[Webinar] AI-Powered Innovation with Confluent & Microsoft Azure | Register Now
Making Confluent Cloud 10x More Elastic Than Apache Kafka
At the onset of the COVID-19 pandemic in early 2020, Instacart experienced its highest customer demand in history. Its customer-facing applications, backend systems, and business processes were all put to the test as millions of people turned to Instacart as an essential service to safely get the groceries and goods they needed.
Elasticity is the cornerstone of cloud-native computing, and it’s what allows a business like Instacart to scale quickly, add resiliency to a system, and make its products cost effective. At Confluent, we serve thousands of customers—and they expect a lot more from their data infrastructure than ever before. Our customers look for a truly cloud-native data streaming platform that scales transparently across data centers around the world, while abstracting away the tedious implementation details.
To meet the demands of these modern data pipelines, we took Apache Kafka®’s horizontal scalability to the next level—in fact, we took it up multiple levels—and made Confluent Cloud 10x more elastic. But how exactly did we achieve that?
Uncovering opportunities to go beyond Apache Kafka
To understand how Confluent Cloud is 10x more elastic than Kafka, it’s important to understand how Apache Kafka scales.
Let’s take an example with a cluster with three brokers [0, 1, 2]. The cluster retains messages for 30 days and receives 100 MBps on average from its producers. Given a replication factor of three, the cluster will retain up to 777.6 TB of storage, or about 259.2 TB per broker with equal balance.
Now when we scale the cluster by one broker to add some more capacity, what happens? Now there are four brokers and we need to bring the new machine up to speed so it can start accepting reads and writes. Assuming perfect data balancing, this means the new broker will be storing 194.4 TB (777.6 TB / 4), which will need to be read from the existing brokers. On a 10 gigabit network, that would take 43 hours using vanilla Apache Kafka (assuming the full bandwidth was available for replication—in practice it would take even longer).
Delivering 10x elasticity with Confluent Cloud
With Confluent Cloud, scaling is 10x faster than with Apache Kafka—and doesn’t involve the capacity planning, data rebalancing, or any other typical operational burden that goes into scaling data infrastructure. Our Basic and Standard offerings allow instant auto-scaling up to 100 MBps of throughput and can scale down to zero with no pre-configured infrastructure you have to manage. Our dedicated offering scales to 20 GBps of throughput with the ability to expand and shrink clusters with the click of a button or the call of an API.
The quicker data can move within the system, the quicker it can scale. The secret sauce that powers this 10x elasticity is Confluent Cloud Intelligent Storage, which uses multiple layers of cloud storage and workload heuristics to make data rebalancing and movement faster than ever before. Tiering data is challenging because it often requires tradeoffs between costs and performance. Moving data among the in-memory cache, local disk, and object storage in a performant way was a major undertaking, but having the usage patterns of thousands of customers helped us refine the system that powers Intelligent Storage over the years, and on the whole, we have been able to make the system more performant.
So how does this actually work? Brokers in Confluent Cloud keep most of their data in object storage and retain only a small fraction of the data on local disks. The actual ratio of data in object storage vs. the brokers is dynamic, but in the illustration here, let’s assume that one day’s worth of data sits on the brokers, and the rest sits in object storage. That’s a 1-to-30 ratio.
In this example, each broker keeps 8.6 TB locally and 251.6 TB in object storage. The historical data in the object store is accessed by the brokers without blocking the real-time reads and writes because it all goes through a separate network path. All the reads from the clients go through the brokers and all the offsets are the same. When using Confluent Cloud, you never have to think, “which tier is my data in?” as that is all handled for you. Since only a small amount of data is actually on the brokers, we can use faster disks and give our customers more performance per dollar. You can learn more about this system by watching Jun Rao’s Tiered Storage course.
Now what happens when we scale up the cluster by adding a broker? With Confluent Cloud, I don’t have to move nearly as much data around—just the data that is on the physical brokers (8.6 TB * 3 brokers / 4 brokers = 6.5 TB in total or 2.2 TB from each broker) and the references to all the data that is stored in object storage. Those references are very small and negligible from the perspective of data movement.
When we scale the cluster, the scaling operation is kicked off immediately after you prompt the system for more resources in the UI or with the Confluent Cloud API. The whole operation is online, which means no downtime, and with Confluent Cloud’s self-balancing mechansim partitions, start moving to the new machines right away. Clients don’t have to wait for everything to rebalance. As soon as a partition is caught up on a new machine, clients can start taking advantage of the new capacity. On a 10 Gigabit network, the complete scaling operation only takes 1.4 hours in our example—and in reality could be much less. Compared to the 43 hours with vanilla Apache Kafka—that’s up to 30x faster! (I know the blog post says 10x better, but that’s because my marketing counterparts wanted to be conservative.)
Real-world numbers
Benchmarks and theoretical examples have their place, but in practice, what’s the improvement of Confluent Cloud’s Intelligent Storage? We had the opportunity to observe the improvements of Confluent Intelligent Storage recently when we rolled out Infinite Storage to Confluent Cloud on Azure. Not only does Confluent Intelligent Storage make Confluent Cloud more elastic, but it allows customers to store petabytes of data in Confluent Cloud and never have to worry about scaling Kafka storage again. (More on that in an upcoming blog post.)
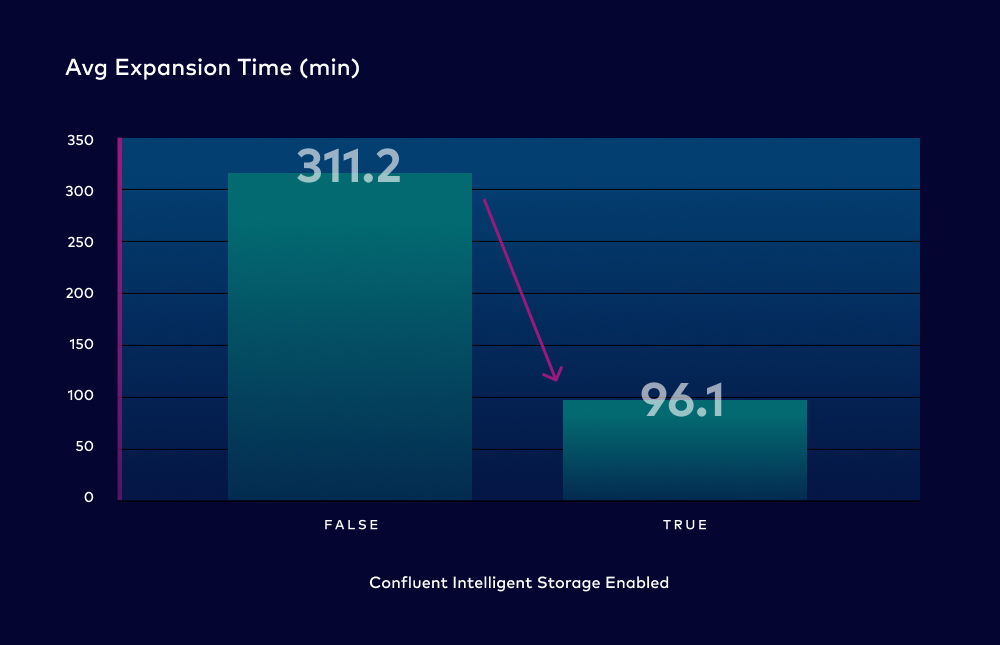
Now keep in mind that this isn’t comparing Apache Kafka to Confluent Cloud. This is comparing Confluent Cloud pre-Intelligent Storage and post-Intelligent Storage on Azure. It’s actually a more challenging comparison because we’d already been at work optimizing the experience on Azure. It also gives us a good reference between Confluent Cloud and other “hosted cloud services” for Apache Kafka. Also, keep in mind that these times include node provisioning, if necessary. The start line is when the user kicks off cluster expansion and the finish line is when the full rebalance is completed. The cluster is adding capacity throughout the entire process.
We looked at the last few months of cluster expansion times. We put the clusters into two groups, those that had Confluent Intelligent Storage enabled and those that didn’t. We found that on average, Confluent Intelligent Storage decreased cluster expansion times by 69%. In the most extreme case, we saw a decrease of 954%! And we are just getting started in this area. We have a lot more planned around elasticity.
Elasticity isn’t just about faster scaling
Making Confluent Cloud 10x more elastic than Apache Kafka doesn’t just mean faster scaling. It also means shrinking the clusters when demand reduces, greater resiliency in the face of failures, and reducing your total cost of ownership to ensure you’re not overpaying for infrastructure.
Expand and shrink to meet demand
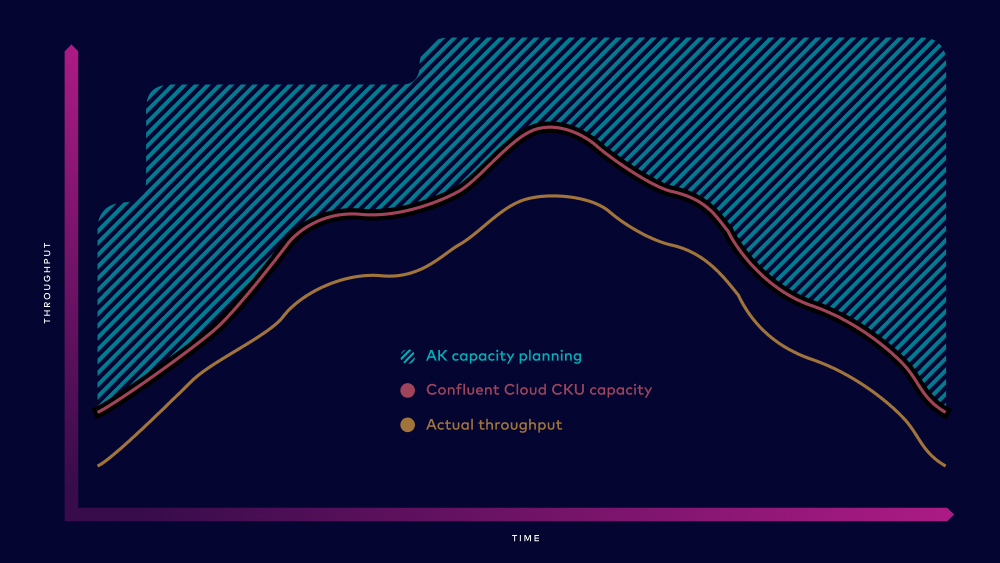
Once the holiday rush is over, you don’t want that highly provisioned cluster sticking around costing you money too. However, teams working with Apache Kafka have historically had very limited, time-consuming options for how to do this. Capacity adjustments require a complex process of sizing and provisioning of new clusters, networking setup, traffic balancing across new brokers and partitions, and much more. Too often, the manual effort isn’t worth the savings of running a smaller cluster. Furthermore, expensive excess capacity is typically maintained in order to avoid the risk of any downtime.
A key differentiator of Confluent cloud is that elastic scaling applies when sizing both up and down. You can shrink clusters just as fast as you can expand them. Our Basic and Standard offerings allow instant auto-scaling up to 100 MBps of throughput and can scale down to zero with no pre-configured infrastructure to manage. With our Dedicated clusters, you just move the CKU slider to the left within the Confluent Cloud UI, or make an API call, and the cluster scales down. With less data to move, it happens that much faster.
Resiliency
When things break in the cloud, you need a system that is going to quickly detect that failure and react. Let’s dig into how Confluent Cloud’s elasticity makes it more resilient.
When a broker fails, a storage service volume gets slow, or perhaps a load balancer doesn’t start, the first step is detecting the problem. Once we do, we need the cluster to shift the responsibility of partitions away from the bad machine and onto other brokers. If we can move less data to get the brokers caught up, then the system can recover faster. And that’s exactly what Confluent’s Intelligent Storage does—less data on the brokers means less data movement and therefore faster recovery when failures inevitably happen.
Upgrading is another area where elasticity improves Confluent Cloud’s resiliency. Upgrades are taken care of automatically with Confluent Cloud, saving valuable engineer hours while delivering the latest patches and features. What’s less obvious is that with less data movement, clusters become more nimble, so we’re able to upgrade our entire fleet much faster when a critical update (like the log4j vulnerability) is required. These more frequent updates help stop costly outages, security breaches, and other disruptions—and they’re done with zero downtime.
Total cost of ownership
Making Confluent Cloud 10x more elastic than Apache Kafka improves the total cost of ownership in a number of ways, enabling our users to:
- Avoid over-provisioning. Apache Kafka best practices traditionally recommend provisioning your cluster for peak usage. This often comes months or even quarters ahead of the traffic. With Confluent Cloud, this is reduced to mere hours, so you can scale right before the traffic hits and not waste weeks of unused capacity. With the ability to shrink fast, you can also avoid overpaying for any excess capacity when traffic slows down.
- Enable a faster, less expensive service. Because Confluent Cloud takes advantage of a blend of object storage and faster disks in an intelligent manner, you get a lower latency service, at a competitive price, that’s billed only when you use it.
- Remove cycles spent on infrastructure. With Confluent Cloud, scaling is either automated with our Basic and Standard clusters or done through a click of a button with Dedicated clusters. That means you don’t need to spend time on capacity planning, network setup, load balancing, or any of that. Instead, your engineering resources can actually be spent on innovation and building something that differentiates your business.
With faster scaling up and down, businesses save on TCO by avoiding wasted capacity from over-provisioning
With Confluent Cloud, you get a cloud-native Kafka experience that offers elastic scaling, resiliency in the face of failure, and a lower total cost of ownership. If you want to learn more about the details of how we made Confluent 10x more elastic, check out our video overview and customer stories.
To give Confluent Cloud a go and see how it scales faster than Apache Kafka, sign up for a free trial. Use the code CL60BLOG for an additional $60 of free usage.
More posts in this series
- Introduction from our CEO: Making an Apache Kafka Service 10x Better
- Storage: Building Kafka Storage That’s 10x More Scalable and Performant
- Reliability: Leave Apache Kafka Reliability Worries Behind with Confluent Cloud’s 10x Resiliency
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...