[Webinar] AI-Powered Innovation with Confluent & Microsoft Azure | Register Now
Mock APIs vs. Real Backends – Getting the Best of Both Worlds
When building API-driven web applications, there is one key metric that engineering teams should minimize: the blocked factor. The blocked factor measures how much time developers spend in the following situations:
- Waiting for external API dependencies
- Working to unblock themselves from those dependencies
Ever spend a week unable to work on a project because the backend REST endpoints aren’t ready yet? That goes into the blocked factor. What if you only spend a day bootstrapping your local environment by hard-coding responses in a mock server? Well, that counts too.
When working with upstream dependencies, it’s not realistic to completely avoid such situations. Multi-team software engineering can get complicated, and there are many factors out of our control. Still, we should do our best to keep the blocked factor to a minimum, because one thing is certain: wasting time is bad.
At Confluent, we created Mox to help us mitigate the blocked factor. Mox is a lightweight combination of a proxy server and a mocking framework that you can use to proxy your endpoints that work and mock the ones that don’t. To understand how it works and whether it applies to your engineering workflow, we’ll deep dive into how UI teams typically work with external APIs.
To mock, or not to mock
In software design, the flexibility-usability tradeoff states that the easier something is to use, the less flexible it is. This means that systems with broad applicability tend to be more difficult or complicated to use than systems that focus on just one function. A Swiss Army knife is flexible since it serves many uses, but is more difficult to use than a simpler tool like a screwdriver.
Modern web frameworks like React or AngularJS are great examples of this principle. Compared to using pure JavaScript, these frameworks are opinionated about how developers should interact with them. This makes them less flexible than arbitrary JavaScript, but also far more usable for the right use cases.
Engineering teams face this trade-off when deciding how to integrate external APIs into their development workflow. For the most part, there are two common approaches, each on one end of the flexibility-usability scale.
API mocks
A flexible API mock approach requires a framework for simulating a backend API, which involves specifying endpoint routes (e.g., GET /api/status) as well as response behaviors (e.g., response payload and status code). Mock frameworks typically come with a server implementation that allows them to easily run in a local environment.
Here are some advantages to using API mocks in your development workflow:
- You can do feature work even if your external dependencies are unavailable.
- Mock API frameworks are generally quite flexible. They can be programmed to emulate almost any external API.
- Because they are lightweight, mock servers are quick to iterate on, requiring much less time to redeploy changes than an actual dev backend.
- Mock servers are often stateless, which makes repeatedly testing the same scenarios very easy.
You may notice that many of the advantages of mocking API dependencies are related to flexibility. Mocking offers valuable agility when it comes to working with external dependencies since it places their behavior in your control. However, with great power comes great responsibility. Here are some disadvantages to consider when mocking your APIs:
- While mocks are good for initial feature development, they often require continued maintenance to stay up to date. Features, and in turn their APIs, usually evolve over time as new functionality is added, which requires not only changes to client code but also to the mocks.
- It’s not always obvious when your mocks are out of date and need to be updated. Changes to API behavior are sometimes hard to notice until much later.
- It’s your responsibility to mock the APIs exactly how they would behave in production. Writing them almost correctly can easily backfire.
How do mocks affect our blocked factor? Mock servers give us an outlet to convert passive time spent being blocked into active time spent unblocking ourselves. This is usually a good trade because API mocks generally don’t take much time to write compared to how long we might have to wait to get working backend endpoints. The downside is that API mocks can require additional, ongoing effort to maintain even long after their associated feature is released.
Live backend
In lieu of mocking your external dependencies, you can use them outright. Cloud-based engineering organizations usually have the concept of dev, staging, and production environments. Here, using a live backend usually involves pointing a local frontend application at the hosted dev environment.
Using an external backend is pretty straightforward. All you have to do is plug it into your local build. It may require work to integrate your codebase with a real API, but that isn’t exactly a disadvantage. You would need to do it regardless of your development workflow.
However, there is a massive flexibility downside to this approach. Completely relying on a hosted backend for development can be problematic since your dev environment is now externally dependent. For example:
- If external APIs are not available, it can be difficult to get anything done downstream. This usually happens during initial feature development or when adding new API endpoints. Workarounds almost always resort to some sort of mocking or hardcoding.
- Your ability to work is dependent on the availability and stability of your backend. There is very little that downstream teams can do if there is an outage or an API stops working the way it’s supposed to. Depending on the severity, the only plan may be to wait it out.
As far as our time spent blocked is concerned, the costs are pretty simple. We don’t have the recurring maintenance costs of the mock server workflow, but we spend time either being blocked or unblocking ourselves whenever a backend service is unavailable.
Finding middle ground
There are definite trade-offs between the two workflows. Is there a path down the middle where we get both flexibility and maintainability?
This was a question that our team needed to answer at Confluent. When we began work on the Confluent Cloud UI in late 2017, we went with a mock server for feature development. At this time, our engineering organization was figuring out how to improve stability and release speed, which meant we couldn’t always rely on having a stable or up-to-date development environment. Because of this, our mock server approach was necessary and effective at first.
Soon though, we shifted from using our API mocks to building against our dev environment. By early 2019, our stability and release cadence had greatly improved. There was little incentive to maintain our mock server on a day-to-day basis, so it gradually became outdated.
This was a problem when it came time to work on large features or complicated API version upgrades. Each time, we would roll up our sleeves and perform the tedious task of updating the mock server. Frequently, this involved maintaining mocks for APIs that weren’t at all related to the project in question. Once updated, the mock server would again start accumulating dust until the next cleaning was required.
As our application expanded from a few endpoints to a few dozen, the cost of maintaining the mocks became prohibitive. It was simply too time consuming to keep the mock server up to date, at all times, across API versions. Our team’s velocity was being dragged down by the overhead cost of our never-ending game of mock server hot potato.
The hybrid solution
To address this, we formed an intermediate strategy that uses both mock APIs and our dev backend. We lean on our live API for stable features while leveraging the flexibility of mocks as needed. Our local frontend sends most of its API requests to our cloud but is served mocks as needed. It looks something like this: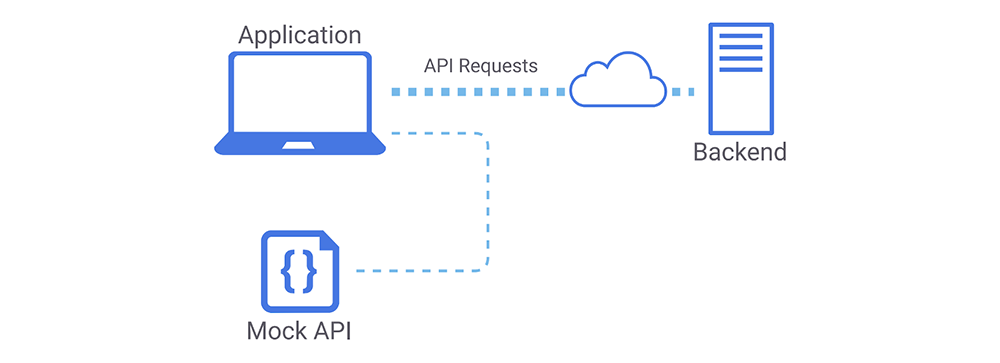
Most API requests go to the backend, while others are served mocks.
The concept of extending real behavior with mocked behavior is probably already familiar. It’s a common theme in software engineering, and it’s the same principle behind hardcoding a return statement somewhere in your code and letting the program run to see what happens.
For my team, this strategy means that we don’t need to write or update mocks unless they are directly involved in the feature being developed. We are empowered to unblock ourselves against external API dependencies and only spend time doing so when truly necessary.
So, this is our high-level strategy, but it turns out we have a number of logistical questions to answer. How do we actually get this to work in practice?
Shopping for options
There are a number of ways we can support a dual mock and backend workflow. The right approach for each team depends on its development process and workflow. Here are some options we found:
- You might already use webpack-dev-server and its configurable proxying feature. It allows you to specify which API routes should be routed to where. At Confluent, this was our initial approach for isolating which endpoints should be mocked and which should be proxied.
- Some mock server frameworks support simultaneous proxying and mocking. One example is mockserver, a popular open source project, which includes MockServer Proxy.
- For a serverless approach, there’s Interceptor, which is a browser extension that lets you mock API responses in the browser.
- For GraphQL, GraphQL Faker is another popular open source project.
- You can also mock your responses directly within your application. This typically involves hardcoding response values at or above your application’s network middleware. This quick and dirty tactic gets the job done, but it can oversimplify and hide factors like request latency, response headers, and network errors.
In addition to the above, there’s another option:
- Do it yourself
Software engineers often joke about not invented here syndrome. In spite of this, we ended up building our own solution at Confluent. We felt the existing tools either weren’t flexible enough to fit our workflow or weren’t usable enough out of the box. After some experimentation and iteration, we created Mox.
Mocking à la carte with Mox
Mox is a lightweight request interception library that wraps around Express. It acts like a proxy server that can be extended with mocked API endpoints. By default, Mox proxies incoming API requests to your real backend. However, you can specify endpoints to mock or modify.
Here’s a shortlist of features:
- Request introspection: programmatically modify request or response payloads
- Proxy to multiple backends
- Set headers and status codes
- Simulate delays
- Generate SSL certificates if needed
Mox combines the pattern-based routing of Express with a chainable interface that covers common developer use cases. By sitting between your local frontend and your backend service, Mox allows you to specify what requests pass through, where they are passed to, and how they are modified or mocked.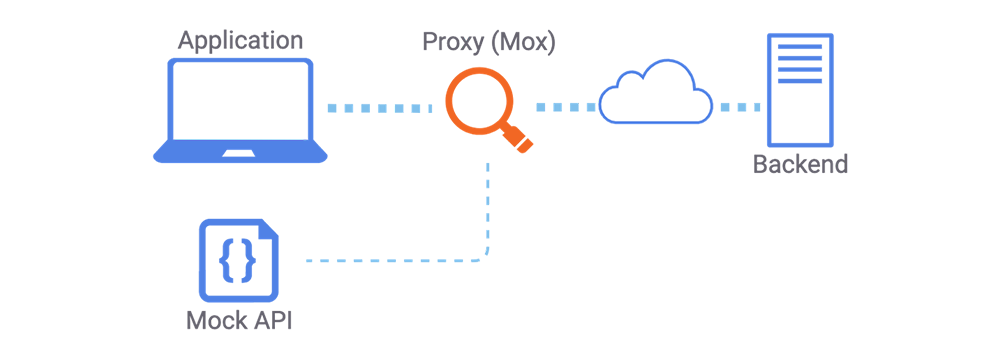
Mox inspects requests and can reroute them or modify their responses.
Here’s a look at what it takes to configure the server, perform a simple mock, and get it running:
import { MoxServer } from '@confluentinc/mox';
const server = new MoxServer({ targetUrl: 'https://dev.server', listenPort: 3005 });
const router = server.getRouter();
router.get('/api/route-to-mock').mock({ foo: 'bar' });
router.start();
In this example, any GET request matching /api/route-to-mock will receive a response with the supplied mock value, and all other requests will get proxied through to https://dev.server. Mocks can be defined inline as shown above, but if you already have a mock server available, you can tell Mox to redirect requests there.
router.all('/api/new-feature/*').setBase('http://localhost:8000'); // url of mock server
Mox’s most obvious use case is unblocking new feature development. This was our main goal when we started working with it as well. As time went on though, we discovered that Mox’s ability to intercept network requests had a number of other applications.
Request interception use cases
Reproducing bugs
When investigating a bug, you sometimes have access to an API response that triggers it. In these situations, Mox can consistently reproduce that behavior.
const response = { foo: ‘bar’ }; /* or whatever you copy-pasted */
router.get('/api/feature).mock(response);
Partial response mocking
Sometimes, you just want to change a part of a response payload without having to mock the entire thing. This can happen when a queried resource contains fields that might be difficult to manipulate organically.
router.get('/api/metrics/:id').mutate(resp => {
resp.data_throughput = 4.2e10;
return resp;
});
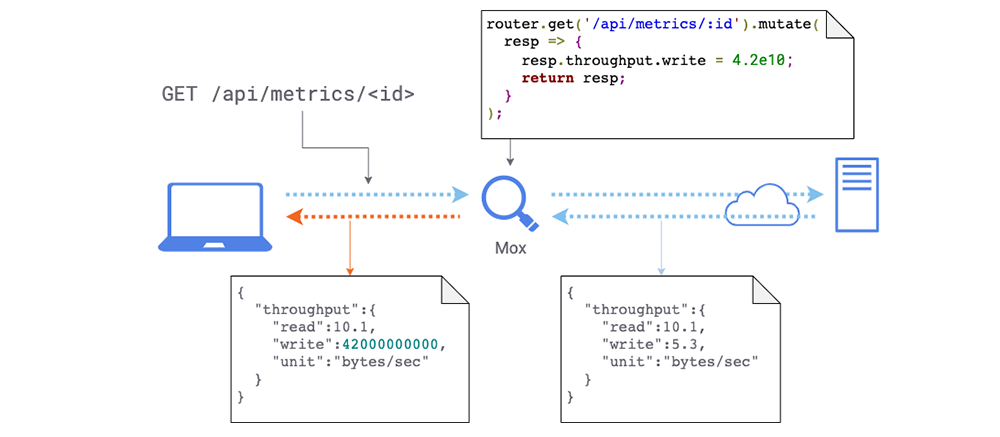
Mox can change the response payload in flight.
This is especially helpful when working with APIs that contain dense or complex payloads but only require a small part of the response behavior to be modified. Instead of recreating the entire payload, just change the part that matters!
Simulating network latency
Development, staging, and production environments can vary in their timing characteristics. With Mox, you can simulate lag for different endpoints and see how the UI responds.
router.all('/api/slow-service/*').delay(1000);
Simulating large responses
It’s sometimes useful to load test your UI to see how well it handles large responses. For example, you might have an API that returns a list of resources that you want to render, and you want to see how the UI responds to a large list. It’s easy to manipulate that API with Mox.
router.get('/api/items').mutate(itemArray => {
return [...itemArray, Array(100).fill(itemArray[0])];
});
For more examples and full documentation, you can visit GitHub.
Moving faster with partial API mocks
Let’s revisit our key metric from before. The blocked factor consists of time spent in the following situations:
- Waiting for external API dependencies
- Working to unblock ourselves on those dependencies
How does setting up our workflow with a hybrid approach help us avoid these? To start with, we write mock APIs to unblock ourselves when we don’t have real ones available. Once a service goes live, we don’t need the mocks anymore, and thus we don’t spend time maintaining them.
Of course, backend interfaces can still change, requiring fixes to the frontend codebase. Doesn’t this mean we need to maintain our API mocks anyway? The answer is sometimes, but not always. Keep in mind:
- Ideally, new API versions are backward compatible, and iteration on new versions is typically faster than initial feature development. Downstream teams can just work against the updated endpoints once they are ready.
- In situations where this isn’t the case, such as when an API undergoes a breaking change, the new endpoints can sometimes be mocked in place (see partial response mocking).
The hybrid mocking strategy doesn’t fix everything, but overall, it cuts down a lot of time spent working on or maintaining mock APIs.
Picking the right tooling for you
There are many ways to implement the hybrid approach, but the best option depends on your team’s workflow and situation. With the right development strategy, you can have control over where and how you use mock APIs within your workflow. The flexibility-usability tradeoff doesn’t imply that you must stick to one extreme or the other—it just means that you don’t get both sides for free. With the right tooling though, you get to choose where to spend effort and where not to, for every API that you depend on.
If you think Mox might be of help in your workflow, try it out! It’s easy to set up hybrid API proxying, and it comes with other powerful abilities including request interception.
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...