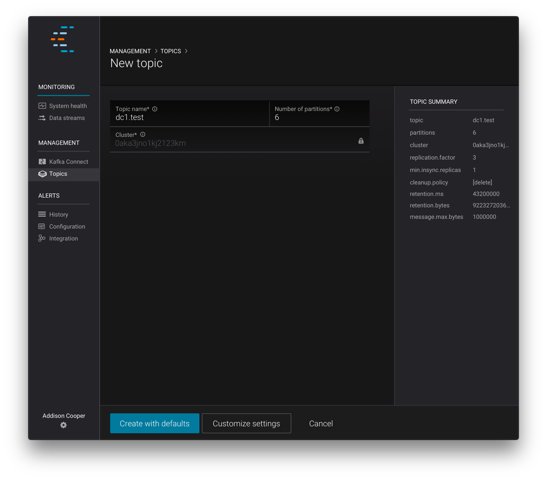
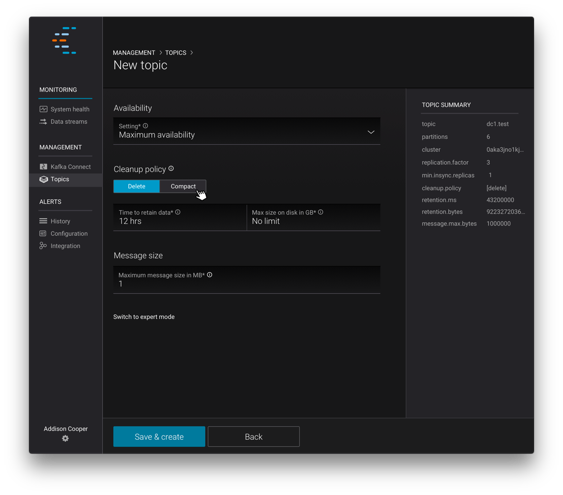
Control Center provides a single pane of glass to monitor and manage multiple Confluent clusters. And with support for read-only Control Center users, you can now share access throughout your operations and development teams, allowing cluster and topic management privileges only for those users you intend.
Deploy across cloud regions and in hybrid on-premises environments
Our customers depend on Confluent Replicator to power their multi-region data architectures. With CP 4.1, Replicator doesn’t need to connect to ZooKeeper directly anymore, so it works with a Confluent Cloud environment where only the Kafka brokers are exposed.
Replicator now has a simpler, easier-to-operate interface, making it simpler to configure and control high-performance, cross-region replication and it integrates with Control Center for monitoring replication lag. If you prefer, you can still run the Replicator connector just as before.
We are also happy to provide three new JMS source connectors. Now you can seamlessly migrate data from ActiveMQ, IBM MQ and other JMS-compliant brokers to Apache Kafka.
Enhanced .NET, Python, Go and C/C++ clients
Kafka is seeing wider and wider use in the .NET community. This release brings the benefits of managed schema evolution to users of .NET languages with the much-anticipated support for Avro serialized data and Confluent Schema Registry.
With Confluent Platform 4.1, the Python, Go and C/C++ clients get support for Message headers. Python developers can also look forward to a simplified installation experience, thanks to Python Wheels.
The latest Apache Kafka
Confluent Platform 4.1 includes Apache Kafka 1.1. This new version of Kafka introduces dynamic broker configurations, which allows multiple broker configurations to be updated without needing to restart the broker. It also includes significant Kafka Controller improvements that enable faster controlled shutdown times and ten times more partitions per cluster. Look for a near-future blog post from us where we dig into the details of the latter.
There are many more performance and bug fixes included in Apache Kafka 1.1. Check out the release notes for the full accounting of the changes.
Last but not least, operations teams can now use systemd scripts to manage the starting, stopping and restarting of all Confluent Platform component processes in production environments.
Get started now!
Getting Confluent Platform 4.1 up and running just takes a single command: confluent start. Get started with our tutorial, or join us for our online KSQL panel discussion.
Confluent Platform 4.1 is backed by our subscription support. The easiest way to get started is to install a free 30-day trial of Confluent Platform. Details for both can be found on our download page or you can learn more by reading our documentation. We also offer expert training and technical consulting to help get your organization started.
As always, we are happy to hear your feedback. Please post your questions and suggestions to the public Confluent Platform mailing list, or join our community Slack channel.
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...