[Webinar] AI-Powered Innovation with Confluent & Microsoft Azure | Register Now
Confluent’s Customer Zero: Supercharge Lead Scoring with Apache Flink® and Google Cloud Vertex AI, Part 1
At Confluent, we continuously strive to showcase the power of our data streaming platform through real-world applications, exemplified by our Customer Zero initiative. In part 1 of this blog, we present the latest use case of Customer Zero that harnesses the capabilities of generative AI, data streaming, and real-time predictions to enhance lead scoring for sales, helping our team prioritize high-value prospects and address complex challenges within our organization. In part 2, we'll dive into the detailed setup of Google Cloud Vertex AI and Apache Flink on Confluent Cloud.
By integrating these advanced technologies, we not only enhance our operational efficiency but also pave the way for innovative solutions that can dynamically respond to customer needs.
Open preview of model inference
Confluent has recently announced the open preview of the AI Model Inference for Apache Flink, which opens up a whole new paradigm for Flink SQL on Confluent Cloud. It’s now possible to invoke generative AI endpoints such as OpenAI, Amazon Bedrock, Vertex AI, and custom ML models hosted on AWS, Google Cloud, and Azure directly from Flink SQL statements. You can utilize models as resources in Flink SQL, similar to tables and functions, by creating a model resource and using it for inference in streaming queries.
AI Model Inference empowers enterprises to harness the potential of machine learning by seamlessly integrating with existing data architectures. Together with Confluent's robust architecture, businesses can implement generative AI applications that are responsive to real-time data flows. We can achieve greater efficiency and creativity, revolutionizing our approach to data-driven decision-making and customer engagement.
Lead scoring use case
Effective lead scoring is essential for optimizing sales efforts and maximizing conversion rates in today's fast-paced business environment. This project focuses on leveraging Confluent Cloud's powerful data streaming capabilities in conjunction with Vertex AI to deliver real-time lead scoring predictions. By integrating these technologies, businesses can enhance their ability to identify high-value leads and prioritize them based on predictive insights.
Real-time lead scoring not only enhances the efficiency of sales teams but also fosters a more data-driven culture within the organization. With accurate and timely insights, sales professionals can focus their efforts on leads that are more likely to convert, which drives overall business growth. This project ultimately aims to empower you to harness the full potential of your data, enabling smarter decision-making and enhanced customer engagement.
The challenge
Traditional batch ETL processes have long been the backbone of data management in many organizations, but they come with a significant drawback, especially in the context of lead scoring: they’re slow. In a batch-oriented workflow, data is usually refreshed on a daily basis or even less frequently. This delay means that sales teams often operate with outdated information, making it challenging to respond to leads in a timely manner. In a fast-paced business environment, where every moment counts, this lag can result in missed opportunities.
The limitations of traditional batch ETLs highlight the urgent need for a more dynamic approach to lead scoring, one that leverages real-time data to empower sales teams and drive business growth. The question is, how can Confluent help you?
The solution
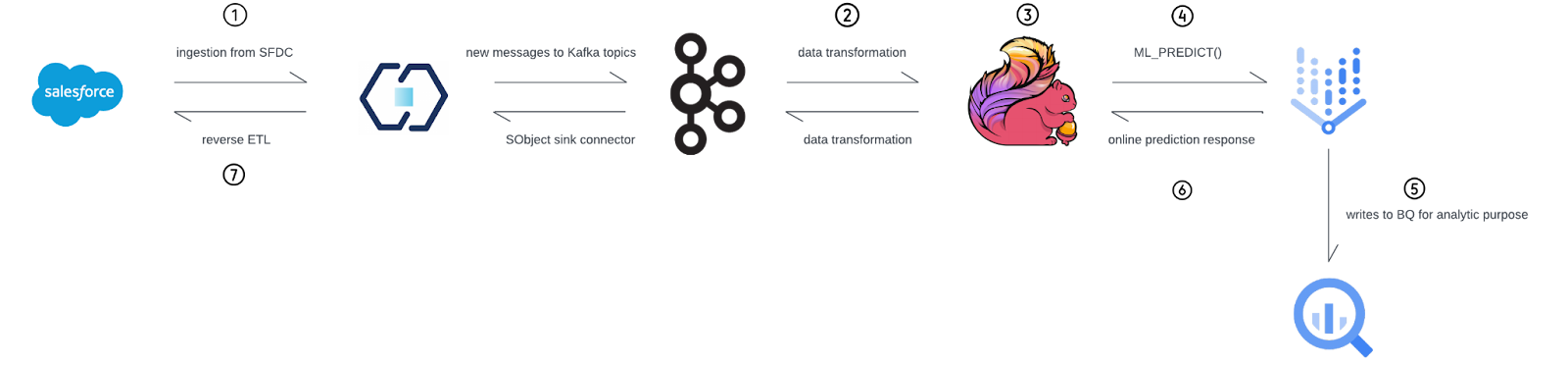
Ingest data from SFDC using Confluent connectors.
The Confluent sales team relies on Salesforce for operational needs, such as managing customer relationships, tracking sales activities, etc. Therefore, the project begins with the ingestion of leads and contacts from Salesforce. Using the Salesforce Bulk API 2.0 Source Connector on Confluent Cloud helps to load the needed data into Apache Kafka® in real time.
Transform data with Flink and prepare it for Vertex AI.
Next, the Flink tables are automatically created once data is loaded into Kafka. We then need to do some data filtering and processing for it to be clean and ready to use for Vertex AI. Flink's powerful stream processing capabilities enable us to apply complex real-time transformations to incoming data.
Use Flink to create a model resource.
With the transformed data ready, we can leverage Flink to create a model resource compatible with Vertex AI.
Call Vertex AI for real-time predictions.
Then, we can use Flink SQL to infer the model resource by creating an inference statement. The integration allows Flink to invoke these resources for real-time predictions as new data streams in. This capability ensures that sales teams receive immediate lead scores and insights based on the most current data, enabling them to prioritize their outreach effectively and improve conversion rates.
Write to BigQuery for analytical purposes.
We can save the raw and processed data to BigQuery so downstream users can do data analysis.
Receive prediction results, and process data.
We receive prediction results in real time in a new Kafka topic, and this allows for the immediate collection and analysis of lead-related information. We can process this data and make sure it’s ready to use for the Salesforce SObject Sink Connector.
Push results back to Salesforce in real time.
The final step in this seamless data flow is to push the results back to Salesforce using the Salesforce SObject Sink Connector for Confluent Cloud.
Key components deep dive
Vertex AI
Vertex AI is a comprehensive machine learning platform that enables businesses to build, deploy, and scale AI models efficiently. It also streamlines the development process, allowing us to harness the power of AI for a variety of applications.
Setting up and deploying a custom model on Vertex AI is an efficient process that allows organizations to leverage powerful machine learning capabilities tailored to their specific needs. In this project, KServe is used to build the model server for the following reasons:
Flexibility. If the default Serving Runtime doesn't meet your requirements, you can create your own model server using the KServe ModelServer API to deploy it as a Custom Serving Runtime on KServe. It offers great flexibility that caters to the various goals we hope to achieve with the model server.
Simplicity. KServe offers machine learning-specific template methods like preprocess, predict, and postprocess, allowing you to seamlessly deploy your model once you inherit them correctly.
All you need to do is:
Subclass kserve.Model.
Override the load, preprocess, and predict methods.
Below is a code sample of how to implement your custom model based on the two steps above. This is the only Python file that you need in this project.
A few things to keep in mind:
The output of the
preprocessmethod is passed to thepredictmethod as the input, which means they are executed in sequence.The general approach is to do data filtering and cleaning in the
preprocessmethod, and in thepredictmethod you should execute the inference for your model.
Of course, before running the server you need to have the model trained. There are many ways to train and validate your models, and many other authors have written good pieces on how to do that. We recommend you check out Vertex AI’s documentation on using AutoML and custom training to train your models, as the specifics are beyond the scope of this article.
After we’ve trained our model, we can package the model into a pickle file and upload it to Google Cloud Storage. We can then load the model and use it in the predict method. Below is a sample of how to do this:
Once the model is trained and the framework is set up, the next step is to prepare it for deployment. Deploying a model to an endpoint is straightforward with Vertex AI. Please check out this documentation for importing models to Vertex AI, and this documentation for deploying the model to an endpoint. Note: We'll dive into the details in part 2 of this blog.
After deploying the model as a REST endpoint, we can send a sample HTTP request to test if it returns the expected output.
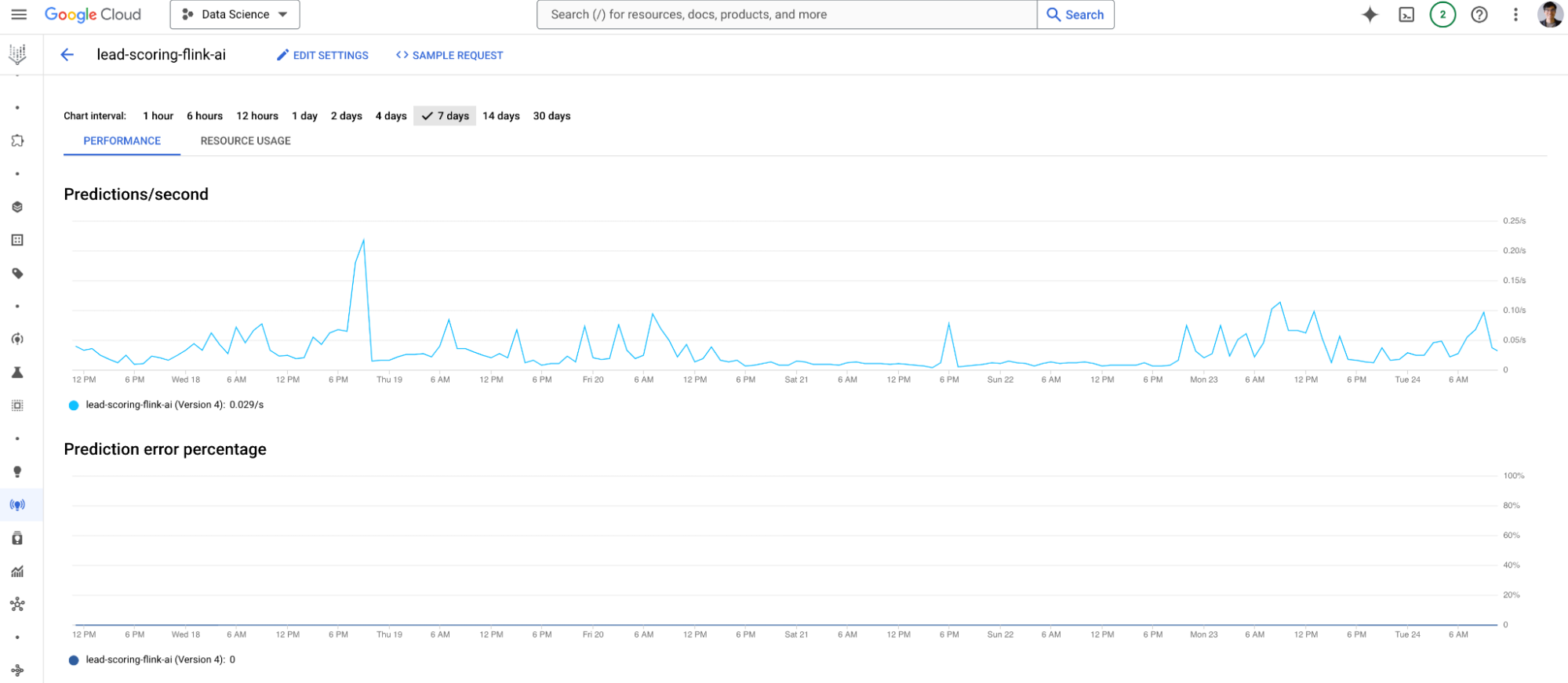
Moreover, Vertex AI offers comprehensive monitoring and logging capabilities, enabling teams to track the model’s performance in real time. This is crucial for identifying potential issues and ensuring that the model remains accurate and relevant over time.
Apache Flink
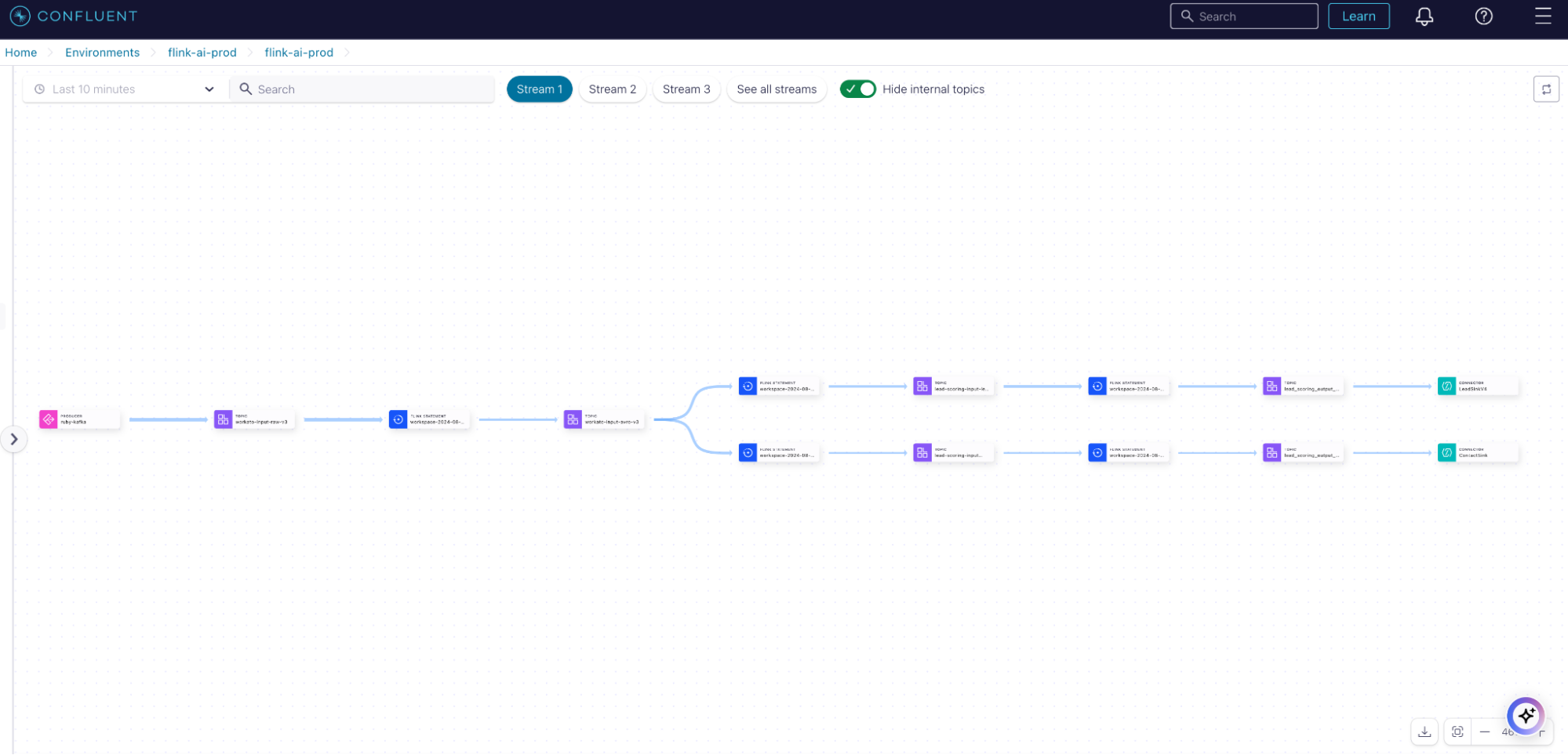
Apache Flink is a powerful stream processing framework designed for real-time data analytics and event-driven applications. Integrating Vertex AI with Apache Flink on Confluent Cloud creates a powerful ecosystem for real-time data processing and predictive analytics.
Let’s assume we have a raw topic called input_raw, which is connected to the connector for ingestion. The integration process begins by setting up Flink to ingest live data streams from various sources in Confluent Cloud. As data flows through the pipeline, we can use Flink’s SQL capabilities to perform complex queries and analytics.
Transform the schema from JSON (schemaless) to Avro in Flink.
The first step is to apply a schema to the JSON (schemaless) format data. This project uses Avro, and the below example shows how to convert JSON (schemaless) messages to Avro format using Apache Flink on Confluent Cloud.
This step changes the schema from JSON to Avro, and inserts it to a topic called
input-avro. Now the data in theinput-avrotopic will have an Avro schema and it’s ready to use.Filter the messages using Flink SQL.
We can then filter the messages and process them depending on our needs. In this case, suppose we have two types of leads we want to distinguish, we can insert them into different topics.
Create a model resource.
Now we can create a model resource in Flink. There are a few requirements to note:
Vertex AI doesn’t use API keys. Instead, you must have a service account with the
aiplatform.endpoints.predictIAM permission for the model resource.You must create a service account key for this service account.
First, we need to set up a connection to Vertex AI. Confluent uses connection resources for secret handling; please refer to the documentation for more information.
Once the connection is set up, we can follow the below statements to create the model resource which integrates with Vertex AI:
So now we’ve created a model called
your-model-name. Once the data is preprocessed, it can be fed directly into Vertex AI models, allowing for real-time predictions. This is where the synergy truly shines: Flink can invoke the model resource hosted on Vertex AI, making predictions on streaming data as it arrives.Create the inference statement.
Now, we can create the inference statement which feeds data into Vertex AI.
We do a couple of things here:
First, we use Common Table Expressions (CTEs) to define a temporary relation called
base. It allows us to give a sub-query block a name, which can be referenced within the main SQL query.Then, we only select the output columns that are useful to us, which are col1_out, col2_out, col3_out and col4_out.
Finally, we insert the results to the output topic called
result-topic-1, where we can choose to push it back to Salesforce, a data warehouse (for example, Google Cloud BigQuery or Snowflake), or to power other applications.
In this use case, we created two inference statements to separate the traffic for Lead and Contact from Salesforce, so the predicted results will be in two different topics. This is required by the Salesforce SObject Sink Connector as of now, because one connector can only handle one SObject.
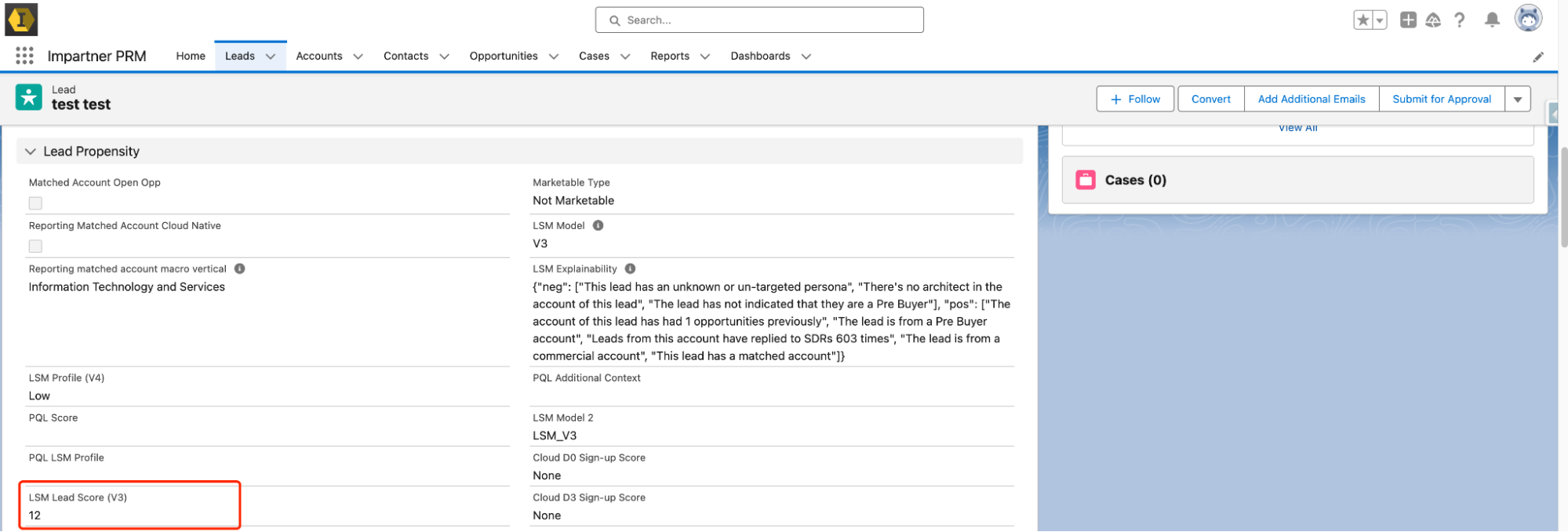
Now with the workflow set up, we can see Salesforce has the prediction score ready to use. You can also customize other fields (for example: the explanation of the score) in the lead scoring process to better align with your specific business needs, as long as these adjustments contribute to more accurate and effective lead prioritization.
The end-to-end latency is less than 10 seconds on average, which means the sales team can act swiftly after a potential lead is identified in our system!
In summary, integrating Vertex AI with Apache Flink on Confluent Cloud empowers us to leverage the best of both worlds: real-time data processing and advanced machine learning. This integration not only enhances the speed and accuracy of predictions but also fosters a data-driven culture, enabling businesses to make informed decisions quickly and effectively.
Conclusion
The integration of Confluent Cloud, Apache Flink, and Vertex AI unlocks real-time AI model inference for modern businesses, enabling real-time AI insights from data streams. As we continue to leverage these technologies, we can optimize our lead scoring efforts, ensuring sales teams have access to accurate and timely information to boost conversion rates. This process also fosters a more data-driven sales strategy, ultimately improving customer engagement.
Unlock the power of generative AI
Confluent and Google Cloud help you build intelligent, data-driven applications with real-time streaming. Break silos, boost data reusability, and accelerate AI innovation. Start free today with Confluent and Vertex AI to transform your business.
Apache Flink® and Flink are trademarks of the Apache Software Foundation.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Flink AI: Real-Time ML and GenAI Enrichment of Streaming Data with Flink SQL on Confluent Cloud
Confluent Cloud for Apache Flink®️ supports AI model inference and enables the use of models as resources in Flink SQL, just like tables and functions. You can use a SQL statement to create a model resource and invoke it for inference in streaming queries.


{kind=link}
{kind=link}
{kind=link}
{kind=link}

Why Is My Apache Flink® Job Not Producing Results?
An Apache Flink® job not producing results often indicates an issue with watermarks, which are necessary for handling out-of-order message processing in time-based aggregations from Kafka. Watermarks balance data loss and latency by defining how long to wait for late messages. Incorrectly setting...