[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Building Streaming Data Architectures with Qlik Replicate and Apache Kafka
A fundamental challenge with today’s “data explosion” is finding the best answer to the question, “So where do I put my data?” while avoiding the longer-term problem of data warehouses, data lakes, cloud storage, and NoSQL databases…places where “big” data often goes to die.
Data inevitably must come to rest at some point. If you’re not careful, data can get lost or become stale wherever it lands. Today’s architectures—particularly those constructed in the cloud—are frequently built using data pipelines where downstream consumers of information make use of data generated upstream, essentially expecting the data to be in motion as it moves from stage to stage. This blog post explores how data that has come to rest can be put in motion again; how Apache Kafka® and Confluent can keep it in motion longer; and how pipelined architectures can be created to make use of that data.
Physics 101
Enter Physics 101 and a corollary to Newton’s first law of motion: Data in motion tends to stay in motion until it comes to rest on disk. Similarly, if data is at rest, it will remain at rest until some external “force” puts it in motion again.
Although there are solutions for data that comes to rest in files, most corporate data is transactional at its source, which implies that the data lands in a database somewhere. The problem is how to get that data moving again.
There are several ways that data can be retrieved from a database so that it may be sent onward to a downstream target:
- If the data happens to land in a file rather than a database, you can simply perform direct reads against the file. The challenge is that you must parse the data yourself; and a much larger issue is that delta processing (identifying changes that might have occurred since your last read) is hard except at file boundaries. The devil is truly in the details where failure and recovery are concerned.
- When data lands in a database, the most basic way to access that data is via a query. There is nothing wrong with a database query in the right context, but there are issues when used at the frontend of a data pipeline:
- There is a disconnect between a query and the desire for real-time data in a data pipeline. Absent some sort of context column(i.e., a modification timestamp), delta processing is impossible.
- Queries put additional load on the database, impacting performance for upstream users. Using queries to push data along to the next stage of a data pipeline can quite literally bring a database to its knees.
- It is possible to identify recently changed rows by creating INSERT, UPDATE, and DELETE triggers against each table you want to capture and move onward from there. As with queries mentioned above, database triggers bring along their own baggage:
- Triggers can put a huge amount of load on a database; firing a trigger with each database update can have a huge impact on a database processing production data volumes.
- It is common to write data that has been captured in this fashion into a shadow table. Shadow tables are used as a staging area for changed data, allowing the data to queue until it is processed while also providing some robustness in terms of restart and recovery. The problem is that not only do shadow tables increase storage requirements in the database—they also put increased load on the database: Each changed row must be written to the shadow table; retrieved from the shadow table and processed; and then deleted from the shadow table so that data isn’t reprocessed again later.
- There are many traditional ETL (extract, transform, and load) tools on the market. They typically provide a nice GUI and have powerful transformation engines that can augment data in rows that are retrieved from the database and even perform complex aggregations. This sounds good in theory, but in pipelined architectures, you typically see this sort of processing at
another stage in the pipeline—closer to where the data is needed rather than at the source. Furthermore, when you peel back the layers of the ETL “onion,” ETL tools do their work by performing queries against the source database and even sometimes by writing data back to the source database. In short, ETL tools have all the same issues highlighted previously: They are not real time; they put additional load on the source database; and identifying changed records is hard.
Real-time changes using Qlik Replicate
To retrieve changes made to a source database in real time with low impact, you can use Qlik Replicate. Qlik Replicate achieves this feat by monitoring the database’s transaction logs and retrieving changes to the database directly from the logs rather than issuing queries against the database.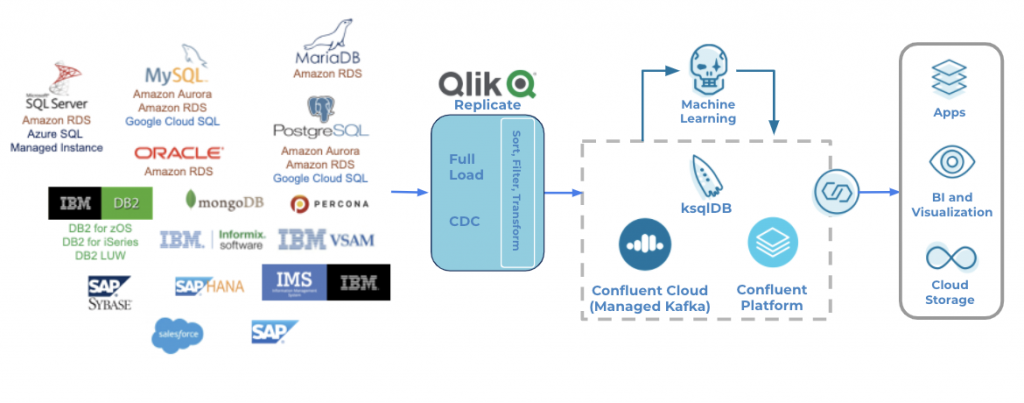 Qlik Replicate can capture data from over 30 sources, including on-premises and cloud-based relational databases, legacy platforms such as IBM z/OS and IBM iSeries, and applications such as Salesforce and SAP. It can deliver data in real time to Kafka and the event streaming architectures built on it, as well as many other supported targets.
Qlik Replicate can capture data from over 30 sources, including on-premises and cloud-based relational databases, legacy platforms such as IBM z/OS and IBM iSeries, and applications such as Salesforce and SAP. It can deliver data in real time to Kafka and the event streaming architectures built on it, as well as many other supported targets.
While there are other tools that provide ways to retrieve changes from a relational database, Qlik Replicate is different than most in that it is an enterprise-class solution that supports high-volume production loads (>100 GB of change data per hour and hundreds of tables); filters and transforms data in flight; supports the Confluent Schema Registry, creating the target schema automatically and handling changes to source DDL that occur after processing has begun; and perhaps most importantly performs log-based change data capture (CDC) against the sources it supports without requiring triggers or queries.
Making rubber meet the road
In this section I’ll step through the things that can be configured in a Qlik Replicate Kafka target: the broker server(s) to connect to; the security model, message format (JSON, Avro), message publishing (topic names, partitioning strategy), and use of the schema registry. If you’d like to see a live demo, check out the session I delivered at Kafka Summit: Data in Motion: Building Stream-Based Architectures with Qlik Replicate and Kafka.
First, begin by creating a Kafka target endpoint for Replicate:
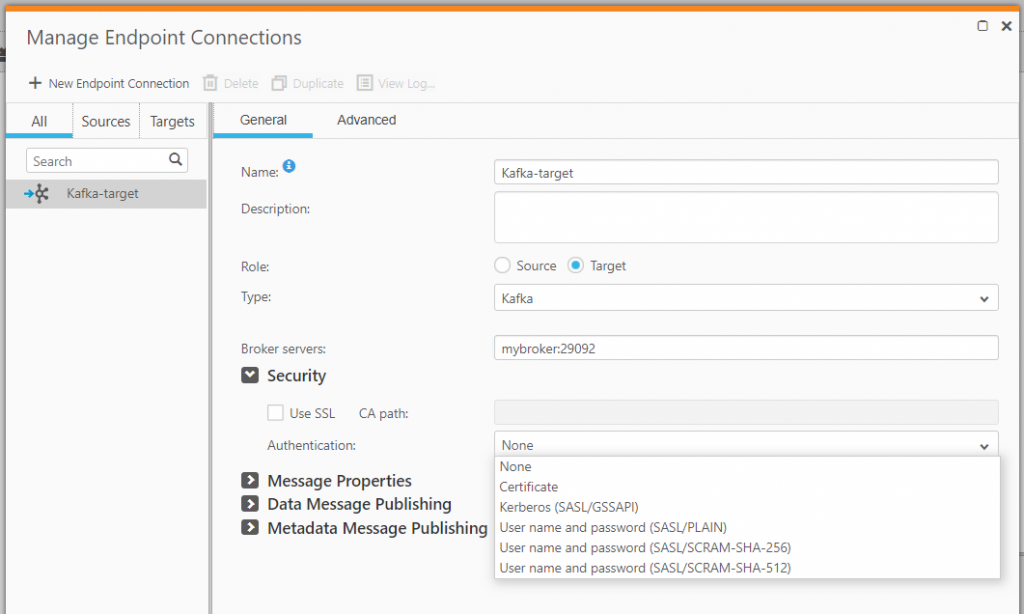
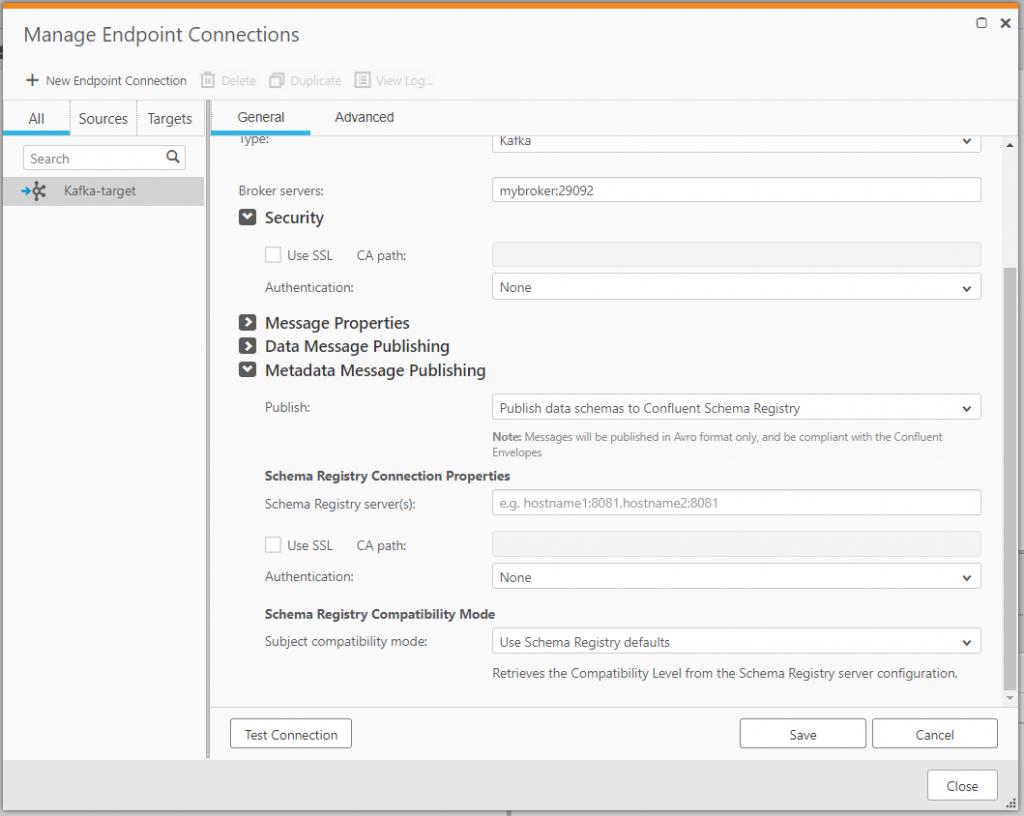
Then specify your Confluent server(s) and the security model for your environment.
Under message properties, you can configure Replicate to deliver JSON or Avro-formatted message payloads.
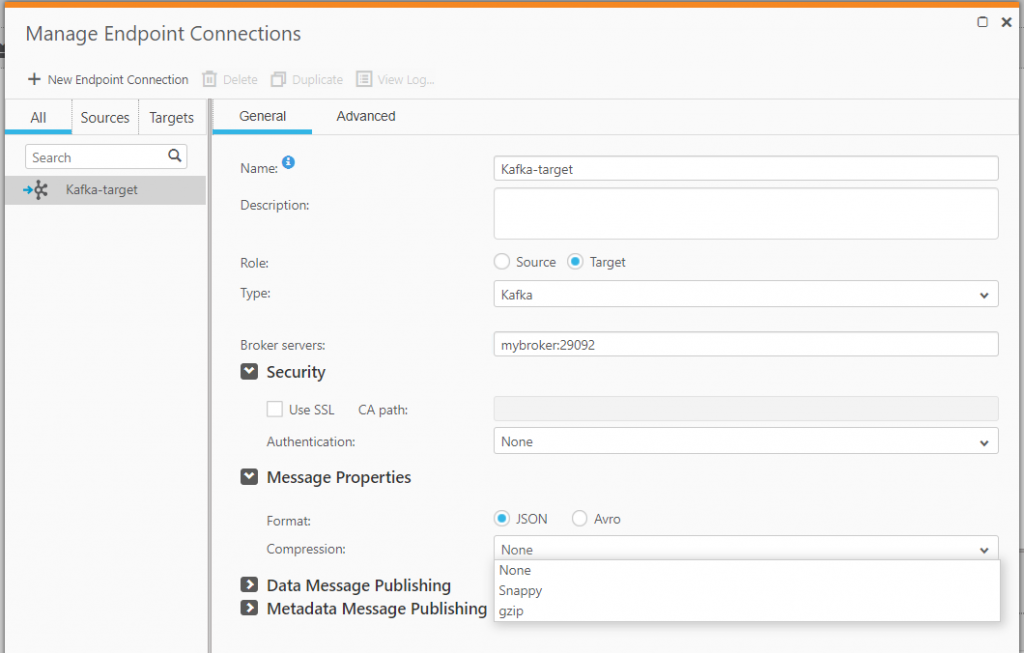
For data message publishing, you can specify a specific topic for Replicate to deliver all the data to, or you can have Replicate create a separate topic for each table. Here, you will also specify the partition strategy. Replicate supports Random and By message key. In most cases, Random is not recommended unless the source records generated only contain inserts. If there is a mixed workload that includes updates and/or deletes, there is a risk for messages to be processed out of order if you have multiple partitions. For this reason, By message key is preferred when working with transactional database sources.
When you select By message key, you can choose whether partitioning should be based on schema and table name or by primary key columns. Either is fine, but there are some advantages downstream to partitioning by table name. You should also be aware that if your data volumes are high and load is not evenly distributed across all the tables, you may find that some partitions are much hotter than others. Using the source table’s key columns tends to give you a better distribution across partitions.
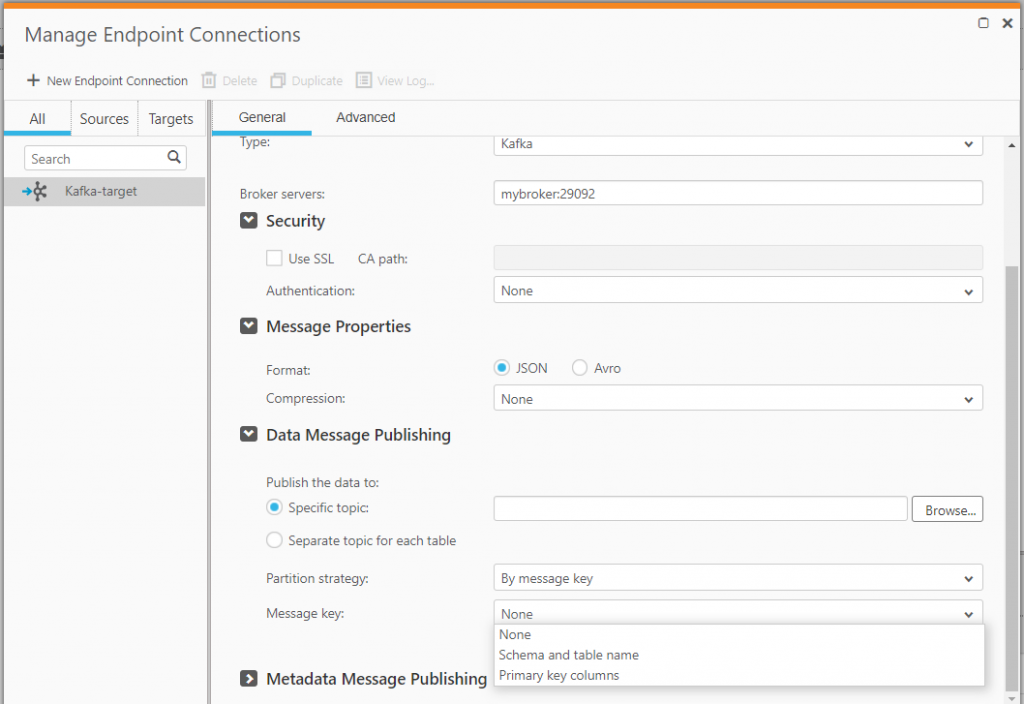
If you elect to use Avro-formatted messages, Replicate can deliver the Avro schemas to the Confluent Schema Registry. If you are using JSON payloads, this isn’t required, so you can leave the default setting (do not publish the metadata).
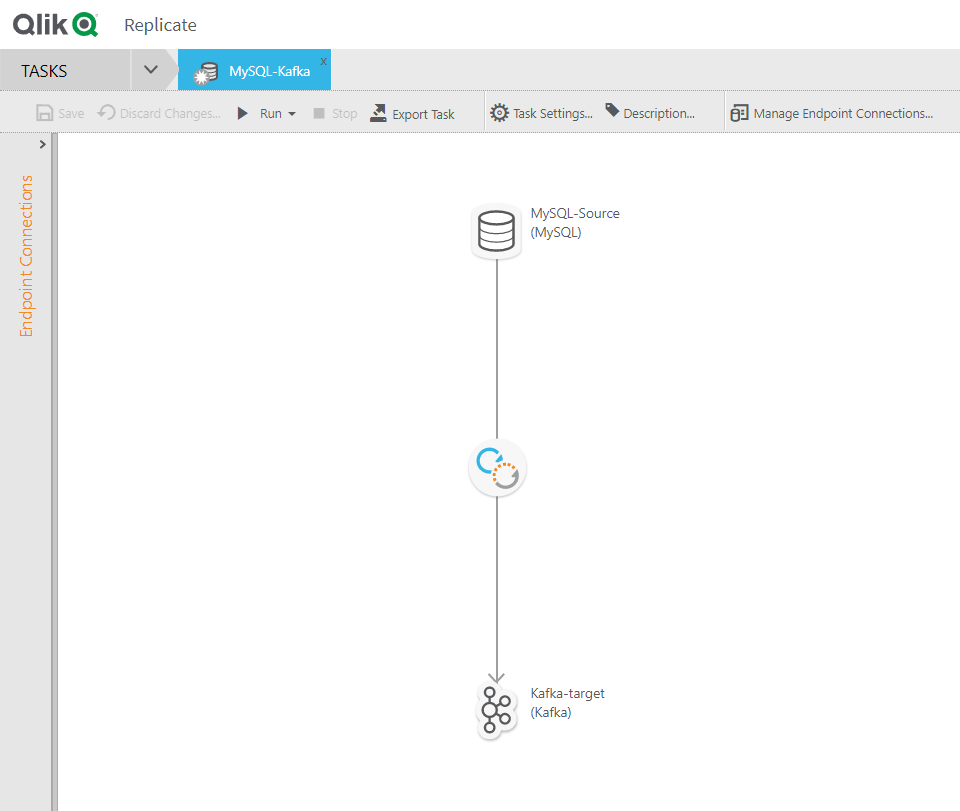
A Replicate task is a combination of a source and a target. In the example below, the task is configured to deliver data from MySQL to Kafka:
There is one more thing to be aware of: With Replicate, you can customize the message payload to conform to your requirements. By default, Replicate has sub-records that include header information such as operation type and timestamp, as well as a sub-record that is used in update operations and includes the original value of the columns (before they were updated). This information can prove useful downstream when coding business logic (i.e., if column X value changed from foo to bar, then fire this rule). You may choose to exclude either of these sub-records or even flatten the entire payload into one record with no sub-records.
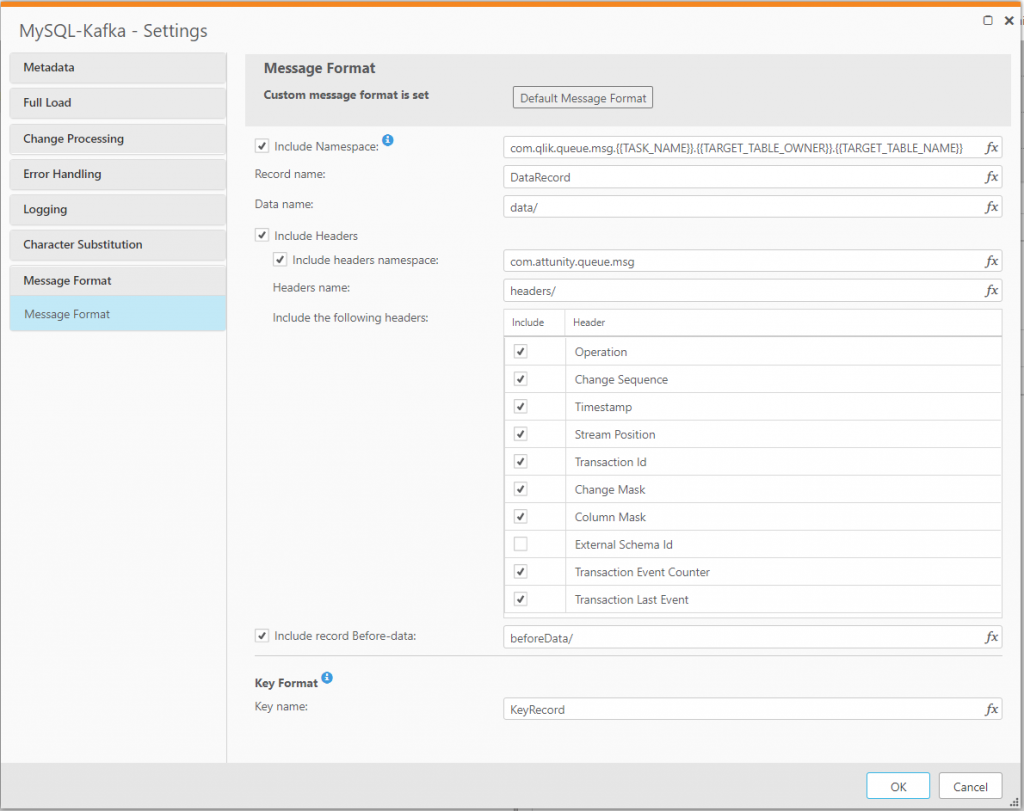
You can also configure Replicate to omit data columns from the message on a table-by-table basis.
Finally, here is a sample of a JSON-formatted record. In this case, you can see that it is an update record and includes the header and before data value sub-records discussed above.
{
"data": {
"playerID": "mayswi01",
"birthYear": 1931,
"birthMonth": 5,
"birthDay": 6,
"birthCountry": "NewCountry",
"birthState": "AL",
"birthCity": "Westfield",
"deathYear": "",
"deathCountry": "",
"deathState": "",
"deathCity": "",
"nameFirst": "Willie",
"nameLast": "Mays",
"nameGiven": "Willie Howard",
"weight": 170,
"height": 70,
"bats": "R",
"throws": "R",
"debut": "1951-05-25",
"finalGame": "1973-09-09",
"retroID": "maysw101",
"bbrefID": "mayswi01"
},
"beforeData": {
"playerID": "mayswi01",
"birthYear": 1931,
"birthMonth": 5,
"birthDay": 6,
"birthCountry": "USA",
"birthState": "AL",
"birthCity": "Westfield",
"deathYear": "",
"deathCountry": "",
"deathState": "",
"deathCity": "",
"nameFirst": "Willie",
"nameLast": "Mays",
"nameGiven": "Willie Howard",
"weight": 170,
"height": 70,
"bats": "R",
"throws": "R",
"debut": "1951-05-25",
"finalGame": "1973-09-09",
"retroID": "maysw101",
"bbrefID": "mayswi01"
},
"headers": {
"operation": "UPDATE",
"changeSequence": "20200713204536000000000000000110813",
"timestamp": "2020-07-13T20:45:36.000",
"streamPosition": "mysql
bin.000004:415943395:20:415951456:17592712139:mysql-bin.000004:412843032", "transactionId": "000000000000000000000004189B7BCB",
"changeMask": "000010",
"columnMask": "3FFFFF",
"transactionEventCounter": 10962,
"transactionLastEvent": false
}
}
A real-world example
Below is a production architecture that uses Qlik Replicate and Kafka to feed a credit card payment processing application. In this case, Kafka feeds a relatively involved pipeline in the company’s data lake. The Kafka stream is consumed by a Spark Streaming app, which loads the data into HBase. HBase is useful in this circumstance both because of its performance characteristics and because it can track versions of records as they evolve. From there a Spark application pulls data from HBase periodically and loads it into Hive, which in turn frontends a machine learning application. The machine learning application evolves the models it generates and feeds a Decision Service Engine (DSE) based on what it derives from the data stored in Hive. The DSE supports the payment processing application which makes the final determination on whether or not to approve a credit card transaction.
What is interesting about this architecture is the feedback loop that takes the decisions made by the payment processing application and feeds them back upstream to the database of record. That data is then captured by Qlik Replicate and fed back into the pipeline where it can be examined in the analytics applications and also affect future model generation fed to the DSE.
The use of feedback loops in streaming architectures is not uncommon, particularly those that involve machine learning steps. One or more feedback loops are created in the downstream pipeline, sending information to components further upstream. That upstream target is often the source database where Replicate once again captures the new data points and feeds them back into the pipeline to affect subsequent processing.
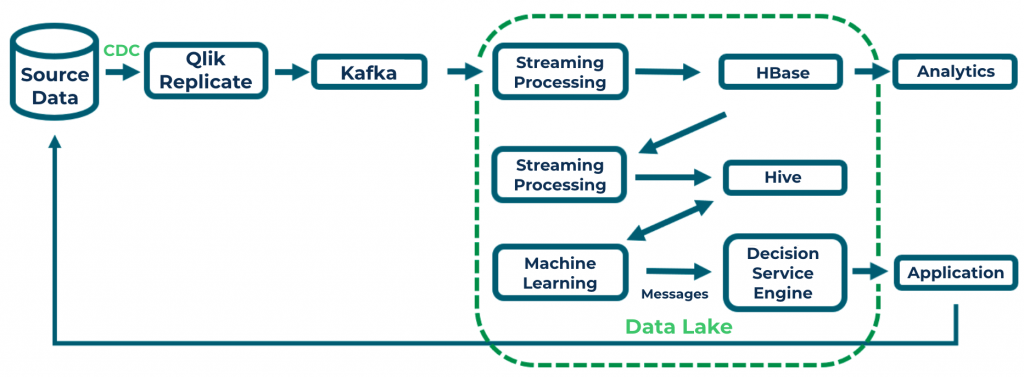
I would be remiss if I failed to mention that while this particular solution was built around a Hadoop-based data lake, this is not the only way that this architecture could have been implemented. All of the components in the data lake could be replaced with comparable bits from the Confluent Platform: with Kafka and ksqlDB replacing HBase, Hive, and Spark, and ksqlDB replacing the various arrows representing retrieval of data from storage.
Wrapping it up
When building stream-based architectures, it is important to keep in mind that much (and perhaps most) of the data that you will need downstream will likely come from a database rather than a streaming source. That data sourced from a database must be put in motion again, and how you do that matters. You can’t ignore the impact you might have on the source databases when retrieving that data. You also must be confident that your approach will scale in production environments where you might be sourcing hundreds—or thousands—of tables that are changing at high velocity. Finally, it has proven useful to include feedback loops in some solution pipelines such that upstream components can learn from decisions made downstream, helping to make data models more dynamic in the process.
To learn more, you can watch my Kafka Summit session, Data in Motion: Building Stream-Based Architectures with Qlik Replicate and Kafka.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


