New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
COMPARE
Confluent Cloud vs. Amazon MSK on Apache Kafka® Costs & Capabilities
Fully realizing the value of Apache Kafka® requires dedicated engineering resources and significant expertise in distributed systems. As your footprint expands, self-managing Kafka becomes an unsustainable balancing act—leaving you stuck between paying for overprovisioned clusters or risking unplanned downtime.
This in-depth Confluent Cloud and Amazon MSK comparison will show you how each stacks up on scalability, resilience, and platform capabilities—and how Confluent cuts total cost of ownership for self-managed Kafka by 40-70%.
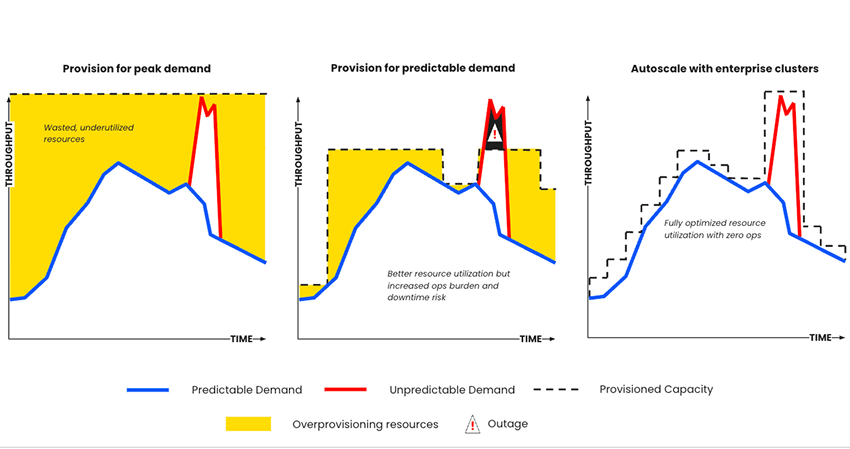
Operate 70% More Efficiently vs Self-Managed, Hosted Apache Kafka®
Whether you’re building real-time data pipelines or AI agents, Kafka is an ideal choice. Its distributed design is built to handle high-throughput, low latency workloads but also demands deep expertise to manage, secure, and optimize at scale without expensive overprovisioning or risking outages.
Founded by the original co-creators of Kafka—Confluent invested 3M engineering hours into rearchitecting Kafka to operate up to 70% more efficiently in the cloud. The result: Kora, the cloud-native Kafka engine that powers our fully managed data streaming platform with:
-
Serverless, autoscaling clusters that save over half your infrastructure costs
-
3x the resource efficiency of a self-managed, single-tenant cluster
-
~50% lower cluster latency vs. self-managed to further increase utilization
-
Optimized routing and API integrations that cut network spend
Today, Kora powers 30,000 Confluent Cloud clusters processing 3+ trillion messages per day across AWS, Google Cloud, and Microsoft Azure.
Register for Kafka Cost Webinar
MSK Zookeeper Migration: Turn a Critical Update Into a Strategic Advantage
With Kafka’s ZooKeeper support ending in May 2026, all Kafka users who are on a Zookeeper-based cluster face a critical full-scale migration to KRaft to avoid running on obsolete versions of Kafka.
What Does This Mean for MSK Customers?
-
Your Zookeeper-based clusters will no longer receive critical updates—including security patches and bug fixes—from the open-source community. This means MSK customers will be running on a self-managed version of Kafka with potential security and management issues.
-
MSK offers No In-Place Upgrade Path: MSK customers must stand up a new KRaft-enabled cluster and migrate data and workloads manually.
-
MSK Express Migration Isn’t Seamless: Moving from MSK Provisioned Standard to MSK Express also requires additional effort.
Why migrate to Confluent?
This essential migration is a perfect time to re-evaluate. Why perform a heavy lift just to stay with a basic service? Migrate to a fully managed data streaming platform and take advantage of all of the advanced features & cost savings!
-
Fully-Managed & Cloud-Native: automates the entire Kafka lifecycle—provisioning, upgrades, scaling, and partition balancing—so users focus on applications, not ops.
-
Superior Support: offers expert, first-party Kafka support and a 99.99% SLA covering the full streaming platform which is 10X better than MSK
-
Rich Integrations & Ecosystem: delivers the largest managed connector library, including more AWS service integrations plus support for multi-cloud and SaaS solutions.
-
Data Governance: offers a full suite of governance features like Schema Registry, which ensures data quality, consistency, and a central source of truth for all your data streams.
-
Everywhere: supports multi-cloud deployments across AWS, Azure, and Google Cloud, as well as hybrid architectures that span cloud and on-premises environments
-
TCO Savings: by migrating to Confluent Cloud by leveraging features like PNI (Private Network Interface) & auto-scaling; Confluent guarantees to match or beat the price of AWS MSK
"[With Confluent,] we reduced our projected yearly cost by 69%. And [saved] months of planning we would have to put into meetings and seasonal projections."
Justin Dempsey, Senior Manager at SAS Cloud
"Since we built Horus, our global IPV4 scanning platform, on top of Confluent, we've saved over $1M dollars compared to open source Kafka or MSK."
Jared Smith, Senior Director, Threat Intelligence at SecurityScorecard
"With Confluent, we get true elasticity, which is critical for scaling on big retail events such as Black Friday or when signing on large new clients—all backed by a higher SLA."
lan Compton, Technology Director at RevLifter
Kafka Cost of Ownership – MSK vs Confluent
As internal adoption grows and your Kafka footprint expands, your team will have to spend more time and resources on:
-
Planning, sizing,and managing cluster provisioning
-
Patching and upgrading software
-
Failover design and planning for availability
-
Filling high-risk governance and security gaps
-
Planning and optimizing for reliability
-
Manual load balancing
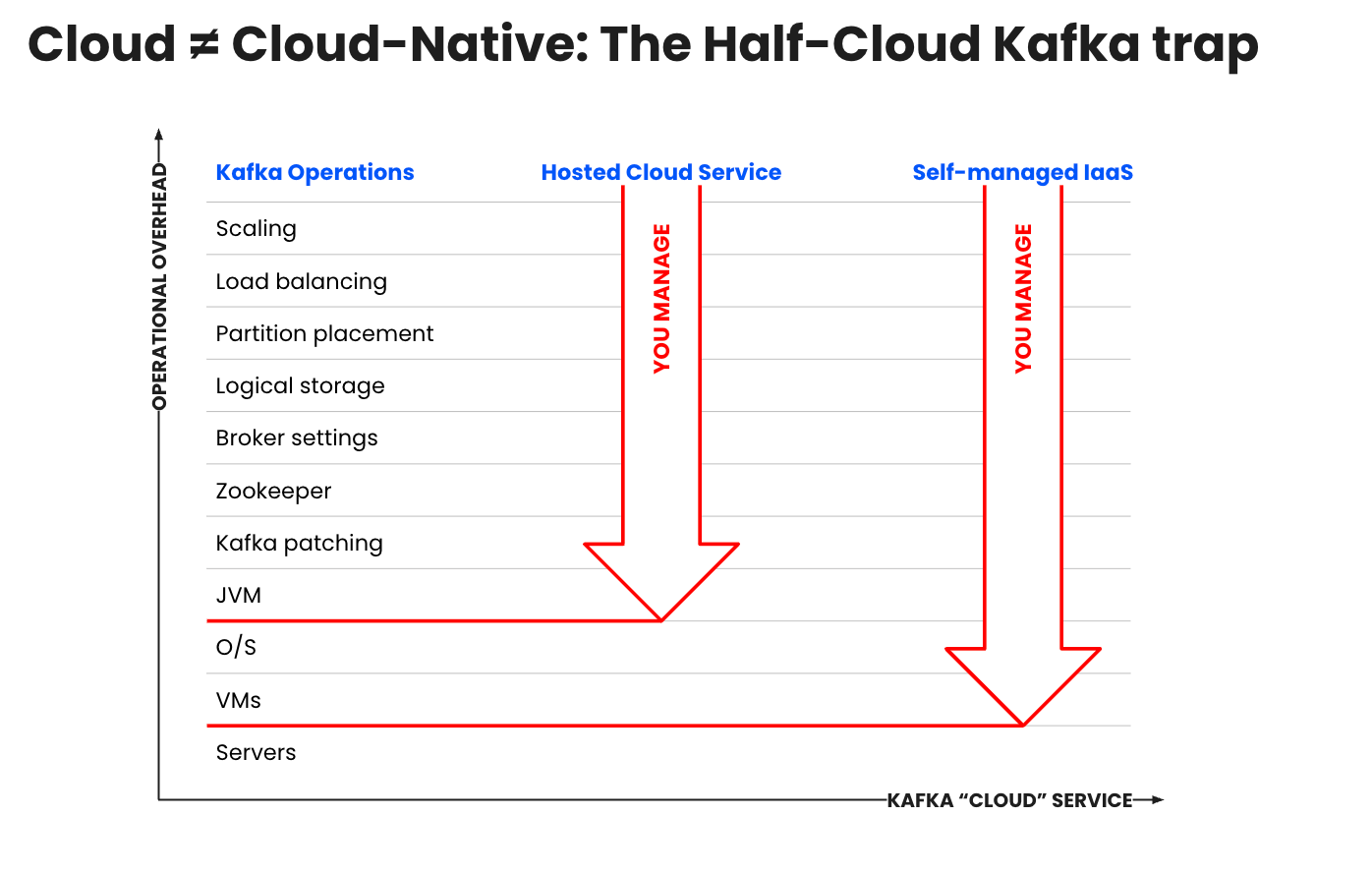
Realizing Kafka’s full value comes with significant financial and opportunity costs: an average of 2+ years to reach production at scale and $3-5M in platform development and operations costs. Both Confluent Cloud and Amazon MSK promise to offload this operational burden. But “managed” Kafka services aren't created equal, and choosing hosted Kafka with your cloud service provider leaves your teams still stuck with all the heavy lifting.
In this managed Kafka service comparison, see how much more you can do—and save—with truly managed, serverless Kafka and a data streaming platform that delivers a 257% return on your investment, with payback in under 6 months.
| Confluent Cloud | Amazon MSK | |
|---|---|---|
| Summary | Confluent offloads most manual operations with its automated capabilities for scaling Kafka clusters and connector instances. | Your operational burden stays high as Amazon MSK only offers limited automated capabilities for deployment tasks, even for MSK Serverless Clusters |
| Automated Product Capabilities vs Manual Operations & Custom Development |
Self-managed:
Automated on all clusters:
Custom:
*On all Confluent Cloud clusters |
Self-managed:
Custom:
Automated:
*Only on MSK Serverless clusters |
| Freedom of Choice | Available on AWS, Google Cloud, and Microsoft Azure | Available only on AWS |
Management, Monitoring & Maintenance on Confluent Cloud vs. Amazon MSK
Although MSK addresses some operational gaps, it still has many limitations. Self managing or using hosted Kafka comes with significant direct and indirect costs including:
- High infrastructure spend from overprovisioned clusters: Overprovisioning required to support fluctuating demand, inability to scale storage without growing compute, performance degradations with manual configs, rebalancing, and upgrades and patching
-
Operational overhead and constrained resources: Costly time & resources spent provisioning and capacity planning, upgrades and monitoring vs. differentiating the business; costs to recruit, hire, and retain Kafka talent
-
Unplanned outages: Increasing risk of costly downtime and security breaches as Kafka spans more use cases, apps and data systems, teams, and environments
These costs only compound, leading to a delayed time to value, increased TCO, and a higher risk of lost revenue due to unplanned downtime, security breaches, and data loss.
Let's take a look at how Confluent Cloud and Amazon MSK compare on removing operational burden and solving common Kafka challenges.
Read Kafka vs. Confluent vs. MSK White Paper
| Service | Confluent Cloud | Amazon MSK | MSK Serverless |
|---|---|---|---|
| Provisioning | Self-serve, on-demand for Kafka, Schema Registry, and Flink | Self-serve, on-demand for Kafka only | Self-serve, on-demand for Kafka only |
| Autoscaling | Serverless, autoscaling clusters right-sized for any workload | Manual scaling | Elastic scaling to limited quota (200/400 MBps) |
| Cluster Types | Flexible, cost-effective cluster types for any workload and use case | Standard and Express clusters, which both require manual scaling | MSK Serverless clusters are MSK’s pre-provisioned clusters, suitable for unpredictable, mission-critical workloads |
| Infrastructure as Code | For both control plane and data plan | For control plane only | For control plane only |
| Infrastructure Monitoring | Proactive monitoring | Manual monitoring | Proactive monitoring |
| Topic Monitoring | Free, pre-aggregated metrics | Topic-level metrics cost extra | Default monitoring is free |
| Upgrades | Always the latest stable version | Limited version support | Limited version support |
| Software Patches | Proactive fixes | Reactive fixes | Reactive fixes |
| Cluster Expansions | Elastic scalability | Manual data rebalancing | Elastic scalability |
| Scaling Connectors | Pre-built and fully managed | Self developed and managed | Self developed and managed |
How Do Confluent Cloud and Amazon MSK Simplify Cluster Sizing?
-
Confluent Cloud uses throughput-based sizing: This eliminates cumbersome performance testing and reduces infrastructure costs with elastically scalable, scale-to-zero clusters where you only pay for what you use.
-
MSK Provisioned uses broker-based sizing: You must allocate time and resources to run performance tests to pick broker types and count and overprovision infrastructure to reduce the need for complex expansions later due to autoscaling limitations (four operations per day).
-
MSK Serverless uses throughput-based sizing: Provision Kafka clusters along with Glue Schema Registry and Flink. Custom efforts are needed for connectors and Kafka proxy.
How Do Confluent Cloud or Amazon MSK Automate Provisioning & Management?
-
Confluent Cloud offers self-serve, on-demand provisioning for the entire platform: Provision Kafka clusters along with any other Confluent Cloud component including Schema Registry, Connect, and Confluent Cloud for Apache Flink®. And you can also use Terraform provider to automate management of both control plane resources—like Clusters and Schema Registry—and data plane resources, such as Topics and ACLs.
-
Amazon MSK offers self-serve, on-demand provisioning but only Kafka only: Provision Kafka clusters along with Glue Schema Registry and Flink Custom efforts needed for connectors and Kafka proxy for both MSK Provision and MSK Serverless. Terraform is only able to deploy and manage control plane resources, and you need to build custom operators and processes to manage data plane resources.
Do Confluent Cloud or Amazon MSK Offer Monitoring Out-of-the-Box?
-
Confluent Cloud offers proactive infrastructure monitoring and free-aggregated metrics for topic monitoring Stay focused on app development with proactive cluster monitoring and maintenance from the Kafka experts. Infinite Storage enables unlimited cluster-level storage use cases while reducing risk of disk space-related failures. Access to the most important metrics pre-aggregated at the topic and cluster level is available at no additional cost, and you can consume metrics with your third party monitoring service of choice using Metrics API.
-
MSK Provisioned offers manual infrastructure monitoring and topic-level metrics at an extra cost Assign resources to monitor broker metrics such as CPU utilization to proactively manage cluster performance. Monitor and create alerts for disk space to prevent failures due to storage capacity. Pay to consume and manually aggregate per-broker and per-topic level metrics to monitor overall usage.
-
MSK Serverless clusters have proactive infrastructure monitoring and free default topic monitoring: Stay focused on app development with proactive cluster monitoring and maintenance. Infinite Storage enables unlimited cluster-level storage use cases while reducing risk of disk space-related failures. And access topic-level metrics for free using CloudWatch console, a separate tool for monitoring multiple AWS products; does not include partition level metrics, or native-integration with popular monitoring tools like Datadog and Dynatrace.
How Is Kafka Maintenance Handled on Confluent Cloud vs. Amazon MSK?
-
Confluent Cloud is always updated to the latest stable version and bugs and vulnerabilities are fixed proactively. It offers a 99.99% SLA inclusive of Kafka, bug fixes, patching, and much more.
-
Amazon MSK has limited version support and reactive fixes: MSK only supports a subset of Kafka releases, and you must manually trigger upgrades once AWS adds support for it after the scheduled Apache release. MSK offers a 99.9% SLA and chooses to offer only select versions of Kafka and failures due to Kafka software not covered by MSK uptime SLAs. Embracing a subset of releases forces a reactive approach to fixing vulnerabilities. MSK Serverless clusters see zero intervention as part of nondisruptive rolling upgrades—MSK only supports a subset of Kafka releases and the latest version is unknown and fully abstracted.
How Do Confluent Cloud and Amazon MSK Expand and Shrink Clusters?
-
Confluent Cloud autoscales and automatically allocates resources to your cluster: Confluent manages consumer lag as throughput scales up or down to GBps scale with fully elastic, autoscaling clusters that save over half your infrastructure costs. Eliminate cluster compute over-provisioning, and set your own retention limits with infinite storage.
-
Amazon MSK requires manual data rebalancing for Provisioned clusters as well as self-developed, self-managed connectors: Manual data rebalancing process required using Cruise Control after brokers are added to any cluster. Tiered storage is available, but still needs EBS volumes which can be scaled up to 16TB per broker with a 30 broker limit. Leverage self-built or community-built connectors without expressed technical support from AWS, as only underlying MSK Connect infrastructure is included.
-
MSK Serverless clusters have elastic scaling to limited quotas and still require self-developed, self-managed connectors: Effortless scaling up and down from 0 to 200 MBps with automatic cluster rebalancing eliminates cluster compute overprovisioning when increasing topic retention with Infinite Storage.
Confluent’s Complete Data Streaming Platform vs Hosted Kafka on AWS
Why is Confluent trusted across industries? Confluent delivers enterprise-grade capabilities above and beyond MSK's feature set to deliver a complete data streaming platform, equipping you to unlock countless streaming use cases.

| Service | Confluent Cloud | Amazon MSK | MSK Serverless |
|---|---|---|---|
| Kafka UI | Fully managed | Not available | Not available |
| Authentication | Broad authentication | Broad authentication | Limited authentication |
| Encryption | End-to-end encryption | Not supported | Not supported |
| Connectors | Pre-built & fully managed | Custom-built & self-managed | Custom-built & self-managed |
| Data Governance | Fully managed | Not available | Not available |
| Stream Processing | Fully managed | Adds complexities | Adds complexities |
| Zero-ETL for Streams-to-Tables | Now available with Tableflow | Not available | Not available |
What Enterprise-Grade Security Features Do Confluent Cloud and Amazon MSK Offer?
-
Confluent Cloud supports broad authentication for all cluster types: Only authenticated clients are allowed access to a cluster. Confluent Cloud supports SASL/PLAIN and SASL/OAUTHBEARER (in preview) as authentication mechanisms. Client-Side Field Level Encryption on Confluent Cloud adds an extra layer of security by encrypting sensitive data on the client, securing it on both client and server, and maintaining security during data in motion between producers and consumer mechanisms.
-
Amazon MSK supports broad authentication for MSK Provisioned clusters, Limited authentication for MSK Serverless, and no support for encryption: All MSK clusters only allow authenticated access, but MSK Provisioned clusters support SASL/SCRAM, mTLS and IAM as authentication mechanisms while MSK Serverless clusters only support IAM as authentication mechanism.
What Kind of Kafka Connectors to Confluent Cloud and Amazon MSK Offer?
-
Confluent Cloud offers 120+ pre-built connectors and 80+ fully managed connectors: Seamlessly and effortlessly integrate Confluent with modern and legacy services across on-premises and public clouds with a continuously growing portfolio of +120 connectors available either as fully managed components or as pre-built components covered by Confluent support.
-
Amazon MSK supports custom-built, self-managed connectors only: Integrate Kafka with your data services with the option to build your own connectors or deploy from a small subset of community developed connectors. Custom built connectors require maintenance and Kafka community connectors are not covered by AWS technical support.
What Governance Capabilities Do Confluent Cloud and Amazon MSK Offer?
-
Confluent Cloud offers Stream Governance, a fully managed suite of services that manage the data availability, integrity, and security: Stream Governance is built upon three key strategic pillars: Stream Lineage, Stream Catalog, Stream Quality. Data Quality Rules guarantee high-quality streams.
-
Amazon MSK requires use of free community tools without support or paid third-party tools to govern data in Kafka topics: MSK does not have lineage or catalog capabilities. For data quality, MSK and MSK Serverless integrate with Confluent and Glue Schema registry. However, they lack broker-side schema validation that enforces data producers to use Schema Registry to control schema evolution, Data Quality Rules to validate and constrain individual field values within a data stream, and Schema Linking that syncs schemas across different environments.
What Stream Processing Capabilities Do Confluent Cloud and Amazon MSK Offer?
-
Confluent offers serverless stream processing with Confluent Cloud for Apache Flink®: Users simply create a Flink cluster and get started with stream processing using SQL-like language. Confluent Cloud also supports the fully managed AWS Lambda service.
-
Amazon MSK offers stream processing with Flink, although with added complexities: MSK supports Managed Service for Apache Flink (MSF), which is powerful but adds complexities. As users need to configure networking, create MSF Studio notebook, author the job using SQL-like syntax, test the code, package the code, upload to S3, and create a MSF application from the uploaded code.
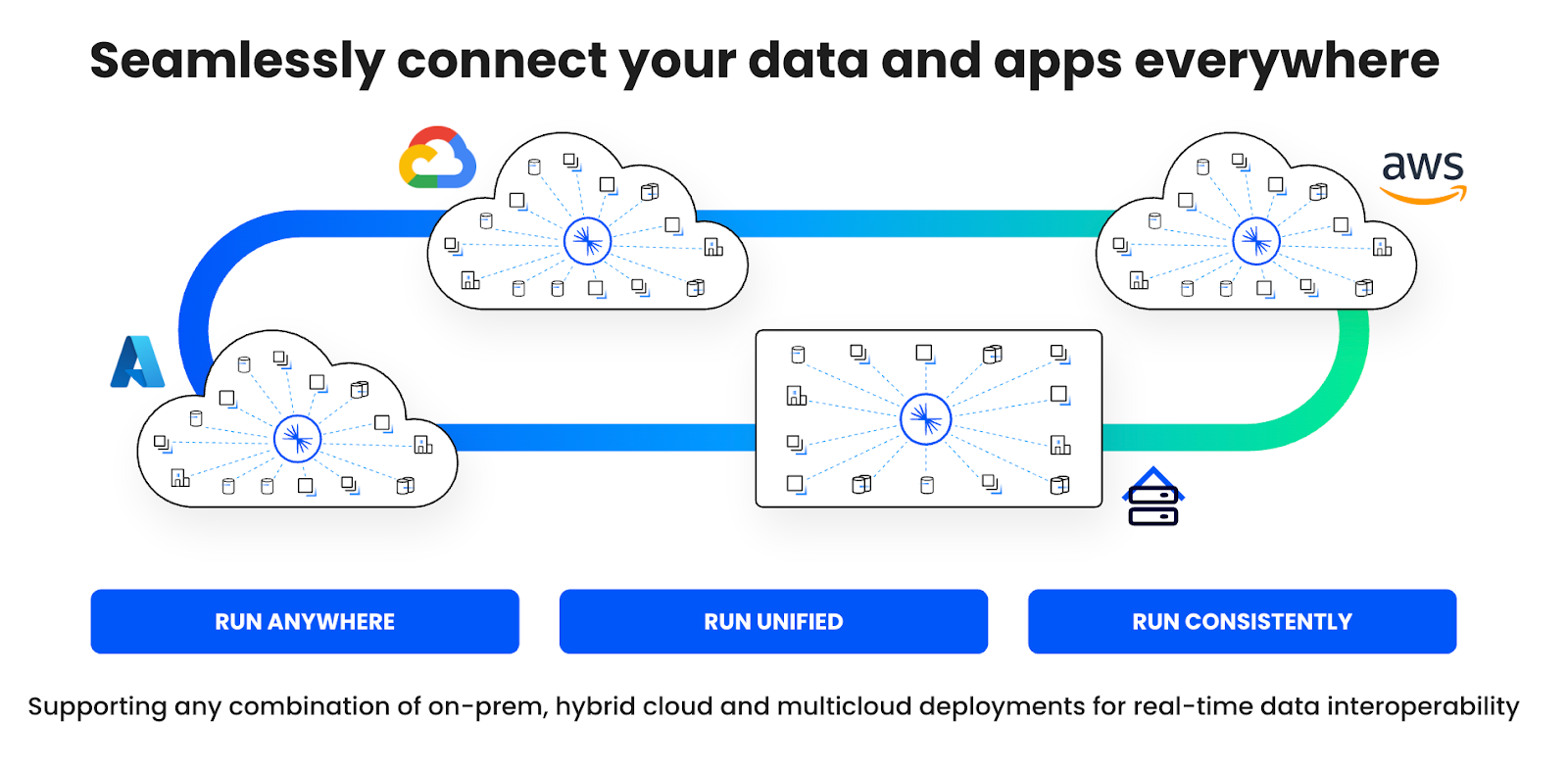
Hybrid & Multicloud With Confluent vs Vendor Lock-In on AWS
Build for scale with cloud-native data streaming and without being locked into a single cloud provider. Unlike Amazon MSK (available only on AWS), Confluent gives you true deployment flexibility to support any combination of on-premises, hybrid, and multicloud architectures for seamless data interoperability:
-
Consistent, fully managed service on AWS, Microsoft Azure, and Google Cloud
-
Cloud-native, self-managed data streaming with Confluent Platform
-
Control and cost-efficiency with WarpStream BYOC
Plus, Cluster Linking provides a persistent bridge to sync data between any environment in real time.
Get a Personalized Cost Savings Estimate
Get a customized cost comparison to see your savings with Confluent Cloud vs Amazon MSK. Fill out the contact form with your information and a member of our team will be in touch to help you calculate your savings with Confluent and answer your questions.
Not ready to talk to sales? Explore related resources:
Confluent Cloud vs. Amazon MSK: FAQs
Is Confluent Cloud more cost-effective than Amazon MSK?
Yes, Confluent Cloud is more cost-effective than Amazon MSK because of cost savings from:
-
Reduced infrastructure costs: Confluent Cloud’s serverless, cloud-native architecture eliminates the need for over-provisioning that is common with MSK’s node-based pricing. Features like Infinite Storage and Tiered Storage decouple compute and storage, further reducing infrastructure spending. For example, SecurityScorecard saved over $1M in infrastructure and operational costs by migrating to Confluent Cloud
-
Lower operational overhead: Offloading complex and time-consuming operational tasks—such as capacity management, scaling, and upgrades—to Confluent Cloud allows you to reallocate valuable engineering resources to innovation instead of infrastructure management. One customer reported they would have needed to hire at least 10 more people to manage Kafka themselves.
-
Minimized downtime and risk: Confluent Cloud offers a 99.99% uptime SLA for production workloads. Compared to MSK (with a 99.9% SLA with exclusions for Kafka failures and customer configuration failures), Confluent’s SLA delivers higher reliability and reduces the substantial hidden costs associated with downtime.
Choosing Confluent Cloud can reduce your self-managed Kafka costs by 40-70%.
What are the main cost drivers of Confluent Cloud vs Amazon MSK?
The main cost drivers of Confluent Cloud are:
-
Usage based consumption: Confluent Cloud’s pay-as-you-go pricing is based on actual usage (e.g., throughput) rather than provisioned infrastructure. This pay-as-you-go model eliminates the need for over-provisioned, underutilized clusters that typically lead double the infrastructure costs for self-managed Kafka vs fully managed on Confluent.
-
Managed horizontal scaling: Elastic Confluent Units for Kafka (eCKUs) are a Confluent Cloud’s unit of horizontal scalability for billing. eCKUs autoscale up and down based on workload. The cost includes the complete management of the platform, from infrastructure and scaling to monitoring and support, which is designed to reduce or eliminate the separate operational and support costs customers would otherwise incur.
The main cost drivers of Amazon MSK are:
-
Higher infrastructure spend: MSK uses node-based pricing, requiring users to pay for provisioned compute and storage, which often leads to over-provisioning to handle peak loads. Networking, particularly cross-Availability Zone (cross-AZ) traffic, can also become a significant hidden cost, sometimes accounting for 80-90% of total infrastructure expenses.
-
Self-managed operations and management: Since MSK is not a fully managed Kafka service, significant engineering resources are required for manual tasks like sizing, scaling, rebalancing partitions, patching, and monitoring. This includes the cost of hiring and retaining specialized Kafka talent.
-
Custom development and maintenance: MSK requires significant custom platform development and maintenance, which can take 2+ years to bring to production and cost $3-5M or more in costs. Because MSK is a hosted service rather than a complete platform with essential components included out-of-the-box, engineering teams must spend valuable time and resources building and maintaining their own solutions for developer tools, DevOps automation, infrastructure enhancements for reliability and disaster recovery, monitoring, integration, security controls, and governance.
-
Unplanned downtime and higher business risk: MSK's 99.9% SLA excludes failures in the underlying Kafka software, as well as failures due to customer errors in configuration, leaving customers responsible for resolving failures that can easily turn into major outages. The risk of outages due to storage limitations, manual scaling errors, or unresolved bugs can lead to substantial hidden costs, including lost revenue and reputational damage.
What are the pros and cons of MSK Serverless vs Confluent Cloud?
Confluent Cloud pros and cons include:
-
Pro: Confluent Cloud offers a complete, serverless experience that automates all operational aspects, from capacity planning and elastic scaling (to GBps+) to upgrades and monitoring.
-
Pro: Confluent Cloud goes far beyond core Kafka, providing a rich ecosystem of 120+ connectors, serverless Flink for advanced stream processing, and an enterprise-grade Stream Governance suite.
-
Pro: Confluent Cloud delivers significant cost savings through cost-efficient autoscaling and usage-based consumption (which prevents overprovisioned and underutilized clusters and cuts infrastructure costs by 50%+), lowers TCO 40-70% compared to self-managed Kafka by eliminating $1M in development and operations costs over 3 years, and with a 99.99% uptime SLA that reduces business risk.
-
Con: For smaller teams, projects with predictable workloads, or organizations that already have in-house Kafka expertise, Confluent's fully managed service and advanced features may not present a clear upfront financial advantage.
MSK Serverless pros and cons include:
-
Pro: MSK Serverless addresses some of MSK's operational challenges with pre-provisioning
-
Pro: MSK Serverless can elastically scale to a given quota without the need for manual rebalancing.
-
Pro: MSK Serverless offers unlimited storage (with a per-partition quota) without the manual configuration required by MSK Standard brokers.
-
Con: MSK Serverless has a strict throughput limit of 200MBps ingress and 400MBps egress, with no upgrade path for workloads that exceed this.
-
Con: MSK Serverless lack many mission-critical components, including a rich connector ecosystem, integrated stream processing (like Flink), and comprehensive, enterprise-grade security and governance tools.
-
Con: MSK Serverless has the same weak 99.9% SLA as MSK Provisioned, which does not cover Kafka-related failures.
-
Con: Like all MSK offerings, MSK Serverless has no multicloud support and is locked into the AWS ecosystem.
How does Confluent Cloud autoscale throughput compared to MSK?
Confluent Cloud offers true elastic, automated scaling from 0 to GBps, while Amazon MSK's elastic scaling capabilities are more limited and manual:
-
Confluent Cloud provides fully managed, automated, and elastic scaling. It can automatically scale clusters up and down from 0 to GBps+ to meet demand without interruption. Its cloud-native Kora engine uses an intelligent control plane and self-balancing algorithms to manage capacity, rebalance partitions, and eliminate the need for overprovisioning and underutilizing clusters to avoid outages. As a result, customers can save 50% or more on infrastructure costs.
-
Standard clusters on MSK Provisioned require manual sizing, scaling, and rebalancing. While you can add brokers to scale up, you cannot easily scale down and are more likely to have a large number of overprovisioned clusters at any given time. Modifying storage capacity can take anywhere from 6 to 24 hours. Express clusters on MSK Provisioned offer faster scaling and rebalancing, but it is still a manual process.
-
MSK Serverless offers some autoscaling but only within a lower quota limit (up to 200 MBps ingress and 400 MBps egress). There is no solution to upgrade beyond this quota without moving to a different offering.
How do Confluent and MSK differ in cluster provisioning speed?
Confluent Cloud can provision clusters in minutes, whereas provisioning an Amazon MSK cluster can take from 30 minutes to over an hour.
Is Confluent Cloud more reliable and performant than MSK?
Yes, Confluent Cloud is architected to be more reliable and performant than Amazon MSK and significantly reduces the risk of unplanned downtime compared to MSK:
-
Confluent's Kora engine provides native resilience with continuous monitoring, proactive replacement of degraded nodes, and automatic rebalancing to maintain availability without operator intervention. MSK lacks these native self-healing capabilities, requiring customers to manually identify and replace failed brokers.
-
Confluent Cloud offers a 99.99% uptime SLA that covers all components, including Kafka-related failures. This translates to a maximum of 0.876 hours of downtime per year. Amazon MSK offers a 99.9% SLA (a maximum of 8.76 hours of downtime per year), but that SLA explicitly excludes failures caused by the underlying Apache Kafka or Zookeeper software, placing the burden of resolving these critical issues on the customer and significant increasing the actual maximum hours of downtime per year MSK customers may experience.
Which platform offers stronger developer tooling, Confluent Cloud or Amazon MSK?
Confluent Cloud offers significantly stronger and more comprehensive developer tooling than Amazon MSK:
-
Confluent Cloud provides a robust Terraform provider that allows developers to manage both control plane resources (like clusters and Schema Registry) and data plane resources (such as Topics and ACLs). This enables complete automation of infrastructure deployments as code. Amazon MSK offers more limited IaC capabilities, as its Terraform support can only manage control plane resources. Managing data plane resources requires building custom operators and processes.
-
Confluent Cloud offers a rich set of APIs for point-and-click operations and automation. It also provides a user-friendly and intuitive cloud UI that allows developers to easily manage and monitor their Kafka clusters and data streams. MSK does not have a dedicated Kafka UI and developers must often build their own tools on top of MSK’s APIs. For example, MSK lacks a native REST proxy for non-Java clients, a feature available in Confluent.
-
Confluent Cloud supports multi-language client development, providing client libraries for several non-Java languages including C/C++, Go, Python, and .NET. Users can generate the necessary configuration details (including cluster credentials and API keys) directly from the Confluent Cloud Console and paste them into client application code. Amazon MSK also supports non-Java clients but enabling them to interact with MSK requires some additional work when setting up and configuring the clients for authentication and authorization.
Does Confluent Cloud offer better support than Amazon MSK?
Yes, Confluent provides customers with guidance from the world's foremost Kafka experts. Confluent was founded by the original co-creators of Kafka, and its support and professional services teams have millions of hours of Kafka experience. MSK support is limited and does not have the same depth of Kafka-specific knowledge.
What are the feature differences around connectors and schema management?
Confluent Cloud provides 120+ pre-built connectors and 80+ fully managed connectors, enabling instant integration with a wide range of popular data sources and sinks both inside and outside the AWS ecosystem. In contrast, Amazon MSK has very limited connector support. It offers fewer than 10 direct or "half-supported" integrations and primarily provides just the underlying Connect infrastructure, requiring users to bring, manage, and maintain their own connectors. This results in additional operational burden and cost. In fact, Confluent offers instant, fully managed connectivity to more native AWS services than Amazon MSK does.
Confluent Cloud includes Stream Governance, a comprehensive, fully managed suite that provides Schema Registry, Data Portal, Stream Lineage, and Data Quality Rules. With features like broker-side schema validation and the ability to tag data containing personally identifiable information (PII), your data streams are discoverable, trustworthy, and secure. Amazon MSK integrates with AWS Glue Schema Registry but lacks a full suite of governance tools, such as schema validation, data lineage, or a data catalog.
Does Confluent Cloud support multicloud deployments?
Yes, Confluent Cloud supports multicloud deployments. It is designed for both multicloud and hybrid environments, whereas Amazon MSK is an AWS-only service. Confluent customers can use its fully managed Kafka service on all three major public clouds and use its Cluster Linking feature to replicate data across clouds.