[Virtuelles Event] GenAI Streamposium: Lerne, Echtzeit-GenAI-Apps zu entwickeln und zu skalieren | Jetzt registrieren
Real-Time Analytics and Monitoring Dashboards with Apache Kafka and Rockset
In the early days, many companies simply used Apache Kafka® for data ingestion into Hadoop or another data lake. However, Apache Kafka is more than just messaging. The significant difference today is that companies use Apache Kafka as an event streaming platform for building mission-critical infrastructures and core operations platforms. Examples include microservice architectures, mainframe integration, instant payment, fraud detection, sensor analytics, real-time monitoring, and many more—driven by business value, which should always be a key driver from the start of each new Kafka project: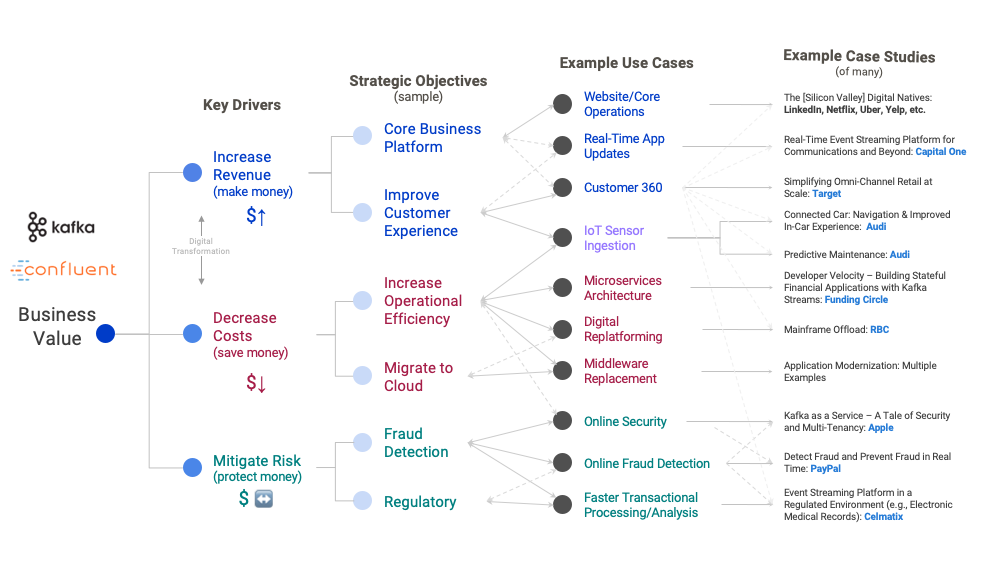
Access to massive volumes of event streaming data through Kafka has sparked strong interest in interactive, real-time dashboards and analytics, with the idea being similar to what was built on top of batch frameworks like Hadoop in the past using Impala, Presto, or BigQuery: the user wants to ask questions and get answers quickly.
In the most critical use cases, every seconds counts. Batch processing and reports after minutes or even hours is not sufficient. Leveraging Rockset, a scalable SQL search and analytics engine based on RocksDB, and in conjunction with BI and analytics tools, we’ll examine a solution that performs interactive, real-time analytics on top of Apache Kafka and also show a live monitoring dashboard example with Redash. Rockset supports JDBC and integrates with other SQL dashboards like Tableau, Grafana, and Apache Superset. Some Kafka and Rockset users have also built real-time e-commerce applications, for example, using Rockset’s Java, Node.js®, Go, and Python SDKs where an application can use SQL to query raw data coming from Kafka through an API (but that is a topic for another blog).
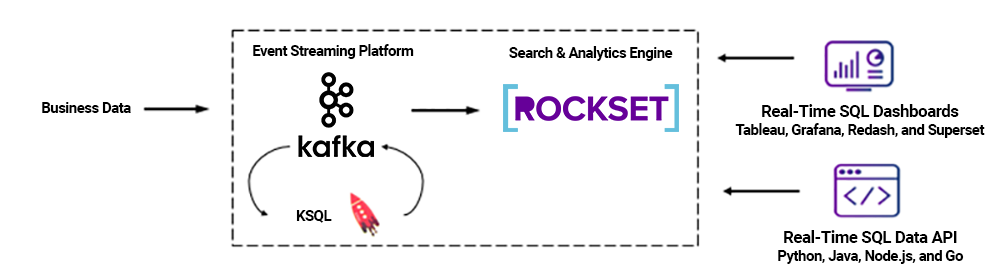
Let’s now dig a little bit deeper into Kafka and Rockset for a concrete example of how to enable real-time interactive queries on large datasets, starting with Kafka.
Apache Kafka as an event streaming platform for real-time analytics
Apache Kafka is an event streaming platform that combines messages, storage, and data processing. The Apache Kafka project includes two additional components: Kafka Connect for integration and Kafka Streams for stream processing. Kafka’s ecosystem also includes other valuable components, which are used in most mission-critical projects. Among these are Confluent Schema Registry, which ensures the right message structure, and ksqlDB for continuous stream processing on data streams, such as filtering, transformations, and aggregations using simple SQL commands.
Kafka often acts as the core foundation of a modern integration layer. The article Apache Kafka vs. Enterprise Service Bus (ESB) – Friends, Enemies or Frenemies? explains in more detail why many new integration architectures leverage Apache Kafka instead of legacy tools like RabbitMQ, ETL, and ESB.
Not only can Kafka be used for both real-time and batch applications, but it can also integrate with non-event-streaming communication paradigms like files, REST, and JDBC. In addition, it is often used for smaller datasets (e.g., bank transactions) to ensure reliable messaging and processing with high availability, exactly once semantics, and zero data loss.
Kafka Connect is a core component in event streaming architecture. It enables easy, scalable, and reliable integration with all sources and sinks, as can seen through real-time Twitter feeds in our upcoming example. What if mainframes, databases, logs, or sensor data are involved in your use case? The ingested data is stored in a Kafka topic. Kafka Connect acts as sink to consume the data in real time and ingest it into Rockset.
Regardless of whether your data is coming from edge devices, on-premises datacenters, or cloud applications, you can integrate them with a self-managed Kafka cluster or with Confluent Cloud (https://www.confluent.io/confluent-cloud), which provides serverless Kafka, mission-critical SLAs, consumption-based pricing, and zero efforts on your part to manage the cluster.
Complementary to the Kafka ecosystem and Confluent Platform is Rockset, which likewise serves as a great fit for interactive analysis of event streaming data.
Overview of Rockset technology
Rockset is a serverless search and analytics engine that can continuously ingest data streams from Kafka without the need for a fixed schema and serve fast SQL queries on that data. The Rockset Kafka Connector is a Confluent-verified Gold Kafka connector sink plugin that takes every event in the topics being watched and sends it to a collection of documents in Rockset. Users can then build real-time dashboards or data APIs on top of the data in Rockset.
Rockset employs converged indexing, where every document is indexed multiple ways in document, search, and columnar indexes, to provide low-latency queries for real-time analytics. This use of indexing to speed performance is akin to the approach taken by search engines, like Elasticsearch, except that users can query Rockset using standard SQL and do joins across different datasets. Other SQL engines, like Presto and Impala, are optimized for high throughput more so than low latency and rely less on indexing.
Rockset is designed to take full advantage of cloud elasticity for distributed query processing, which ensures reliable performance at scale without managing shards or servers. You can either do interactive queries using SQL in your user interface or command line, or provide developers with real-time data APIs for building applications to automate the queries.
Real-time decision-making and live dashboards using Kafka and Rockset
Let’s walk through a step-by-step example for creating a real-time monitoring dashboard on a Twitter JSON feed in Kafka, without going through any ETL to schematize the data upfront. Because Rockset continuously syncs data from Kafka, new tweets can show up in the real-time dashboard in a matter of seconds, giving users an up-to-date view of what’s going on in Twitter. While Twitter is nice for demos (and some real use cases), you can, of course, integrate with any other event streaming data from your business applications the same way.
Connecting Kafka to Rockset
To connect Kafka to Rockset, use the Rockset Kafka Connector available on Confluent Hub, and follow the setup instructions in the documentation.
Next, create a new integration to allow the Kafka Connect plugin to forward documents for specific Kafka topics. You can do so by specifying Kafka as the integration type in the Rockset console.
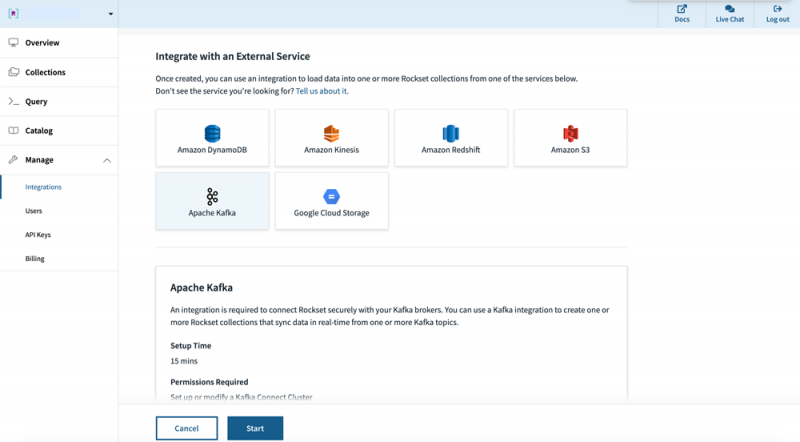
Figure 1. Click to create a new Apache Kafka integration.
Select the data format and add the names of topics you wish to forward to Rockset from Kafka Connect. Once you create the integration, you will be presented with configuration options to be used with Kafka Connect for forwarding the Twitter data to Rockset.
Creating a collection from a Kafka data source
To complete your setup, create a new collection to ingest documents from the Kafka Twitter stream, using the integration you previously set up. If you are only interested in tweets from the past few months, you can configure a retention policy that drops documents from the collection after “n” days or months.
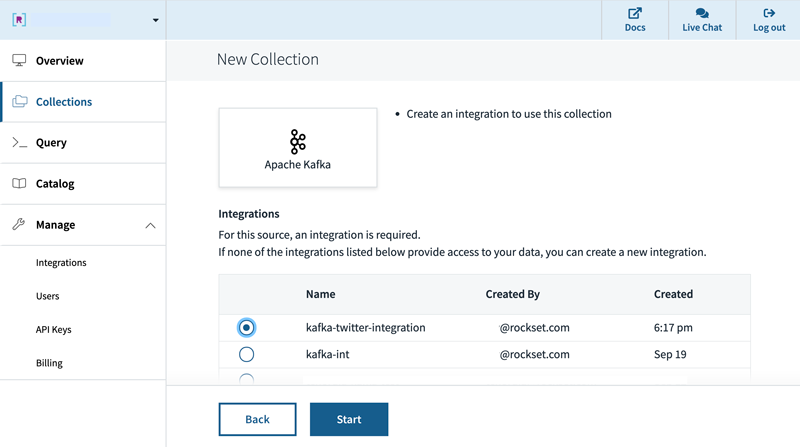
Figure 2. Select Apache Kafka as the data source for the new collection, using the previously created integration.
Querying Twitter Data from Kafka
With Kafka data flowing into your Rockset collection, you can run a query to better understand the content of the Twitter feed. The JSON from the Twitter feed shows multiple levels of nesting and arrays, and even though you didn’t perform any data transformation, you can run SQL directly on the raw Twitter stream.
If you are particularly interested in the subset of tweets that contain stock symbols (sometimes referred to as cashtags), you can write a SQL query to find those tweets and unnest the JSON array where the stock symbols are specified.
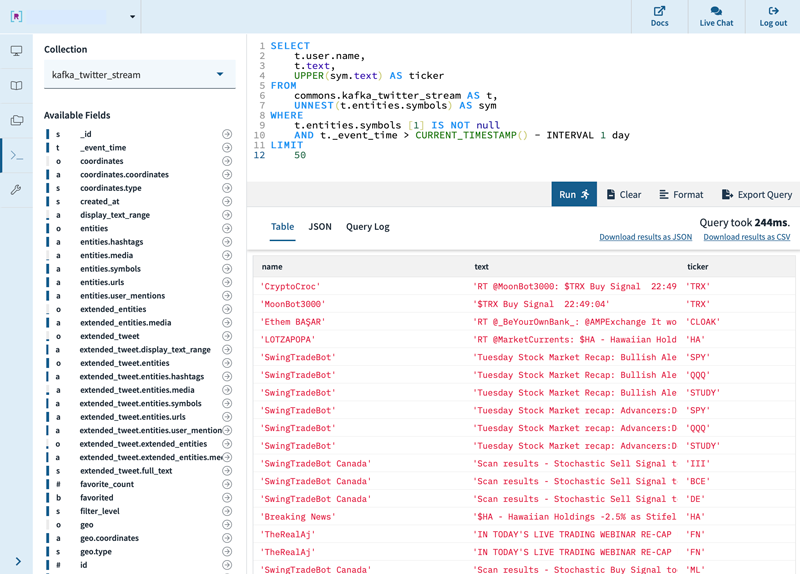
Figure 3. Find a sample of stock symbols in the Twitter feed.
Joining with other datasets
If you want to match the stock symbols with actual company information (e.g., company name and market cap), you can join your collection from the Kafka Twitter stream with more detailed company information from Nasdaq. Here, your query returns the stocks with the most mentions in the past day.
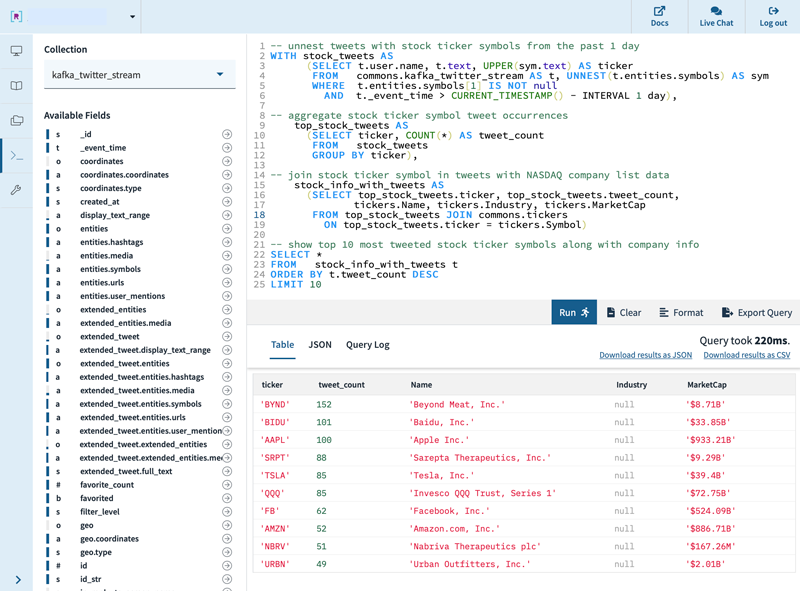
Figure 4. Find the most mentioned stocks in the past day, along with more detailed company information.
Generating a real-time monitoring dashboard on Kafka data
Now that you have joined the Kafka stream with stock market data and made it queryable using SQL, connect Rockset to Redash. Note that Rockset supports other dashboarding tools as well, including Grafana, Superset, and Tableau via JDBC. Aside from standard visualization tools, you also have the option to build custom dashboards and applications using SQL SDKs for Python, Java, Node.js, and Go.
Now, let’s generate a real-time monitoring dashboard on the incoming tweets, in which the dashboard is populated with the latest tweets whenever it is refreshed.
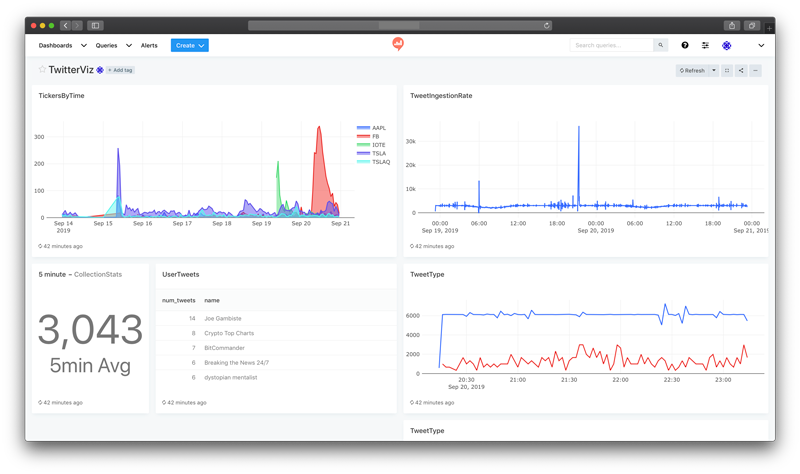
Figure 5. A live dashboard for monitoring spikes in stock symbol mentions in the Twitter stream.
By plugging Kafka into Rockset, you were able to start from a Twitter JSON stream, join different datasets, and create a real-time dashboard using a standard BI tool running SQL queries. No ETL is required, and new data in the Kafka stream shows up in the dashboard within seconds.
Interactive analytics on scalable, event streaming data to act while data is hot
In most projects, data streams are not just consumed by one application, but by several different applications. Since Kafka is not just a messaging system, but also stores data and decouples each consumer and producer from one another, each application can process the data feed when and with the speed it needs to do so.
In the e-commerce example mentioned above, one consumer could process orders in real time using ksqlDB and Rockset for SQL analytics in the backend. Another consumer could be a CRM system like Salesforce, which saves relevant customer interactions and loyalty information for long-term customer management. And a third consumer could respond to consumer behavior as it happens to recommend additional items or provide a coupon if the user is about to leave the online shop, which can be implemented easily as shown above.
With Confluent Platform and Rockset, you can process and analyze large streams of data in real time using SQL queries, whether it’s through human interaction on a command line or a custom user interface, integrated into the standard BI tool of your company, or automated within a Kafka application.
Interested in more?
Learn more about Rockset and download the Confluent Platform to get started with the leading distribution of Apache Kafka.
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


