[Live-Demo] Tableflow, Freight Clusters, Flink KI-Funktionen | Jetzt registrieren
Confluent Cloud KSQL is Now Available
Today, we are excited to announce that after a highly productive period of being in private preview, Confluent Cloud KSQL is now production ready and available to all Confluent Cloud customers on usage-based billing plans. Before presenting an overview of Confluent Cloud KSQL’s features, we would like to briefly provide some background around what led us here, and why we believe KSQL is such an important technology.
Apache Kafka® is increasingly becoming the single source of truth for many organizations’ data. And as these organizations continue to prefer cloud-hosted infrastructure in order to reduce their operational burdens, Confluent Cloud provides one of the easiest ways to obtain a robust, production-ready Kafka environment in just a few minutes. As the central nervous system for your data, a fully managed Kafka environment eliminates the complexities around operating critical infrastructure. But the true value of data is derived from whatever an organization actually does with it.
Producers push events into Kafka, and consumers pull them out for downstream processing. Often this processing is done using complex application code performing very common operations: transformations, enrichment, joining events together, and aggregation are all fundamental to most data processing pipelines. Real-time processing brings an organization’s data to life by invigorating it with a certain level of autonomous intelligence. If Kafka is the central nervous system, then the stream processing layer is the brain, taking streams of events as input, applying predefined logic, and producing new streams as output.
And just as traditional databases have abstracted away common operations performed on data at rest, stream processing tools offer the same abstractions for event streaming. KSQL enables users to define this processing using largely standard SQL syntax, making it immediately accessible to most organizations. No complex application code is required—KSQL will take SQL queries and figure out how to continuously execute them efficiently atop torrents of streaming events.
KSQL’s accessibility is further amplified in Confluent Cloud, where KSQL is available as a fully managed service. In addition to providing the immense benefits of SQL queries over code, Confluent Cloud KSQL eliminates the innate complexities of operating infrastructure in production. We take care of running production-grade infrastructure at scale while you focus on solving business problems with KSQL. Transformations, stream-to-stream joins, aggregations, and data enrichment can all be accomplished using KSQL with just a few lines of SQL.
In addition to providing the core capabilities of KSQL, Confluent Cloud KSQL also layers on valuable functionality based on everything we’ve learned about how organizations are doing stream processing. In particular, Confluent Cloud KSQL’s intuitive web interface is designed to simplify your interactions with KSQL: create streams and tables with a few clicks, or submit continuous SQL queries through the query editor while browsing the schemas of the various streams and tables your queries target.
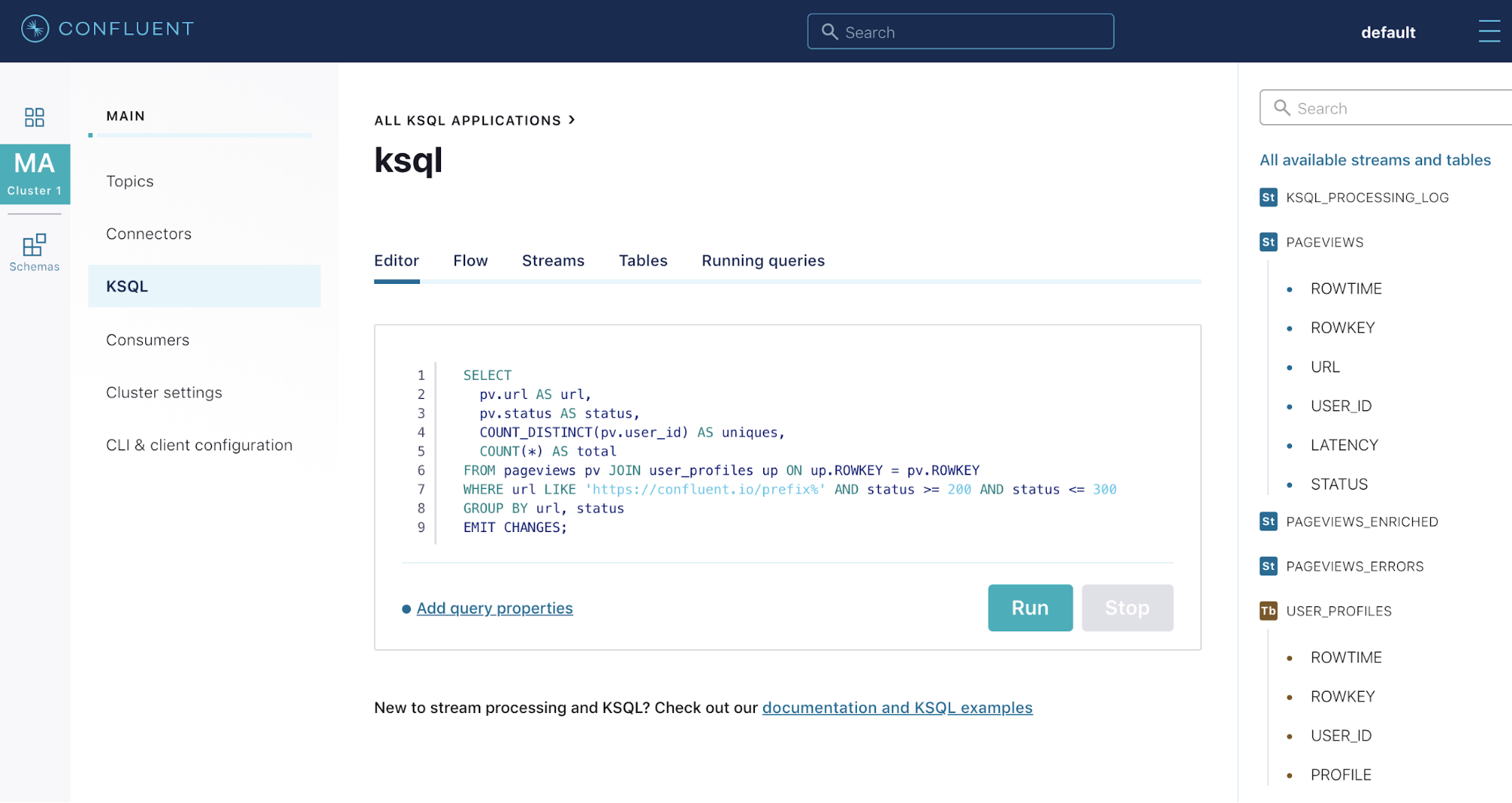
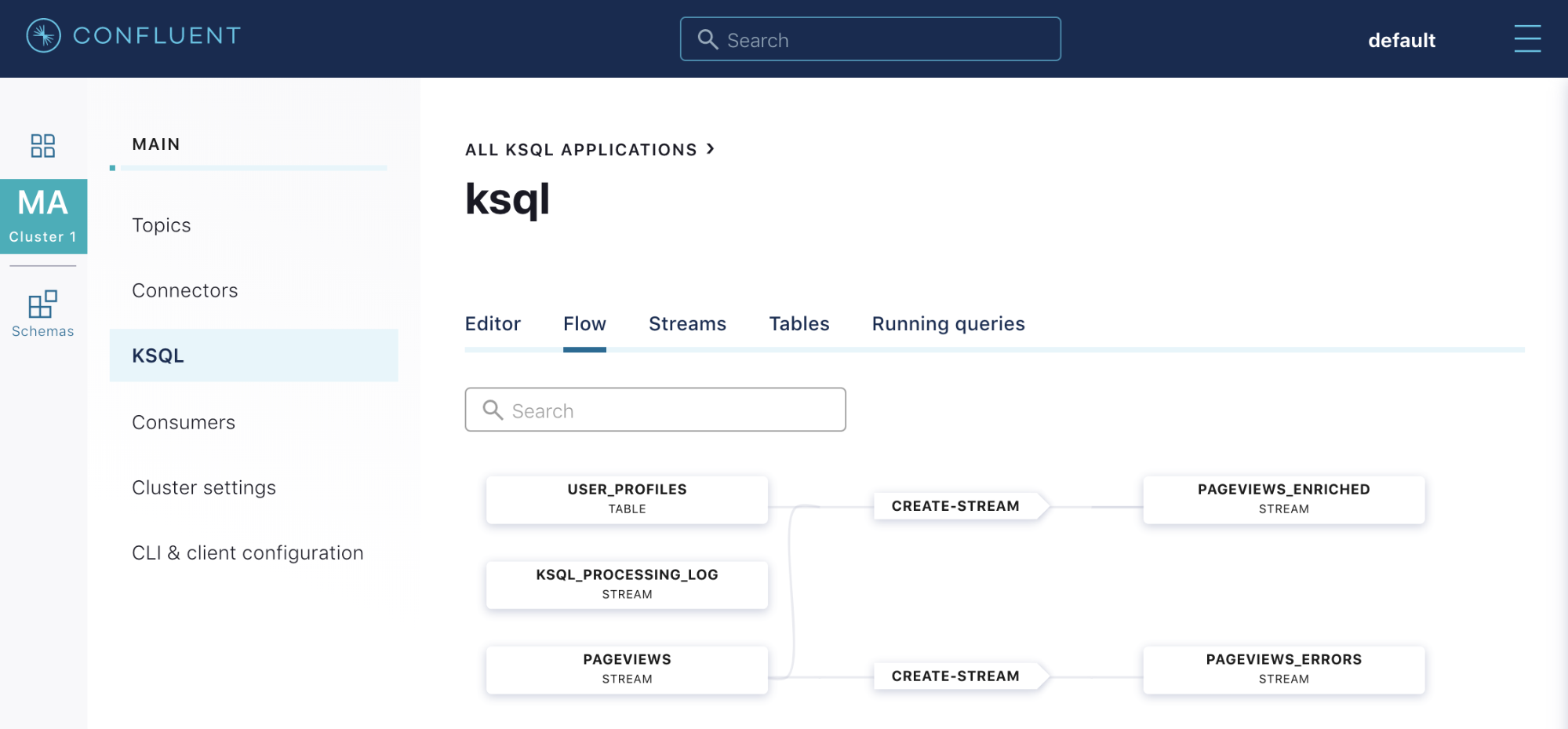
As you create and chain together more of these continuous queries, stream processing workloads can become complex. To help manage this complexity, Confluent Cloud KSQL includes a “Flow” view that visualizes your end-to-end workload as a topology of continuous queries. Individual queries in the processing topology can be inspected to examine messages flowing through them or to identify throughput bottlenecks in your workload. The status of each continuous query can be quickly evaluated in a single place in order to help you ensure that your topology is healthy.
Your applications can also programmatically integrate with Confluent Cloud KSQL by securely connecting to your KSQL application’s REST endpoint, bypassing the web interface entirely. In fact, you have unrestricted access to the same APIs that the web interface uses, enabling you to develop deep integrations that deliver real-time intelligence to your applications and services.
Confluent Cloud KSQL also integrates seamlessly with the other components of Confluent Cloud, which are designed to work together synergistically. Your KSQL applications will be connected to Kafka and Schema Registry out of the box, and deeper integration with Kafka Connect is planned for a future release. Regardless of how you choose to use Confluent Cloud KSQL, no operational overhead is required on your part. We’ll ensure that your application runs with the highest degree of reliability in production while you focus on solving business problems.
Get started with Confluent Cloud KSQL
To start using Confluent Cloud KSQL, you can sign up for Confluent Cloud, a fully managed event streaming service based on Apache Kafka, and get $50 of free usage each month for the first three months. Once you sign in to Confluent Cloud, these links will help you get started with KSQL quickly:
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...