[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Serverless Stream Processing with Apache Kafka, AWS Lambda, and ksqlDB
It seems like now more than ever developers are surrounded by a sea of terminology—but what does it really all mean? Here, we will take some often heard terms—some considered mere buzzwords—and show you how they aren’t just “marketing terms.” Instead, understanding them has the real power to help you achieve your development goals, faster and with minimum development and infrastructure management.
In this blog post, I’ll define what “serverless stream processing” is. A concatenation of two terms you likely have heard before, but not ones you’re likely to have seen put into action with an application. But this post is about more than just concepts and implementation. It describes arguably the most important pattern for building event streaming applications using ksqlDB. One where we separate stateful data operations from stateless business logic. A pattern that is common in traditional system design, but less well documented in streaming systems. The pattern is powerful though, as you will see.
But before we get into the details of implementing highly parallel workloads with a mix of serverless functions with event stream processors, let’s define the following terms upfront: stateless and stateful processing, Function as a Service (FaaS), and serverless.
Stateless and stateful processing
While these two terms certainly aren’t new, understanding the difference between them is more important than ever when it comes to deciding how to solve a given problem. Stateless processing is simpler and easier to reason about, for example, consider the Predicate interface in Java.
The invocation of the method Predicate.test(String value) returns true or false based on a given condition like value.equals(“success”). Calling this method with the same parameter multiple times will always yield the same result; in other words, it’s idempotent. But this type of functionality lacks context, so you can really only use it for tasks such as filtering out events from a stream. You can’t use this type of processing to make decisions for the current event based on previous events before it. For this type of processing, you need state.
Stateful processing is more complex because it involves keeping the state of an event stream. A basic example of stateful processing is aggregation. For each type of event, you need to keep track of the total number seen so far, for example, failed login attempts. Once a given userID accumulates enough failed login attempts, you’ll want the event streaming application to perform some sort of action. You can only perform this type of action in your application by keeping the state of previous events. Additionally, you’ll need state to perform enrichments, populating customer details in a stream of events with a customer-id field, for example.
The complexity rises with stateful processing because you need to have some sort of data store, probably a key-value store and preferably local to the event streaming application to reduce the latency of storage and retrievals. Additionally, you’ll need to have a fault tolerance plan in place to make sure the state can be quickly restored should the local store get wiped out. While there are solutions to meet these needs, ksqlDB remains our preferred choice and provides all this functionality and more out of the box.
Function as a Service (FaaS)
Function as a Service (or FaaS), loosely defined, is the ability to have a discrete chunk of code available to run in response to certain events. FaaS allows the developer to focus on a specific use case and write code targeted to solving that specific issue. Additionally, the targeted issue isn’t an ongoing affair, it’s something that may happen or occurs sporadically.
The idea is that you upload code and attach it to a triggering event, and your code only executes when it needs to. Otherwise, it sits dormant waiting for action, but, perhaps more importantly, you don’t incur any charges during the downtime, you only pay for function invocations and execution time. Here are some of the key parameters that define FaaS today:
- Fully managed (runs in a container pool)
- Pay for execution time (not resources used)
- Autoscales with load
- 0-1,000+ concurrent functions
- Stateless (mostly)
- Short-lived (limit 5-15 mins)
- Weak ordering guarantees
- Cold starts can be (very) slow: 100ms – 45s (AWS 250ms-7s)
Serverless
While the term serverless is not new, its meaning may still not be clear in the minds of developers. The term doesn’t mean that you can run an application without a server, but that your concerns are focused on the application and the application only. The developer does not have any concerns over infrastructure, once he/she builds the application, it gets deployed in an environment suitable to handle the expected load. This approach also has tremendous benefits for the business because it can focus on the core issues and not on the “ceremony” needed when self-hosting applications.
These terms may still feel a bit abstract, so let’s explore some more concrete examples that will be helpful later on in this blog.
ksqlDB
ksqlDB is a database purpose-built for streaming applications and allows you to develop an application that will respond immediately to events that are streaming into an Apache Kafka® cluster. ksqlDB provides you the ability to build an application with a “no-code” approach. Instead, you use something developers from a wide variety of backgrounds are familiar with: SQL. You can do stateless event stream processing, for example:
CREATE STREAM locations AS
SELECT rideId, latitude, longitude,
GEO_DISTANCE(latitude, longitude,
dstLatitude, dstLongitude, ‘km’
) AS kmToDst
FROM geoEvents
ksqlDB also allows you to do stateful processing. For example, if you take the stream from above you can create a stateful one to track longer train rides over ten kilometers.
CREATE TABLE RIDES_OVER_10K AS
SELECT rideId,
COUNT(*) AS LONG_RIDES
FROM LOCATIONS
WHERE kmToDst > 10
GROUP BY rideId
While these queries were simple to write, they shield you from a lot of processing power. Under the covers, there is a ksqlDB cluster that communicates with the Kafka cluster. Both can scale up to handle just about any volume of incoming events. In this way, ksqlDB is a good example of both stateless and stateful processing as well as serverless processing.
AWS Lambda
AWS Lambda is a serverless compute service that lets you run code without provisioning or managing servers and is the classic definition of FaaS. It’s also an integral part of the AWS Serverless Application Model (AWS SAM), a framework you can use to build serverless applications, which includes other components, as you’ll soon see. With AWS Lambda, you simply upload your code packaged as a zip file (or a container image, but we’re not going to cover that in this blog) and create a Lambda function definition, including the code to run and trigger mechanism. The Lambda service takes care of everything else such as scaling out the number of active instances when the load is high and determining the optimum amount of computing power needed for your code to get the job done.
Both ksqlDB and AWS Lambda deliver on the promise of serverless applications. With both technologies, you can strictly focus on achieving a specific business-related goal, without any concerns for how much computing power is needed, or how you’ll handle availability.
Division of labor
While both ksqlDB and the AWS Lambda are great examples of serverless compute services, both are not equally applicable to the different types of stateful and stateless workloads. ksqlDB is capable of doing both, but its strength lies in stateful processing to answer complex questions.
On the other hand, due to the nature of their transient processing, AWS Lambda is better suited for stateless processing tasks.
Given the strengths of both of these technologies, what about combining the two to solve a specific problem? While ksqlDB on Confluent Cloud comes with a wealth of built-in functions, no one tool can always solve any problem. Sometimes you need to engage with an external service, one that can respond to events found in a Kafka topic. Enter AWS Lambda, as it’s perfectly suited to this task.
Imagine you have a ksqlDB streaming application that checks for anomalies in an event stream of purchases. When the application determines that it’s found a suspicious event, it writes that event out to a topic. You’d like to notify the customer in question about the suspicious activity. To do so, you need to create an instance of a RequestHandler<I, O> from the AWS Lambda Java API (AWS Lambda supports several runtimes, but for the purposes of this blog we’re going to use Java).
Given that the majority of users should have activities that fall into expected use patterns, the somewhat infrequent need to notify users also plays to the strengths of AWS Lambda because charges only accrue when it’s used. AWS Lambda also easily supports spikes and sustained increases in the number of records. By now you likely understand the concepts at play with serverless, so let’s move on to a more concrete example.
A working serverless scenario
To solidify the concepts discussed so far there’s a full example available in this GitHub repository. The repo contains a complete end-to-end example of integrating a ksqlDB application with AWS Lambda for two-way communication; ksqlDB performs some work and writes the result to a Kafka topic. The Lambda function does some processing on the result and writes a new result back to a topic on Confluent Cloud. ksqlDB has additional long-running queries to analyze the results of the Lambda output.
The overall idea of the project is captured in this diagram:
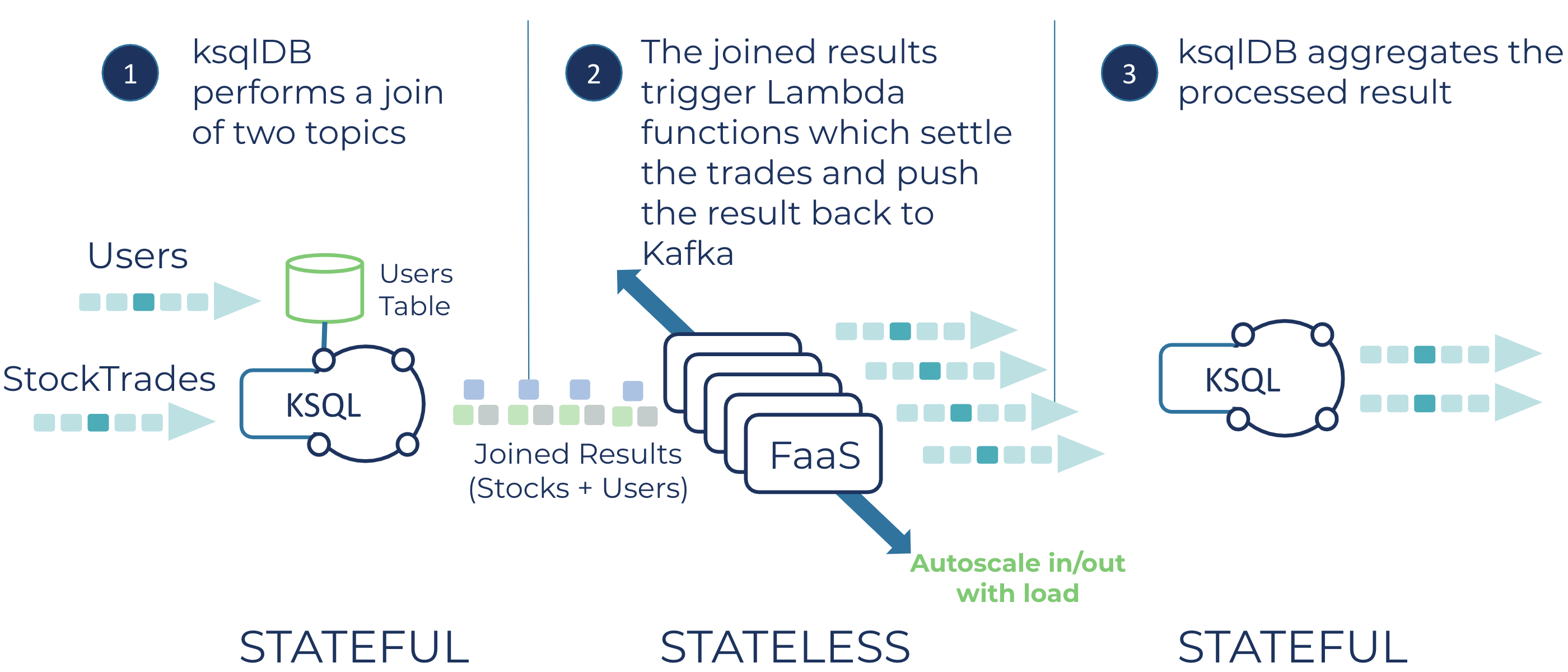
Description of the application flow
Now let’s take a look at the flow of the application from a high-level perspective.
The ksqlDB application runs on Confluent Cloud and leverages the managed Datagen connectors to create a stream and a table. The SQL for the stream looks like this:
CREATE STREAM STOCKTRADE (side varchar, quantity int, symbol varchar, price int, account varchar, userid varchar) with (kafka_topic = 'stocktrade', value_format = 'json');
The STOCKTRADE stream represents simulated stock trades. The SQL for creating the table that contains customer information (named USERS) takes the form of:
CREATE TABLE USERS (userid varchar primary key,
registertime BIGINT, regionid varchar )
with ( kafka_topic = 'users', value_format = 'json');
ksqlDB then performs a stream-table join:
CREATE STREAM USER_TRADES WITH (kafka_topic = 'user_trades') AS SELECT s.userid as USERID, u.regionid, quantity, symbol, price, account, side FROM STOCKTRADE s LEFT JOIN USERS u on s.USERID = u.userid;
The join enriches the stock trade data with information on the user executing the trade.
We use a left outer join so that we always have the trade information, regardless of if the user information exists at that point in time.
Let’s take a detour from the application overview and discuss one of the killer features of ksqlDB, stateful stream processing, or in other words, materializing a view of the streaming data in real time. ksqlDB uses an embedded state store, RocksDB, to persist records to local disk on the ksqlDB server. By using an embedded local store, ksqlDB can maintain a running status of the stream state by constantly updating the materialized view. Contrast this with a traditional database system where you’d have to use triggers to update the materialized view when an update occurs.
Additionally, ksqlDB ensures your state is durable through the use of changelog topics. When ksqlDB writes a stateful result to RocksDB, the same record is persisted to a changelog topic backing the store. Should the ksqlDB server experience a failure, thus losing the RocksDB store, data is not lost, it’s safely stored in a replicated changelog topic. So when a new ksqlDB instance starts to replace the failed one, it will replay all the data to populate its RocksDB instance and resume processing queries on the materialized view.
With the discussion of state complete, let’s return to the overview of the example application.
ksqlDB writes the results of the join to a topic named user-trades. This topic serves as the event source mapping for AWS Lambda. In this case, we’re using Lambda as a proxy for an external process—settling the trade. The Lambda code creates a Protobuf object, TradeSettlement, which contains four disposition types, Rejected, Pending, Flagged, and Completed, based on the information contained in the original stock trade transaction. Then Lambda produces the completed TradeSettlement object back to a topic in Confluent Cloud—named trade-settlements.
What’s described above just scratches the surface of what you can do from inside Lambda. You can also opt to:
- Write records to different topics, based on the disposition code
- Send emails directly to customers when the status of the trade is negative
- Contact a machine learning (ML) model to check the trade for fraud or suspicious activity
The point is, Lambda presents an opportunity for you to perform per-trade business logic without having to manage any of the infrastructure.
For the last leg of the serverless processing, the ksqlDB application creates a stream from the “trade-settlements” topic. This stream serves as the source for four tables that calculate the total number of results for each status over the last minute using a tumbling window. For example, here’s the SQL for determining the number of fully settled trades:
CREATE TABLE COMPLETED_PER_MINUTE AS SELECT symbol, count(*) AS num_completed FROM TRADE_SETTLEMENT WINDOW TUMBLING (size 60 second) WHERE disposition like '%Completed%' GROUP BY symbol EMIT CHANGES;
A final note about the reference implementation of this serverless application: It is set up so that it will create everything for you, the only step you need to take is to run the ccloud-build-app.sh script. This includes creating a cluster on Confluent Cloud, starting Datagen connectors to provide the initial data, starting a ksqlDB application and running the join query, and using AWS Lambda (via the AWS CLI). The README for the repository contains all the instructions and details of the various component’s working parts that the script creates.
Lambda – Kafka details
At this point, I’d like to cover some of the more important areas of the example application.
When to create a Kafka producer instance
As mentioned during the high-level application description, Lambda will produce records back to a topic on Confluent Cloud. Using a Kafka producer from within AWS Lambda is straightforward, but there is an important detail to consider.
When building a Lambda instance you can initialize any long-lived resources in the constructor, inline at the field level, or in a static initializer block. Any objects created this way will remain in memory and Lambda will reuse them, potentially across thousands of invocations. In the reference example the producer is declared at the class level and initialized in the constructor as shown below (some details left out for clarity):
public class CCloudStockRecordHandler implements RequestHandler<Map<String, Object>, Void> {
//Once initialized, producer is reusable for future invocations private final Producer<String, TradeSettlementProto.TradeSettlement> producer;
private final StringDeserializer stringDeserializer = new StringDeserializer();
public CCloudStockRecordHandler() {
producer = new KafkaProducer<>(configs);
stringDeserializer.configure(configs, false);By creating the producer instance this way, it’s used across executions for the life of the Lambda instance. It’s important that you never create a producer instance in the handler method itself, as this will create potentially thousands of producer clients and put an unnecessary strain on the brokers.
Configuration
When using Kafka as an event source for AWS Lambda, you need to provide the user name and secret for the Confluent Cloud Kafka cluster via an AWS Secrets Manager. Part of setting up a Confluent Cloud cluster is generating the key and secret to enable client access to the cluster (note that the accompanying application generates these for you).
But using the AWS Secrets Manager also presents an opportunity to store all of the sensitive information needed to connect to various components in the Kafka cluster such as endpoints and authentication for ksqlDB and Schema Registry. Placing all these settings in the Secrets Manager makes it seamless to configure the producer and any Schema Registry (de)serializers inside the Lambda instance.
The AWS SDK provides the SecretsManagerClient which makes it easy to programmatically retrieve the data stored in the Secrets Manager. Let’s take another look at the constructor for your Lambda instance:
public class CCloudStockRecordHandler implements RequestHandler<Map<String, Object>, Void> {
private final Producer<String, TradeSettlementProto.TradeSettlement> producer;
private final Map<String, Object> configs = new HashMap<>();
private final StringDeserializer stringDeserializer = new StringDeserializer();
public CCloudStockRecordHandler() {
configs.putAll(getSecretsConfigs());
producer = new KafkaProducer<>(configs);
stringDeserializer.configure(configs, false);
}
At the class level, you defined a HashMap named configs. Then in the constructor, you use the method getSecretsConfigs which leverages the SecretsManagerClient to retrieve all the necessary connection information and store it in the “configs” object. Now you can easily provide the required connection credentials to any object that requires them.
Kafka records payload
The Lambda service delivers records in batches (the default batch size is 100) to your RequestHandler instance via the handleRequest method. The signature of handleRequest consists of two parameters: a Map<String, Object> and a Context object. The “Map” contains a mix of object types for the values, hence the “Object” generic for the value type of the map. The “Context” object provides access inside the Lambda execution environment, such as a logger you can use to send information to AWS CloudWatch.
For our purposes, we’re most interested in the records key which points to a value of Map<String, List<Map<String, String>>>. The keys of the records map are the topic-partition names and the values are a list of map instances where each map in the list contains a key-value pair from the topic.
Notice that the types on the Map are String for both the key and the value. But this doesn’t represent the actual types of records from the topic. The Lambda service converts the key and value byte arrays into base64 encoded strings. So to work with the expected key and value types, you need to first base64 decode them back into byte arrays and then use the appropriate deserializer. In the case of this example, we’re expecting JSON, so it uses the “StringDeserializer.”
Ensuring message delivery
When executing the KafkaProducer#send method, the producer does not immediately forward the record to the broker. Instead, it puts the record in a buffer and forwards a batch of records when either the batch is full or when it determines it’s time to send them. When using a Kafka producer from within AWS Lambda, it’s important that you execute KafkaProducer#flush as the last action Lambda takes before exiting. Not doing so risks records that don’t get sent. But it’s important that you call flush only once at the end of the handler method (when you’ve fully processed the entire record batch) and not after each call to KafkaProducer#send. And it’s always a best practice to set acks=all to ensure record durability.
Scaling and performance
Building a serverless application including AWS Lambda also provides you with the ability to seamlessly scale in the face of increasing demand. This is maybe one of the best features of using a serverless platform; you simply write your code and the platform handles the rest. As the demand for computing resources grows, automatic horizontal scaling occurs to keep up with the processing needs.
AWS monitors the progress of the underlying consumer. Should the consumer begin to lag, AWS will create a new consumer and Lambda instance to help handle the load. Note that the maximum number of consumers is equal to the number of partitions. There is also only one Lambda instance per consumer, to ensure that all events in a partition are processed in sequential order.
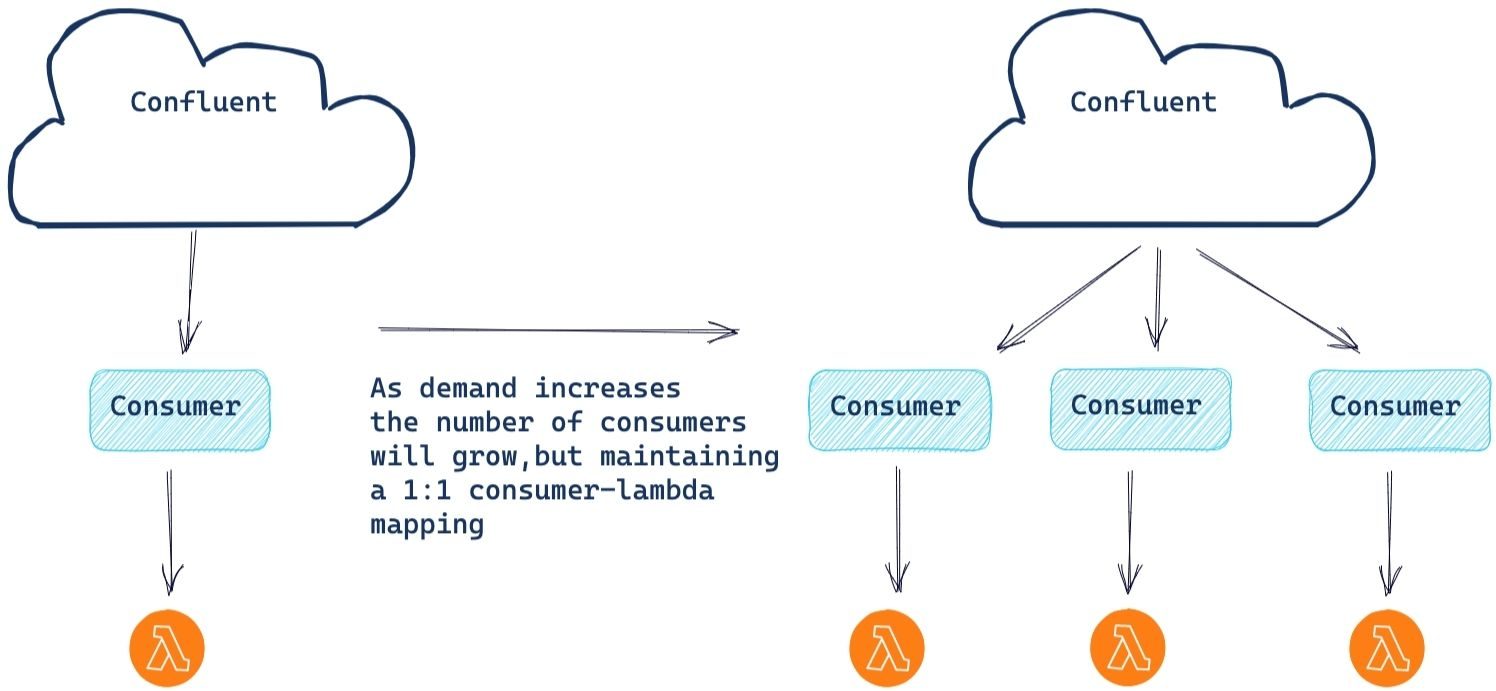
Currently, there is a soft limit of 100 consumers, hence 100 concurrent Lambda instances. If you need maximum parallelization above 100 instances, simply file a service ticket with AWS and they can increase the limit for you.
To that end, we wanted to see how this architecture would respond to a topic with 1,000 partitions, containing a large amount of records to process.
First, we coordinated with the AWS service team to have them set the concurrency limit to 1,000 Lambda instances. To force increasing horizontal scaling, we made changes to Lambda by first setting the batch size to 1 (definitely not a production value!) and adding an artificial wait of 5 seconds to the method handler code. These values were selected to simulate a high instance workload, without having to produce (and consume) billions of records. For our event data, we produced 50M records to a topic of 1K partitions, ensuring an even distribution of 50K records per partition.
With the test setup completed, we started the AWS Lamba instances and began the test. Initially, it started with one consumer and Lambda instance responsible for all 1,000 partitions. But at a rate of one record every five seconds (the maximum throughput achievable for our workload within a single thread), that’s a level of progress that isn’t sufficient and will force the Lambda service to take action. After the first rebalance (approximately 15 minutes into the test), 500 consumer Lambda pairs sprang into action, yielding a 500x processing improvement to 500 records every 5 seconds. Every few minutes (5-10) the Lambda service continually added Lambda instances, ultimately reaching the target number.
That’s 1,000 consumer-Lambda pairs working in concert. Now that’s some serious parallel processing! What started at one record per five seconds ended up with 1,000 records per five seconds, significantly increasing the progress made through the topic backlog. While this is a contrived example and doesn’t reflect a realistic production setting, it’s important to note that under a considerable increase of required processing power, this architecture has the elasticity to respond and meet those demands and then reduce capacity automatically after completing the surge in workload.
Conclusion
Now that you’ve learned how combining ksqlDB and AWS Lambda gives you a powerful, serverless one-two punch, it’s time to learn more about building your own serverless applications. Check out the free ksqlDB introduction course and the inside ksqlDB course on Confluent Developer to get started building a serverless event streaming application on Confluent Cloud.
Related Content
- Listen to the serverless stream processing podcast featuring Bill Bejeck on the Streaming Audio
- Check out the Serverless Stream Processing with Apache Kafka, AWS Lambda, and ksqlDB white paper
- Read AWS Lambda in Java and the AWS Lambda documentation for a full understanding of the Lambda landscape
- Learn more about building serverless data streaming applications on Confluent Developer
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Stop Treating Your LLM Like a Database
GenAI thrives on real-time contextual data: In a modern system, LLMs should be designed to engage, synthesize, and contribute, rather than to simply serve as queryable data stores.



Generative AI Meets Data Streaming (Part III) – Scaling AI in Real Time: Data Streaming and Event-Driven Architecture
In this final part of the blog series, we bring it all together by exploring data streaming platforms (DSPs), event-driven architecture (EDA), and real-time data processing to scale AI-powered solutions across your organization.