[Demo-Webinar] Bereit, ZooKeeper Lebewohl zu sagen? Lerne KRaft kennen! | Jetzt registrieren
15 Things Every Apache Kafka Engineer Should Know About Confluent Replicator
Single-cluster deployments of Apache Kafka® are rare. Most medium to large deployments employ more than one Kafka cluster, and even the smallest use cases include development, testing, and production clusters. When working with a multi-cluster deployment, you’ll inevitably encounter the need to move data between clusters.
Confluent offers two approaches to multi-datacenter replication: Multi-Region Clusters and Confluent Replicator. The main difference between these two approaches is that a Multi-Region Cluster is a single cluster spanning multiple datacenters, whereas Replicator operates on two separate clusters. Multi-Region Clusters are built into Confluent Server, so they can greatly simplify setup and management of replication flows, particularly in failover/failback scenarios. For a Multi-Region Cluster to operate reliably, the datacenters must be physically close to each other, with a stable, low-latency, and high-bandwidth connection.
Ultimately, the best approach to use depends on your individual use cases and resilience requirements. For more information about using Multi-Region Clusters with Confluent Server, see David Arthur’s excellent post Multi-Region Clusters with Confluent Platform 5.4. Confluent provides a proven, feature-rich solution for multi-cluster scenarios with Confluent Replicator, a Kafka Connect connector that provides a high-performance and resilient way to copy topic data between clusters. You can deploy Replicator into existing Connect clusters, launch it as a standalone process, or deploy it on Kubernetes using Confluent Operator.
Here are 15 ways that Replicator can turbocharge your existing replication flows and enable new ones.
1. Replicator enables hybrid cloud architectures
Replicator provides a way to achieve consistency between Kafka clusters on premises and in private or public clouds. Common scenarios include bidirectional replication (where multiple clusters read from and write to topics, and Replicator synchronises the data across all of the clusters) and fan-out (where data is produced to a central cluster and Replicator distributes it to many outlying clusters).
Instead of managing separate communication channels for each application, you can use a Kafka cluster as a data hub in each datacenter, with Replicator handling synchronization between datacenters. This is a great way to reduce the number of public communication channels between hybrid cloud environments, and it also ensures that the communication channels are easily managed, monitored, and reliable. An example deployment is shown below:
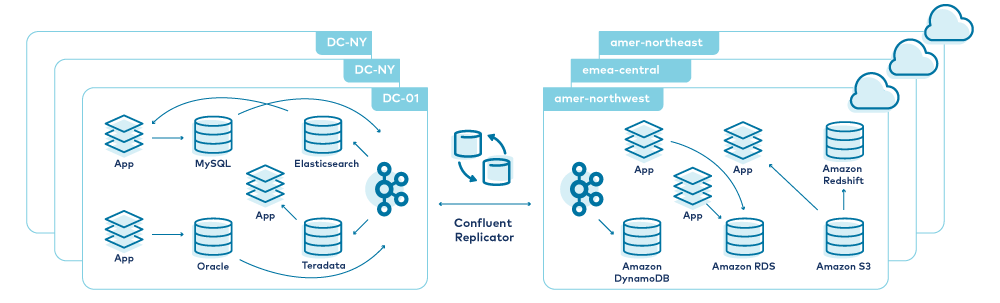
For more information about using hybrid cloud architectures with Confluent Platform, see Conquering Hybrid Cloud with Replicated Event-Driven Architectures by Rick Spurgeon.
2. Replicator supports out-of-the-box configuration with Confluent Control Center
Confluent Control Center integrates with Kafka Connect, enabling you to create and manage connectors—including Replicator—using a graphical interface. From the “Connect” menu, you can create a new Replicator instance using a wizard that recommends and validates configurations for the new connector. This lets you discover any configuration issues before you submit the connector, reducing the number of submission failures caused by invalid configuration.
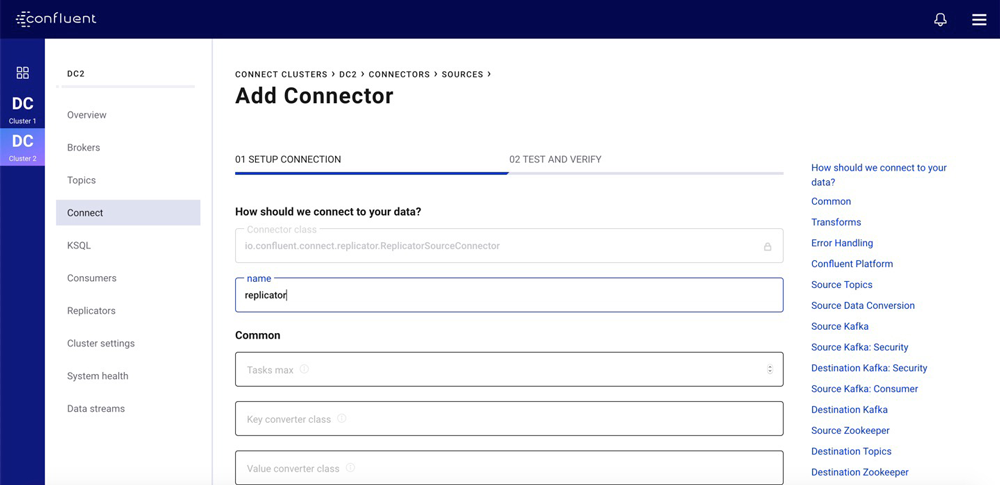
For more information about configuring connectors with Confluent Control Center, see the Connect documentation for Control Center.
3. Confluent Control Center enables Replicator monitoring
Starting in Confluent Platform 5.4, Confluent Control Center also offers detailed monitoring for Replicator. From the “Replicators” menu, you can see important metrics relevant to Replicator, including:
- Message lag: the number of messages present in the source cluster that are not yet present in the destination cluster
- Latency: the time between a message being produced to the source cluster and being produced to the destination cluster
- Throughput: the number of messages replicated per second
These metrics provide a way to determine the current state of your replication flows and the backing Kafka Connect infrastructure at a glance. For instance, message lag is critical to a disaster recovery flow. If the message lag is at 0, the recovery cluster has been fully caught up with the primary cluster and would therefore be ready to replace the primary cluster in case of a disaster. An increase in throughput might indicate that the load on Replicator has changed and that you should provision additional infrastructure to account for this; an increase in latency may indicate inter-cluster connectivity issues that require further investigation.
Confluent Control Center provides a centralised view of these metrics for all Replicators associated with a monitored cluster. The table below gives aggregate metrics for every Replicator instance.
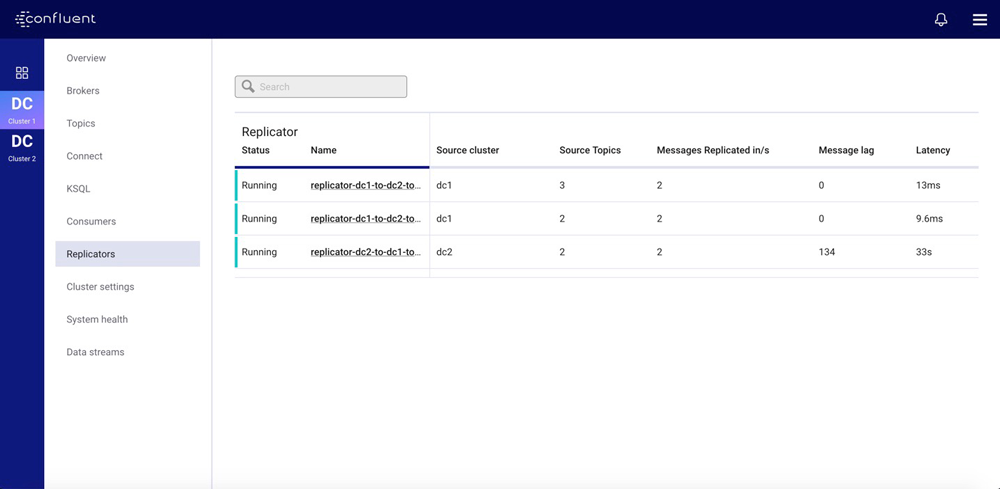
When you select a Replicator instance from this screen, Control Center shows the dashboard for the instance. The dashboard combines Replicator-specific metrics with metrics from the Connect cluster, providing an easy place to begin troubleshooting any issues.
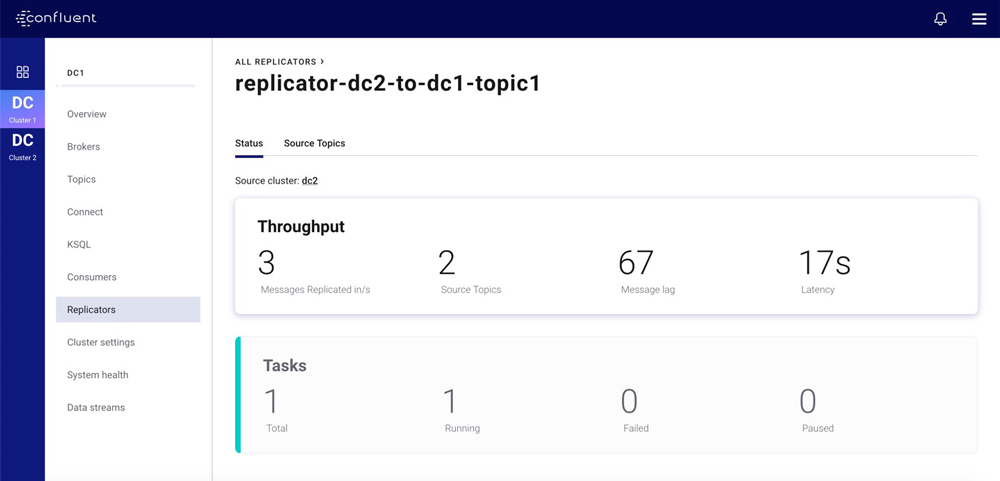
Control Center also provides fine-grained metrics broken down by Kafka Connect task and topic. These can be used to pinpoint issues in the larger replication flow. At this level, Control Center presents charts to help you quickly identify anomalies in a large amount of monitoring data. For instance, the chart below shows the lag on all partitions in replicated topics, with an indicator for each partition. You can easily identify any lagging partitions, as their indicators will be shown to the left of the chart.
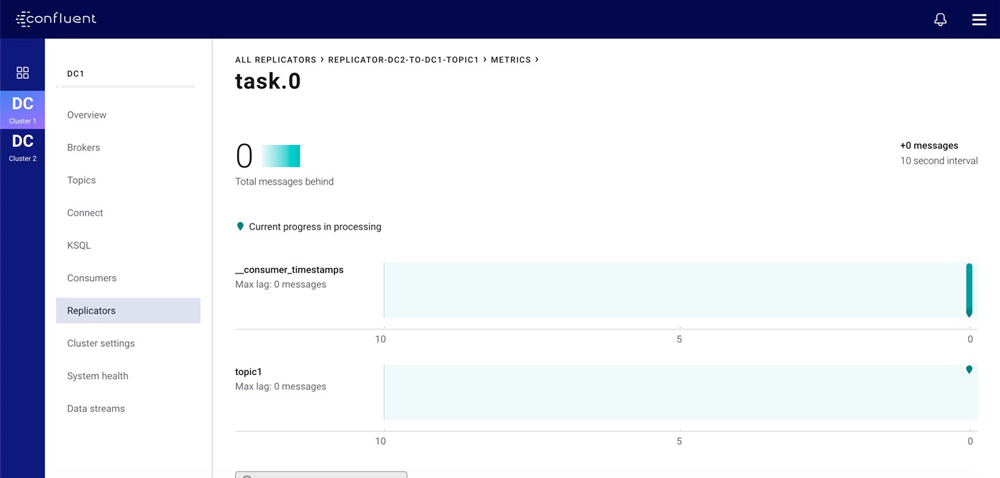
For more information about the Replicator monitoring options available in Control Center, see the Replicator Monitoring Extension and Use Control Center to Monitor Replicators documentation.
4. Replicator can migrate schemas between Confluent Schema Registry clusters
In Confluent Platform 5.2.0 and later, you can use Replicator to transfer schemas stored in Confluent Schema Registry from one registry to another. You can perform this migration either as a one-time operation or as an ongoing migration for disaster recovery purposes.
To migrate schemas, Replicator uses translators that run alongside your regular replication flow. This means that you can migrate schemas and topic data together using a single Replicator, which is especially relevant when migrating from on-premises deployments to Confluent Cloud. Replicator can translate schemas into the Schema Registry managed by Confluent Cloud.
For more information, see the Migrate Schemas documentation.
5. Replicator supports Role-Based Access Control (RBAC)
Because Replicator leverages Kafka Connect, you can take advantage of RBAC functionality to control the actions Replicator is allowed to perform on the underlying resources that it accesses. RBAC uses predefined roles, which have sets of permissions. These roles can be applied to cluster resources and principals. This collection of principal, cluster resource, and role is known as a role binding.
Replicator includes several embedded Kafka clients, and you can provide independent security configurations for each of these. Using RBAC, these configurations can limit Replicator client access to only the necessary resources. For instance, you can limit both the Replicator producer that produces messages to the destination cluster as well as the consumer that reads from the source cluster to only have access to the topics that are relevant to the replication flow.
Replicator extends this further, allowing operators to configure different principals for the administration and data transfer functions of a replication flow. For instance, you can configure Replicator to use principals with topic-specific operator or DeveloperManage roles (which have no read or write permissions) to create and synchronize topics in the destination cluster. For the producers writing data to the topics, you can grant only the write permissions included in the DeveloperWrite role (which has only write and no management permissions). This is particularly important in multi-tenant Connect clusters, where it may not be appropriate for other connectors to give topic management permissions to the Connect producer.
RBAC is simple to enable in Replicator. Use the existing sasl.jaas.config security configuration, accompanied by an appropriate prefix as shown below.
| producer.override.* | Producer writing to the destination cluster |
| src.consumer.* | Consumer reading from the source cluster |
| dest.kafka.* | AdminClient responsible for topic manipulation on the destination client |
| src.kafka.* | AdminClient responsible for fetching topic details from the source client |
RBAC simplifies security management and configuration for replication flows, so that you don’t need to redeploy when security requirements change. For more information, see the Authorization Using Role-Based Access Control documentation.
6. Replicator helps applications recover after a disaster
In a disaster recovery scenario, it is not enough to just mirror messages from your primary cluster to the failover cluster. Clients must be able to fail over to the same position in the failover cluster as they were at in the primary cluster. Without this, your applications may reprocess significant amounts of data—or worse, skip data that should be processed.
Since Confluent Platform 5.1.0, Replicator supports offset translation, which ensures that the message referenced by a consumer offset on the destination cluster will be consistent with the message referenced by the offset on the source cluster (even if these aren’t the same offset). When an offset is committed, a consumer interceptor records the timestamp of the message. Replicator preserves this timestamp between clusters, and the translator uses the timestamp to determine the correct destination cluster offset and commit it.
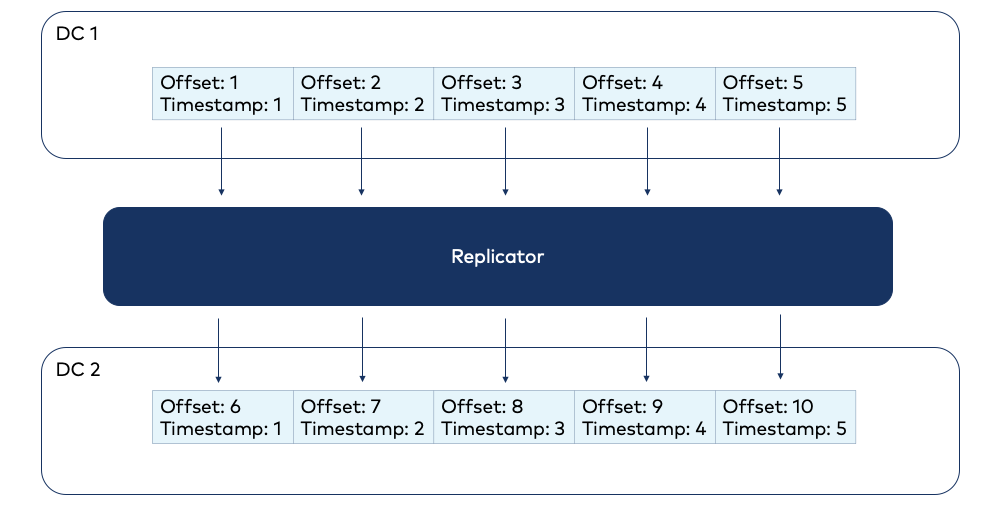
Because of this interceptor, enabling offset translation is as simple as adding configuration properties to the consumer configuration—no changes to the consuming application are required. You can easily apply offset translation to existing applications with zero development effort.
This feature provides an efficient and resilient way to ensure that in a failure scenario, clients can resume from the same point on another cluster. For more information, see the Replicator and Cross-Cluster Failover documentation.
7. Replicator can aggregate messages from multiple clusters
Many Kafka deployments follow a wheel-and-spoke pattern, where a number of edge clusters are deployed to service clients and the resulting data is collated in one or more central clusters. In this scenario, the ideal behaviour is that messages on all edge clusters are replicated into a single topic on the central cluster(s).
Replicator enables this pattern as well. You can set up multiple Replicators, each referring to an edge cluster and all writing to a single central destination cluster. A typical deployment has one Replicator per spoke cluster, with all replicating to the hub. The destination topic on the central cluster aggregates all of the messages from the edge clusters.
In the example illustrated below, we want to combine the orders topic from our north and south clusters into a combined orders topic in our analytics cluster. We achieve this using two Replicators, both producing to the same central topic.
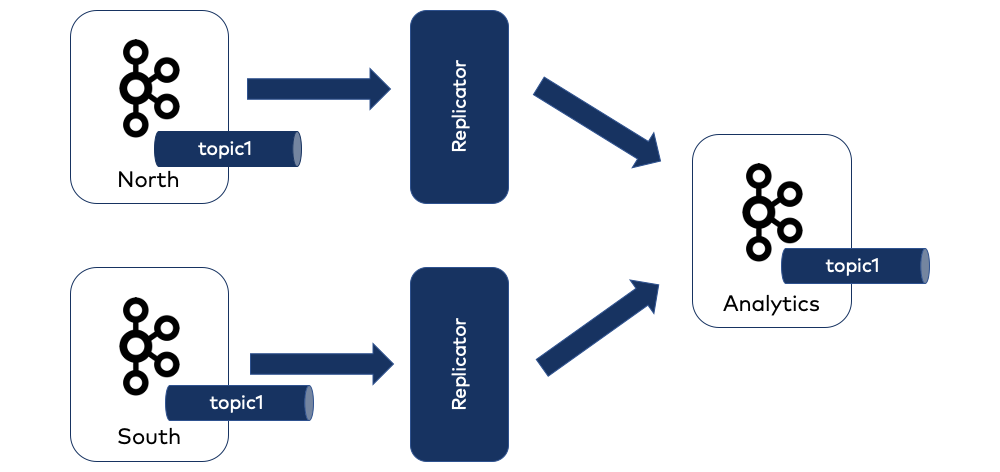
Using this wheel-and-spoke pattern, one need that often arises is topic renaming. Replicator includes additional functionality to handle this, as we’ll see next.
8. Replicator supports topic renaming during replication
A Replicator flow can rename a message’s topic when replicating the message to the destination cluster. For instance, you can consume messages from a src_messages topic on the source cluster and produce messages to a dest_messages topic on the destination cluster.
Replicator uses the topic.rename.format configuration to specify the destination topic. You can use either a literal topic name or a name containing the special string ${topic}, which will be replaced with the source topic name. In the example flow we just mentioned, a topic.rename.format of ${topic}.replica would result in a destination topic name of src_messages.replica. This is particularly useful when replicating multiple topics using a whitelist or regular expression. For more information, see the Destination Topics documentation for Replicator.
9. Replicator prevents cyclic replication
Cyclic replication occurs when a message is replicated back to its origin cluster by a replication flow. This could be either bidirectional replication, where cluster A replicates to cluster B and cluster B replicates to cluster A, or it can occur in more complicated flows, for example when cluster A replicates to B, B replicates to C, and C to A. This can result in an infinite loop where a message is replicated back to its source and then replicated again and again, indefinitely.
To address this problem, Replicator features provenance headers (enabled using the configuration provenance.header.enable=true). These extra headers are added to replicated messages to record their origin cluster and origin topic.
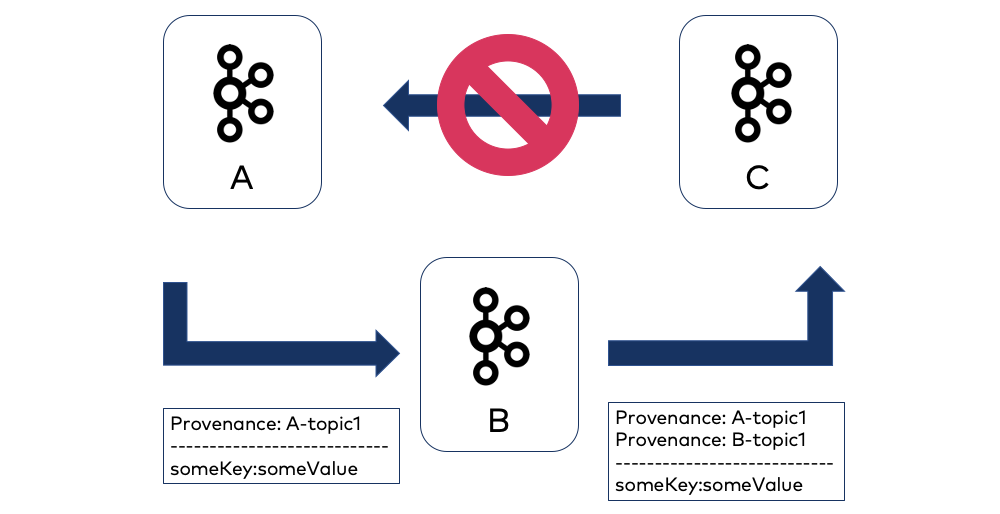
Replicator will not replicate a message to any cluster and topic combination for which the message has had a provenance header added, thus avoiding cyclic replication. This is especially useful in active-active bidirectional configurations, where messages can be produced to any cluster in the deployment and all clusters should be synchronized.
For more information about this feature, see Using Provenance Headers to Prevent Duplicates or Cyclic Message Repetition.
10. Replicator can run as an executable
In addition to deploying it into an existing Kafka Connect cluster, Replicator can be run as a standalone process, without requiring a pre-existing Kafka Connect cluster. The replicator binary distributed with Confluent Platform uses a small set of configuration files and command line parameters to configure and launch Replicator. Even better, multiple replicator executables, configured with the same cluster ID, work together in the same way as Kafka Connect nodes, providing fault tolerance and load distribution.
As an example, you can run the replicator executable as follows:
replicator \ --consumer.config ./consumer.properties \ --producer.config ./producer.properties \ --cluster.id replicator \ --replication.config ./replication.properties
For more information about running Replicator as an executable, see the Run Replicator as an Executable section in the documentation.
11. Replicator can start from any position within the source partitions
By default, a new Replicator begins replicating from the beginning of its subscribed partitions when the replication flow is started. However, in some scenarios, you need to start the flow from a different point (for instance, when appending to the end of a previous flow).
Starting in Confluent Platform 5.1.0, Replicator commits the current position of the flow in the source topics to the consumer offsets mechanism in the source cluster, as well as to Kafka Connect on the destination cluster. This means that Replicator can use either offset when determining a starting point. You can easily manipulate consumer offsets by running the kafka-consumer-groups command on the source cluster, setting the starting point for a Replicator flow.
By default, Replicator uses offsets from Kafka Connect first, and if these are not present, it will use the source cluster consumer offsets. You can change this behaviour by setting the offset.start property to consumer. This causes Replicator to use consumer offsets first, then offsets from Kafka Connect.
For more information, see the Offset Management documentation.
12. Replicator supports complex topic replication requirements
Replicator has three configuration properties for determining topics to replicate:
- topic.whitelist: a comma-separated list of source cluster topic names. These topics will be replicated.
- topic.regex: a regular expression that matches source cluster topic names. These topics will be replicated.
- topic.blacklist: a comma-separated list of source cluster topic names. These topics will not be replicated.
All of these properties can be provided in a single Replicator configuration. They work cooperatively to determine which topics to replicate. For instance, given a sequence of topic names from topic1 to topic4 (topic1, topic2, topic3, and so on), you could specify a topic.whitelist of topic1, a topic.regex of topic[2,3,4], and a topic.blacklist of topic4. Replicator would combine these constraints to produce a final list of replicated topics containing topic1, topic2, and topic3.
For more information about these configuration parameters, see the Source Topics documentation.
13. Replicator synchronizes topic configuration
When transferring messages between clusters, Replicator preserves the metadata associated with the messages. One important aspect of this is topic configuration: Replicator periodically synchronizes any custom topic configuration from the source topic to the destination topic. Synchronization applies not only during topic creation, but also dynamically, even after topic creation and after replication starts. Replicator ensures that the topic configuration state is consistent between the source and destination clusters.
Let’s say that you want to drain messages from a topic. The usual way you would do this is to stop the producers writing to the topic and then set retention time on the topic to a low value. But if the topic you’re draining is being replicated, this configuration change would apply only to the source topic, resulting in inconsistency between the source topic and replicated topic. With Replicator’s topic synchronization, the topic will be drained on both the source cluster and the destination cluster.
14. Replicator supports Single Message Transforms (SMTs)
Errata
This feature was deprecated as of CP 7.5
15. Replicator verification tool
Replicator enables a very broad set of functionality, and some of this functionality requires configuration within the connector definition as well as within the source and destination clusters. To address this, Confluent has created a verification tool that allows operators to verify their Replicator configuration, identifying potential issues before deploying Replicator to production. This verification includes:
- Connectivity to the source and destination clusters
- ACLs (if security is enabled)
- Licensing
- Topic subscriptions
Summary
The pointers in this article are meant to optimize your replication flows and result in higher-performing Replicators in your Kafka deployment. We’ve only cherry-picked a few notable capabilities here, but the complete set is available in the Replicator for Multi-Datacenter Replication documentation. Also, check out the white paper Disaster Recovery for Multi-Datacenter Apache Kafka Deployments and the Replicator Tutorial on Docker for a demo showing many of these capabilities in a small, self-contained environment.
Interested in more?
If you’d like to know more, you can download the Confluent Platform to get started with Replicator and a complete event streaming platform built by the original creators of Apache Kafka.
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...