[Webinar] AI-Powered Innovation with Confluent & Microsoft Azure | Register Now
How to Run Apache Kafka with Spring Boot on Pivotal Application Service (PAS)
This tutorial describes how to set up a sample Spring Boot application in Pivotal Application Service (PAS), which consumes and produces events to an Apache Kafka® cluster running in Pivotal Container Service (PKS). With this tutorial, you can set up your PAS and PKS configurations so that they work with Kafka.
For a tutorial on how to set up a Kafka cluster in PKS, please see How to Deploy Confluent Platform on Pivotal Container Service (PKS) with Confluent Operator.
If you’d like more background on working with Kafka from Spring Boot, you can also check out How to Work with Apache Kafka in your Spring Boot Application.
Methodology
Starting with the requirements, this tutorial will then go through the specific tasks required to connect PAS applications to Kafka. The sample Spring Boot app is pre-configured to make the setup steps as streamlined as possible.
You’ll review the configuration settings that streamline the deployment so you know what to change for your environment. Afterward, the tutorial will run through some ways to verify your PAS app to Kafka in your PKS setup.
Requirements
- Run a Kafka cluster in Enterprise PKS. To set up Kafka in PKS via Confluent Operator and expose external endpoints, you can refer to part 1.
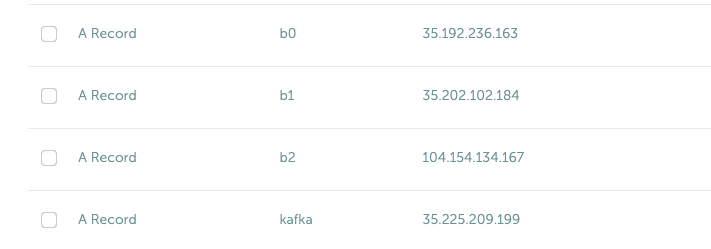
- Especially note the exposing external endpoints and proper DNS setup explained in part 1. External endpoint exposure with public DNS is required for this tutorial. Here’s a screenshot of my DNS setup for the domain name used in part 1.
 The /etc/hosts trick mentioned in part 1 will not work now because we don’t have access to the hosts file in PAS containers. Therefore, we need our Spring Boot app to be able to resolve DNS to our Kafka cluster running in PKS.
The /etc/hosts trick mentioned in part 1 will not work now because we don’t have access to the hosts file in PAS containers. Therefore, we need our Spring Boot app to be able to resolve DNS to our Kafka cluster running in PKS.
- Especially note the exposing external endpoints and proper DNS setup explained in part 1. External endpoint exposure with public DNS is required for this tutorial. Here’s a screenshot of my DNS setup for the domain name used in part 1.
- Running and accessible Confluent Schema Registry, which was mentioned in part 1, in PKS.
- Install Maven. (Note: familiarity with Git and building Java applications with Maven is presumed.)
- Access the springboot-kafka-avro repo.
- Install the Cloud Foundry (cf) CLI.
- Your PAS environment username, password, and fully qualified domain name (FQDN). At the time of this writing, you can obtain a PAS environment if you sign up for a free Pivotal Web Services account.
Cloud Foundry (cf) CLI prerequisites
If this is your first time deploying an application to PAS, you’ll need to do the following in order to perform the later steps. If you have already set up your PAS environment or are familiar with PAS, feel free to adjust accordingly.
Performing the following steps will create a ~/.cf/config.json file if you don’t have one created already.
- Log in with cf l -a <my-env> -u <my-username> -p <my-password>.
- Exit and execute the commands below. Substitute <my-*> with settings that are appropriate for your PAS environment. For example, based on my Pivotal Web Services account setup, I used api.run.pivotal.io for the <my-env>:
-
- cf create-org confluent
- cf target -o confluent
- cf create-space dev
- cf target -s dev
The commands in step 2 are optional depending on you how like to keep things organized. In any case, you should be all set at this point with a ~/.cf/config.json file and may proceed to setting up the sample PAS app with Kafka in PKS.
For more details on the cf CLI, see the documentation.
Deploy a Sample Spring Boot Microservice App with Kafka to Pivotal Application Service (PAS)
Run all command line tasks in a terminal unless explicitly stated otherwise.
- Clone springboot-kafka-avro and enter the directory. For example:
git clone https://github.com/confluentinc/springboot-kafka-avro && cd springboot-kafka-avro.
- Create a Pivotal user-provider service instance (UPSI) with the following command:
cf create-user-provided-service cp -p '{"brokers":"kafka.supergloo.com:9092","jaasconfig":"org.apache.kafka.common.security.plain.PlainLoginModule required username='test' password='test123',"sr": "http://schemaregistry.supergloo.com:8081";"}'This UPSI delivers dynamic configuration values to our sample application upon startup. UPSI is an example of the aforementioned PAS-specific requirements. The username and password values of test and test123 used above were the defaults used in the Helm Chart from part 1. These settings might depend on your environment so adjust accordingly.
- Also, note the brokers and sr variable settings and their related brokers and sr variable values in the src/main/resources/application-pass.yaml file. Again, these settings are defaults from part 1, so you may need to adjust for your environment. I’ll explain it in more detail later on, but for now, focus on getting your example running.
- Push the sample Spring Boot microservice app to PAS with:
mvn clean package -DskipTests=true && cf push --no-start
Notice how the --no-start option is sent, as the previously created UPSI service has not yet been bound and attempting to start the application would result in failure.
You should see something similar to the following. Pay attention to the routes output which you’ll need in later steps. In the following example, my routes output was spring-kafka-avro-fluent-hyrax.cfapps.io, but yours will look different.
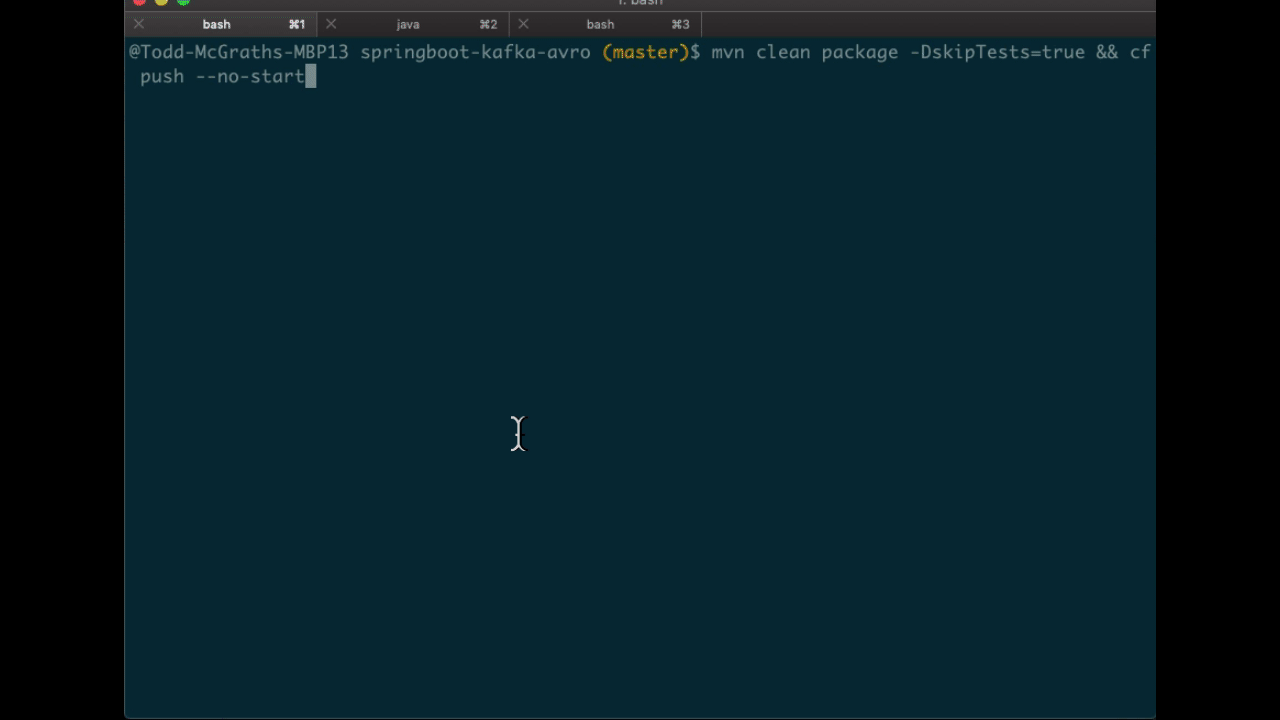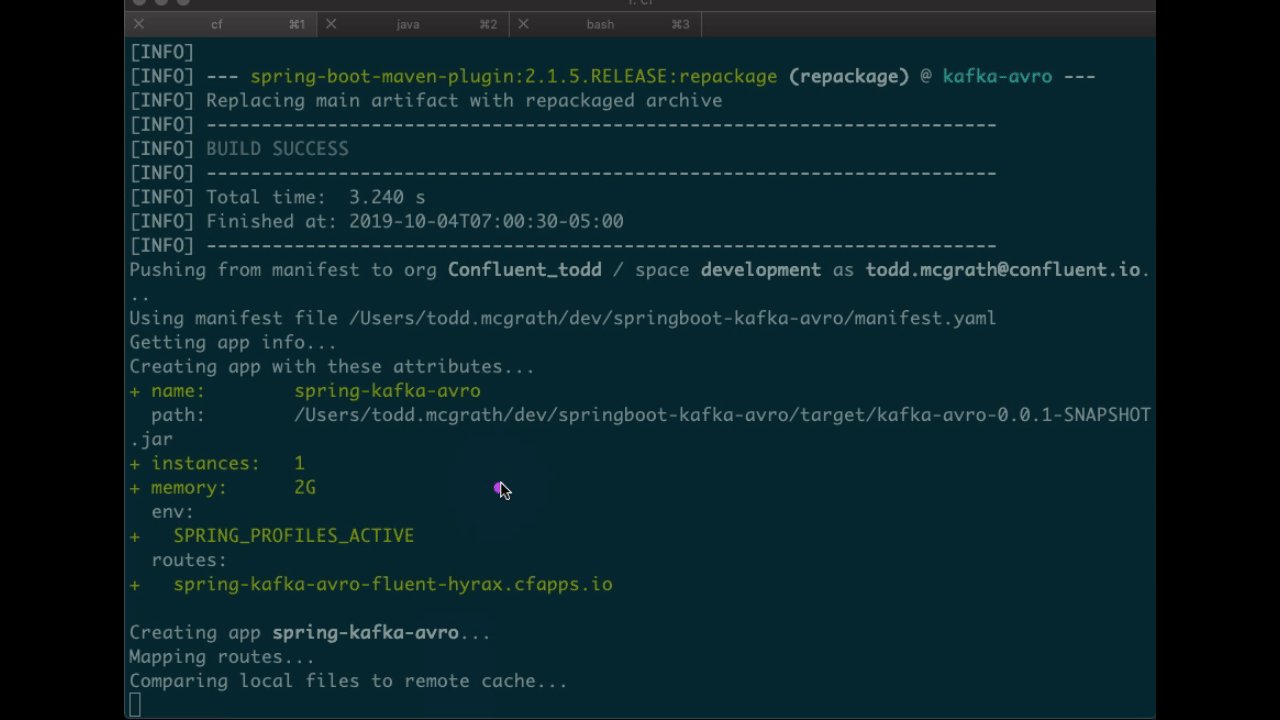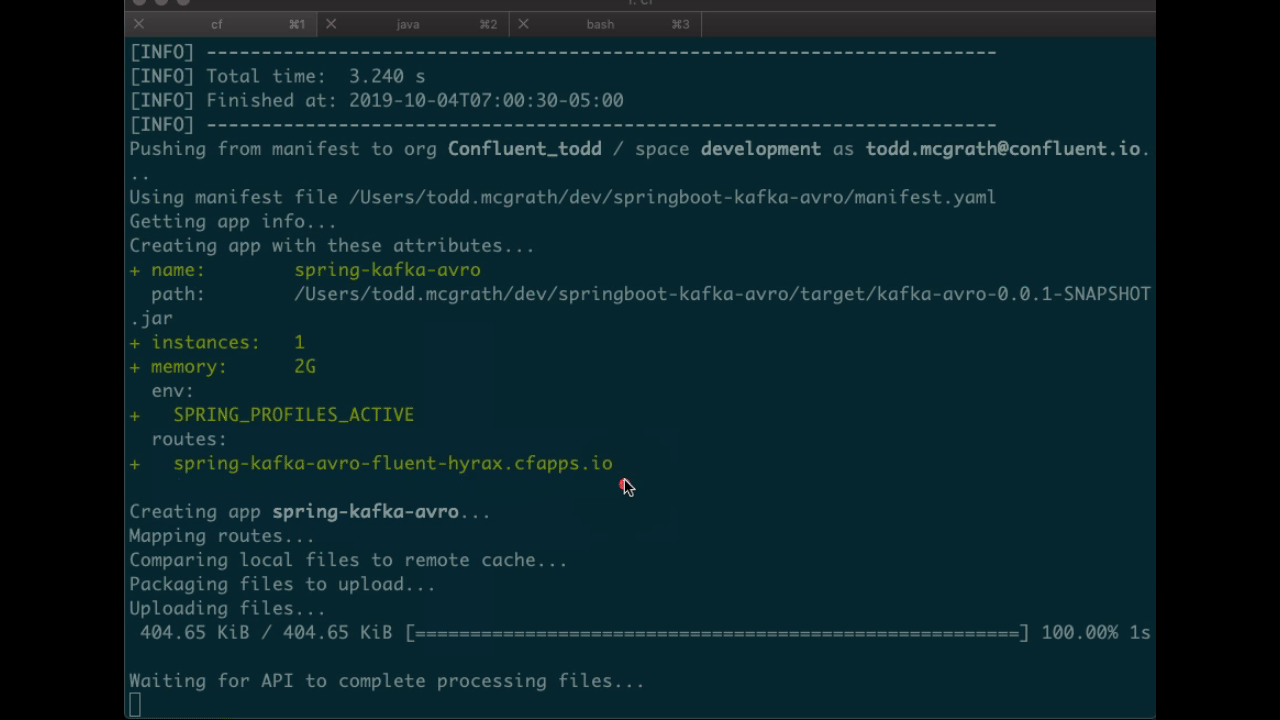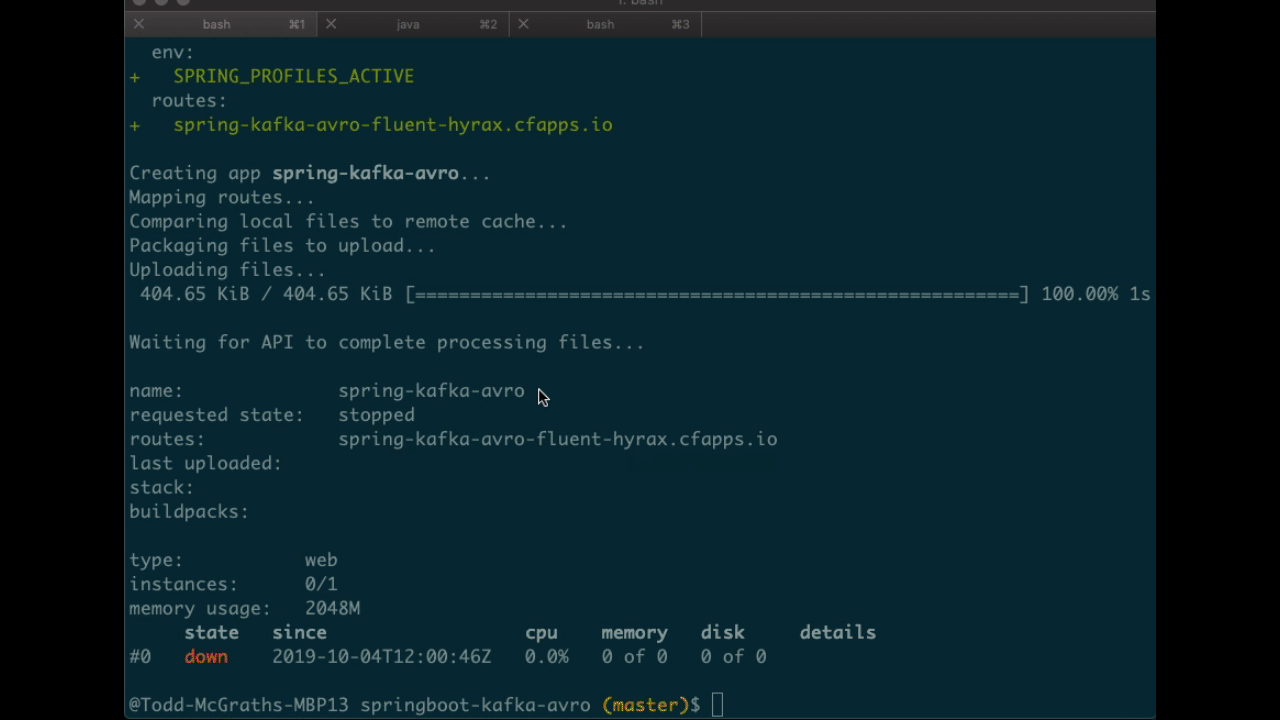
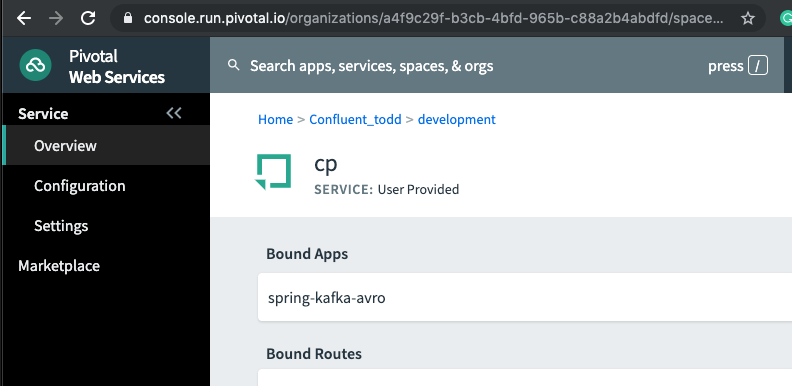
- Next, as you probably already guessed, perform the binding: cf bind-service spring-kafka-avro cp.This command binds the cp service to the spring-kafka-avro app that was deployed earlier. You should see something similar to the following in the Pivotal console under your cp service settings:
- Then perform cf start spring-kafka-avro. After about 30 seconds, the spring-kafka-avro state should be running.

At this point, your setup is complete. Now, you are ready to verify the installation is successful.
Verification
- Determine the external URL of your newly deployed app with cf apps. Look to the urls column. As previously noted, mine is spring-kafka-avro-fluent-hyrax.cfapps.io.
- The sample app code shows one available REST endpoint in KafkaController.java. You can post to this endpoint with different age and name parameters such as:
curl -X POST -d 'name=vik&age=33' spring-kafka-avro-fluent-hyrax.cfapps.io/user/publish
Or, change up the name and age values:
curl -X POST -d 'name=todd&age=22' spring-kafka-avro-fluent-hyrax.cfapps.io/user/publish
Or, to flex your Schema Registry integration, notice what happens when you attempt to send values that are not appropriate for the user schema (see src/main/avro/user.avsc):
curl -X POST -d 'name=todd&age=much_younger_than_vik_gotogym' spring-kafka-avro-fluent-hyrax.cfapps.io/user/publish
- Check out any topics created by the sample app with bin/kafka-topics --list --command-config kafka.properties --bootstrap-server kafka.supergloo.com:9092. (As shown, you need access to both the kafka-topics script and a kafka.properties file which was described in the section from part 1 on external validation.)
- If you wish, you can consume the users topic via a command similar to:
kafka-avro-console-consumer --bootstrap-server kafka.supergloo.com:9092 --consumer.config kafka.properties --topic users --from-beginning --property schema.registry.url=http://schemaregistry.supergloo.com:8081
Noteworthy configuration and source code
Now that you’ve verified your app is up and running and communicating with Kafka (and Schema Registry), let’s examine the configuration and source code by breaking down the setup steps above.
How does your PAS app know which Kafka cluster to use and how to authorize? How does the app know which Schema Registry to use?
First, look to the manifest.yaml file for the env stanza setting of SPRING_PROFILES_ACTIVE: paas.
This will force Spring Boot to reference the src/main/resources/application-pass.yaml for environment configuration settings. In application-pass.yaml, the values for brokers, sr, and jaasconfig appear to be dynamically set, e.g., ${vcap.services.cp.credentials.brokers}. So if you’re thinking there must be string interpolation action happening somehow, I say loudly, “You are correct!” (That was my poor attempt of a Phil Hartman impersonation by the way). The interpolation magic happens on app startup via the UPSI that we created and used to bind our app in step 2 above.
But why does your POST attempt fail when you send an age value that isn’t a number? How/where this is set in the Java code is not visible.
This is due to the schema.registry.url property setting in application-paas.yaml. For more information on Schema Registry, check out How to Use Schema Registry and Avro in Spring Boot Applications.
Tutorial completed ✅
This tutorial covered how to deploy a Spring Boot microservice app to PAS that produces and consumes from a Kafka cluster running in Pivotal PKS.
And finally, from the “credit-where-credit-is-due” department, much thanks to Sridhar Vennela from Pivotal for his support. I’d also like to thank Viktor Gamov, my colleague at Confluent, for developing the sample application used in this tutorial, and Victoria Yu as well for making me appear more precise and interesting than I usually am.
More tutorials, please!
For more, check out Kafka Tutorials and find full code examples using Kafka, Kafka Streams, and ksqlDB.
To get started with Spring using a more complete distribution of Apache Kafka, you can sign up for Confluent Cloud and use the promo code SPRING200 for an additional $200 of free Confluent Cloud usage.
If you haven’t already, be sure to read part 1 of this series to learn how to deploy Confluent Platform on Pivotal Container Service with Confluent Operator.
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Guide to Consumer Offsets: Manual Control, Challenges, and the Innovations of KIP-1094
The guide covers Kafka consumer offsets, the challenges with manual control, and the improvements introduced by KIP-1094. Key enhancements include tracking the next offset and leader epoch accurately. This ensures consistent data processing, better reliability, and performance.



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…