[Virtuelles Event] GenAI Streamposium: Lerne, Echtzeit-GenAI-Apps zu entwickeln und zu skalieren | Jetzt registrieren
Apache Kafka on Kubernetes – Could You? Should You?
When Confluent launched the Helm Charts and early access program for Confluent Operator, we published a blog post explaining how to easily run Apache Kafka® on Kubernetes. Since then, we’ve heard from quite a few members of the community question whether running Kafka on Kubernetes is actually a good idea.
For example, my friend Dylan works for an insurance company and wondered, “…Kubernetes and Kafka are complex distributed systems…I know that Confluent has the expertise to do the management of it; however, what do you think of a normal enterprise dealing with it? Or in other words, just because one could, does that mean we really should?”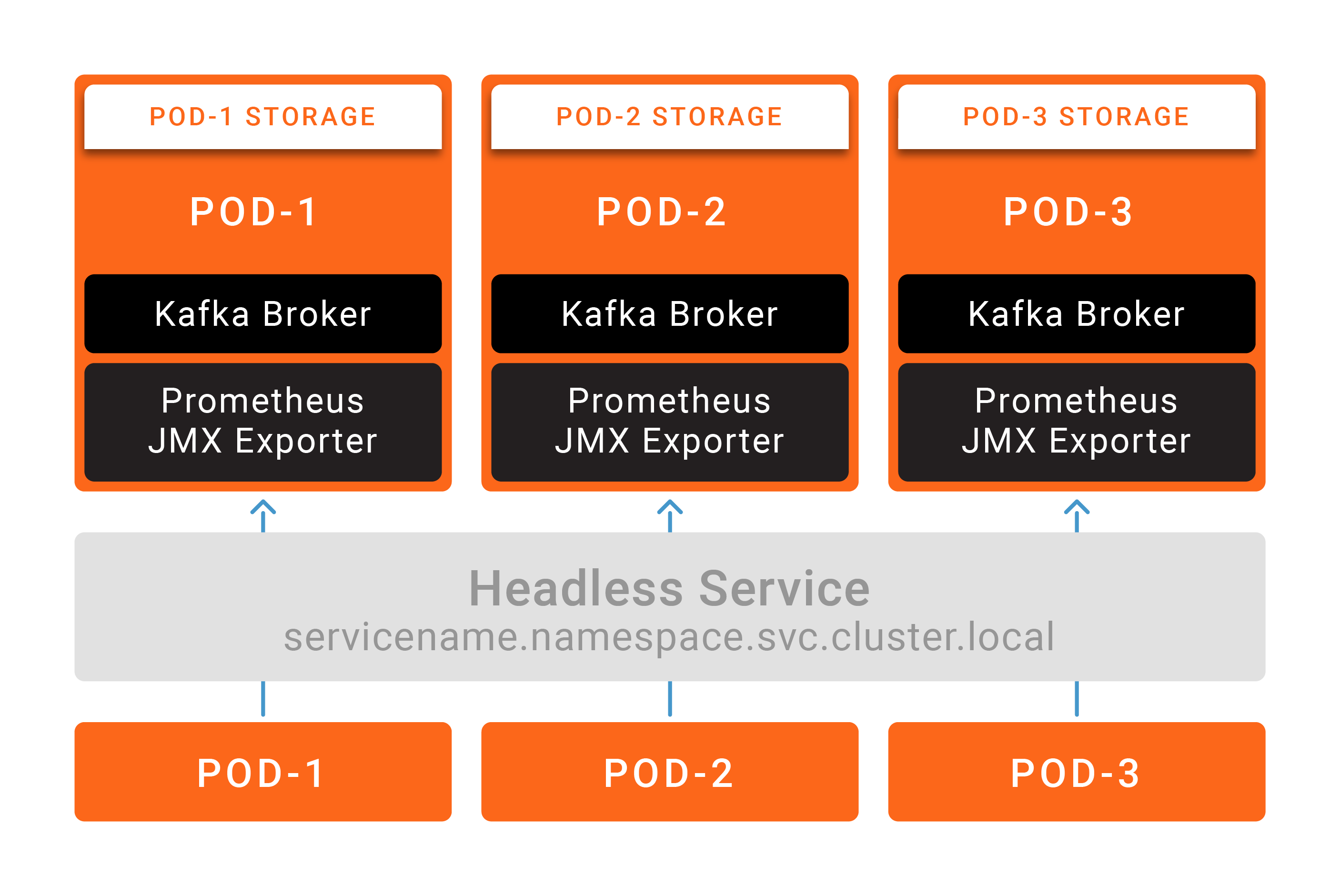 I completely agree with Dylan that you need to evaluate every technology for fit within both your overall architecture, and the skill set and culture of the organization. Not everything that works in a small Silicon Valley startup will work for a large traditional enterprise.
I completely agree with Dylan that you need to evaluate every technology for fit within both your overall architecture, and the skill set and culture of the organization. Not everything that works in a small Silicon Valley startup will work for a large traditional enterprise.
With that in mind, there are actual good reasons for running Kafka on Kubernetes within a traditional enterprise company.
Why run Kafka on Kubernetes?
First, if you are running most of your other applications and microservices on Kubernetes, it becomes the organizational path of least resistance. This is just like how organizations who standardized on VMs have found it very difficult to allocate physical machines with local disks for Kafka.
I see situations with larger organizations where deploying Kafka outside of Kubernetes causes significant organizational headache that involves many approvals. When this is the case, I usually say that this isn’t a good hill to die on. It is possible to run Kafka on Kubernetes, so just do it. You’ll get your environment allocated faster and will be able to use your time to do productive work rather than fight an organizational battle.
And if things go wrong, you’ll get much better service from your internal infrastructure teams, because you’ll be running in an environment that is familiar to them.
Second, most orgs underestimate how many Kafka clusters they will end up deploying. As the number of use cases grow, you end up with multiple production clusters. And of course there are development environments, testing environments, trying-out-a-new-version environments, blue-green deployment environments and so on.
Kubernetes, especially with Confluent Operator, does make it easier to deploy and manage new clusters. You could use other deployment tools like Confluent’s Ansible scripts, but they don’t have the built-in provisions for scaling out, monitoring, restarts, upgrades, etc.
Once you get used to Kubernetes (and it does not take long), you’ll see that Kafka management becomes much easier. It becomes easier to scale up—adding new brokers is a single command or a single line in a configuration file. And it is easier to perform configuration changes, upgrades and restarts on all brokers and all clusters.
Kafka on Kubernetes can be challenging
Kafka is a stateful service, and this does make the Kubernetes configuration more complex than it is for stateless microservices. The biggest challenges will happen when configuring storage and network, and you’ll want to make sure both subsystems deliver consistent low latency.
Kafka on Kubernetes, and other stateful services, require the use of shared storage. Support for local persistent storage on Kubernetes is still in beta and not recommended for production, though now may be a good time to start testing it on a pilot project, as it will likely become GA in few months.
Unfortunately, many organizations still can’t deliver consistent low latency on their shared storage device. If you want to run Kafka successfully on Kubernetes, you need to make sure the storage team understands the requirements and that together you validate that they are met.
Kafka also poses a challenge that most stateful services don’t: Brokers are not interchangeable, and clients will need to communicate directly with the broker that contains the lead replica of each partition they produce to or consume from. You can’t place all brokers behind a single load balancer address. You need a way to route messages to specific brokers.
This isn’t particularly difficult. In the Recommendations for Deploying Apache Kafka on Kubernetes paper, we explained the available options and their tradeoffs. In most cases, the process will require cooperation from the network team.
The main lesson here is that you can run Kafka on Kubernetes successfully if, and only if, you have the cooperation of skilled storage and network teams. If you don’t have those, you will run into trouble. But the same has always been true—Kafka depends on good infrastructure, and customers who lack good corporate infrastructure run into issues no matter what.
In addition, I’d recommend against choosing Kafka as the first service to run on Kubernetes. Let the infrastructure team gain experience in deploying, monitoring, updating and troubleshooting stateless services first, such as Kafka Streams applications.
As mentioned earlier, any single app on Kubernetes doesn’t bring you much benefits. Kubernetes really shines when you use it to manage all your applications and infrastructure. Running Kafka brokers on Kubernetes is most beneficial if the line of business applications are running on Kubernetes too.
Now some engineers look at the fact that you need to configure persistent volumes on shared storage and headless services with load balancer policies, and see these as “workarounds” and an indication that StatefulSets on Kubernetes are not quite mature yet. I don’t see things this way. In my view, Kafka has specific requirements, and Kubernetes delivers the mechanisms to support Kafka. With version 1.9, StatefulSets are a first-class citizen in the Kubernetes ecosystem.
Conclusion
If you use tools like Helm Charts for provisioning and Confluent Operator to make running Kafka on Kubernetes easy, and if you have the support of the storage and network teams, Kafka on Kubernetes is quite easy—in my opinion, easier than any other way of running Kafka.
You can get started with Kafka on Kubernetes today by checking out the white papers and Helm Charts available online. With Confluent Operator, we are productizing years of Kafka experience with Kubernetes expertise to offer you the best way of using Apache Kafka on Kubernetes.
Let us know if you are interested, and we may invite you to join our beta program.
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...