[Virtual Event] Agentic AI Streamposium: Learn to Build Real-Time AI Agents & Apps | Register
Integrating Azure and Confluent: Real-Time Search Powered by Azure Cache for Redis and Spring Cloud
Self-managing a distributed system like Apache Kafka®, along with building and operating Kafka connectors, is complex and resource intensive. It requires significant Kafka skills and expertise in the development and operations teams of your organization. Additionally, the higher the volumes of real-time data that you work with, the more challenging it becomes to ensure that all of the infrastructure scales efficiently and runs reliably.
Confluent and Microsoft are working together to make the process of adopting event streaming easier than ever by alleviating the typical infrastructure management needs that often pull developers away from building critical applications. With Azure and Confluent seamlessly integrated, you can collect, store, process event streams in real-time and feed them to multiple Azure data services. The integration helps reduce the burden of managing resources across Azure and Confluent.
The unified integration with Confluent enables you to:
- Provision a new Confluent Cloud resource from Azure client interfaces like Azure Portal/CLI/SDKs with fully managed infrastructure
- Streamline single sign-on (SSO) from Azure to Confluent Cloud with your existing Azure Active Directory (AAD) identities
- Get unified billing of your Confluent Cloud service usage through Azure subscription invoicing with the option to draw down on Azure commits; Confluent Cloud consumption charges simply appear as a line item on monthly Azure bills
- Manage Confluent Cloud resources from the Azure portal and track them in the ”All Resources” page, alongside your Azure resources
Confluent has developed an extensive library of pre-built connectors that seamlessly integrate data from many different environments. With Confluent, Azure customers access fully managed connectors that stream data for low-latency, real-time analytics into Azure and Microsoft services like Azure Functions, Azure Blob Storage, Azure Event Hubs, Azure Data Lake Storage (ADLS) Gen2, and Microsoft SQL Server. More real-time data can now easily flow to applications for smarter analytics and more context-rich experiences.
Real-time search use case
In today’s rapidly evolving business ecosystem, organizations must create new business models, provide great customer experiences, and improve operational efficiencies to stay relevant and competitive. Technology plays a critical role in this journey with the new imperative being to build scalable, reliable, persistent real-time systems. Real-time infrastructure for processing large volumes of data with lower costs and reduced risk plays a key role in this evolution.
Apache Kafka often plays a key role in the modern data architecture with other systems producing/consuming data to/from it. These could be customer orders, financial transactions, clickstream events, logs, sensor data, and database change events. As you might imagine, there is a lot of data in Kafka (topics), but it’s useful only when processed (e.g., with Azure Spring Cloud or ksqlDB) or when ingested into other systems.
Let’s investigate an architecture pattern that transforms an existing traditional transaction system into a real-time data processing system. We‘ll describe a data pipeline that synchronizes data between MySQL and RediSearch, powered by Confluent Cloud on Azure. This scenario is applicable to many use cases, but we’ll specifically cover the scenario where batch data must be available to downstream systems in near real time to fulfill search requirements. The data can be further streamed to an ADLS store for correlation of real-time and historic data, analytics, and visualizations. This provides a foundation for other services through APIs to drive important parts of the business, such as a customer-facing website that can provide fresh, up-to-date information on products, availability, and more.
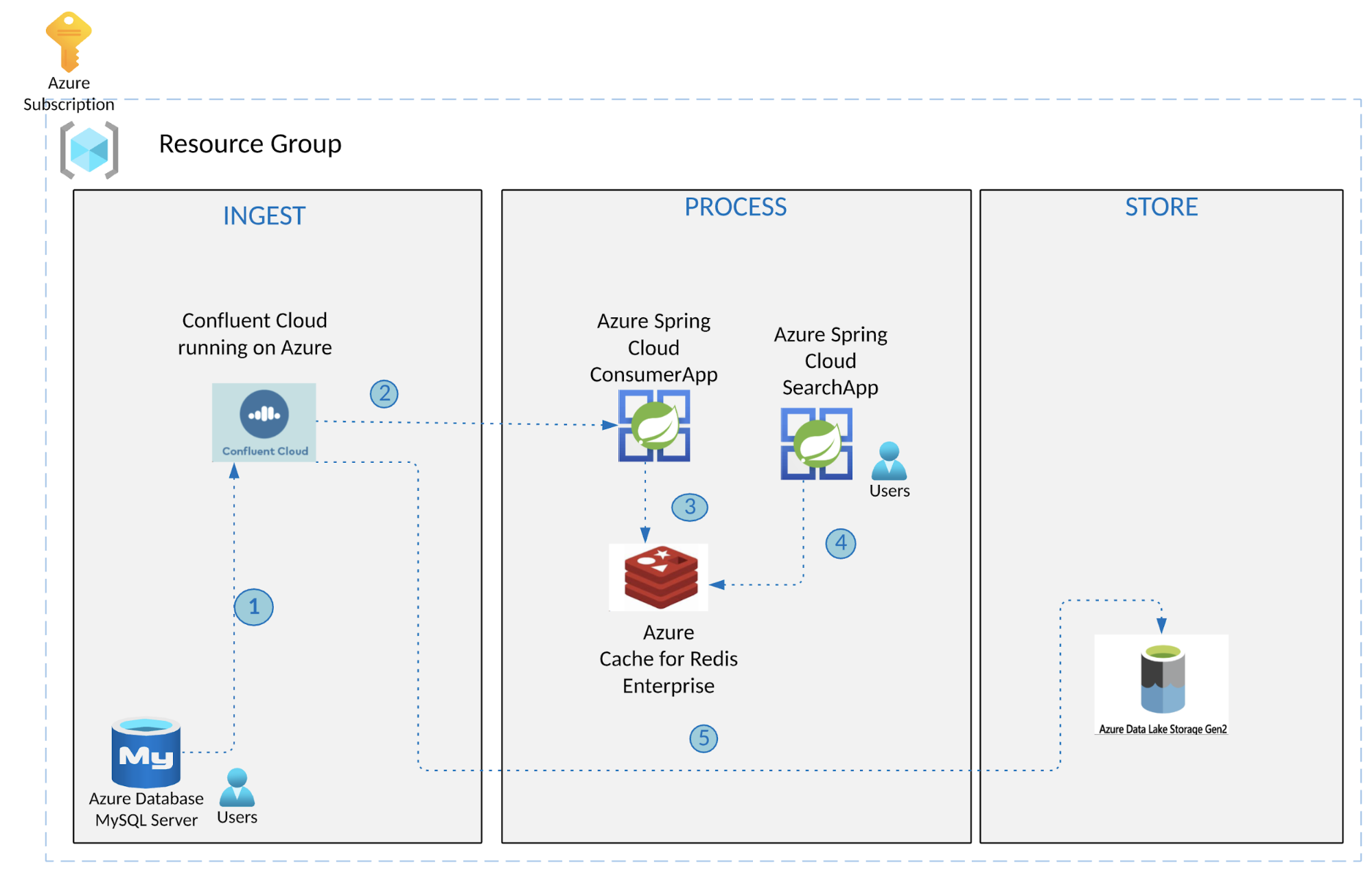
Real-time search using Azure Cache for Redis, Spring Cloud, and Confluent
Below are the key elements and capabilities of the above-mentioned architecture:
- Infrastructure components that form the bedrock of the architecture
- Apache Kafka on Confluent Cloud available in Azure Marketplace provides fully managed Kafka clusters
- The fully managed MySQL source connector with Confluent Cloud is used for streaming data into Kafka topics from a MySQL database
- Redis: We will use the RediSearch module, which is supported in the Enterprise tier of Azure Cache for Redis
- Azure Database for MySQL
- ADLS Gen2 sink connector for exporting data from Kafka topics to ADLS
- ADLS datastore for correlation of real-time and historical data and further analytics and visualizations
- Application components: These are services running on Azure Spring Cloud
- A Java Spring Boot application that uses the Spring for Apache Kafka integration is a consumer application that processes events from Kafka topics to Redis by creating the required index definition; it adds records as RediSearch documents by creating the required index definition and adding new product information as RediSearch documents (currently represented as a Redis hash)
- A search application is another Spring Boot application that makes the RediSearch data available as a REST API; it allows you to execute queries per the RediSearch query syntax
The above-mentioned services use the JRediSearch library to interface with RediSearch in order to create indexes, add documents, and query.
Thanks to the JDBC source connector, data in MySQL (the products table) is sent to a Kafka topic. Here is what the JSON payload looks like:


Objectives
The data can be uploaded into a relational database on Azure Database for MySQL, in this case, through an application or a batch process. This data will be synchronized from Confluent Cloud on Azure to the RediSearch module available in the Azure Cache for Redis Enterprise service. This will enable you to perform real-time search with your data in a flexible way. The real-time data is also streamed to an ADLS store. All the service components can be deployed to one Azure region for low latency and performance. Additionally, these service components are deployed in a single Azure subscription to enable unified billing of your Confluent Cloud usage through Azure subscription invoicing.
Prerequisites
- An Azure account
- Install the Azure CLI to deploy and manage the infrastructure components
- JDK 11 or above for e.g. Open JDK
- A recent Maven release
- Install Git
Set up the Azure cloud environment
- Create an Azure Database for MySQL server
- Create an instance of Apache Kafka on Confluent Cloud
- Create a Redis Enterprise cache instance with the RediSearch module enabled
- Provision an instance of Azure Spring Cloud
Build and deploy applications to Azure Spring Cloud
- Set up the consumer application to process events from Kafka topics to Redis
- Set up the search app to query records from RediSearch
- Build and deploy the application JAR file
Use the search application to query data
- Use curl or an HTTP client to invoke the Search API
Export data to Azure Data Lake
- Setup ADLS Gen 2 connector to export data from Kafka topics
Clean up
- Delete the resources (MySQL, Confluent Cloud organization, Redis, and your Azure Spring Cloud instance) individually or delete the resource group
Configure MySQL and Confluent Cloud on Azure
MySQL instance on Azure
Create an Azure Database for MySQL server using the Azure CLI (or the Azure portal if that’s what you prefer):
- Configure firewall rules to allow public inbound traffic access (0.0.0.0/0)
- Ensure that a specific database timezone is set
- Create a table (products) in MySQL—you can use a client like MySQL Workbench:
CREATE TABLE `products` ( `product_id` int(11) NOT NULL, `product_name` varchar(255) NOT NULL, `created_at`timestamp NOT NULL, `product_details` JSON DEFAULT NULL,
PRIMARY KEY (product_id) );
For more details, please refer to these prerequisites.
Kafka cluster in Confluent Cloud
- Set up and subscribe for Apache Kafka on Confluent Cloud, which you can easily discover via Azure Marketplace
- Provide configuration details for creating a Confluent Cloud organization on Azure
- Provisioning in Azure: Seamlessly provision Confluent organizations through the Azure portal
- Single sign-on to Confluent Cloud: Log in directly to Confluent Cloud
- Create Confluent Cloud fully managed resources like clusters, topics, and connectors
- Create a topic (optional): The connector automatically creates a topic (based on the default convention); create the topic manually if you want to override its default settings, though make sure to use the same topic name while configuring the connector
- Configure and launch the MySQL source connector using the portal
Before you move ahead, make sure that the basic pipeline is operational. Insert a record in MySQL and ensure that the Kafka topic is receiving messages.
For your Redis instance on Azure, ensure that you have the hostname and access keys handy.
Build and deploy applications to Azure Spring Cloud
Start by cloning the GitHub repository and go into the mysql-kafka-redis-integration directory:
git clone https://github.com/Azure-Samples/mysql-kafka-redis-integration cd mysql-kafka-redis-integration
For both services, update the application.yaml file in the src/main/resources folder with the connection details for Azure Cache for Redis and the Confluent Cloud cluster.
Here is a trimmed down version for the change events processor service:
redis:
host: <enter redis host>
port: <enter redis port>
password: <enter redis access key>
topic:
name: <topic name e.g. myserver.products>
partitions-num: 6
replication-factor: 3
spring:
kafka:
bootstrap-servers:
- <enter Confluent Cloud bootstrap server>
properties:
ssl.endpoint.identification.algorithm: https
sasl.mechanism: PLAIN
request.timeout.ms: 20000
retry.backoff.ms: 500
sasl.jaas.config: org.apache.kafka.common.security.plain.PlainLoginModule required username="<enter Confluent Cloud API key>" password="<enter Confluent Cloud API secret>";
security.protocol: SASL_SSL
...
The config for the Search API service is quite compact:
redis: host: <enter redis host> port: <enter redis port> password: <enter redis access key>
Build JAR files for the Spring applications:
export JAVA_HOME=<enter path to JDK e.g. /Library/Java/JavaVirtualMachines/zulu-11.jdk/Contents/Home>
Change Events Processor service
mvn clean package -f change-events-processor/pom.xml
Search API service
mvn clean package -f search-api/pom.xml
Install the Azure Spring Cloud extension for the Azure CLI:
az extension add --name spring-cloud
Create the Azure Spring Cloud applications corresponding to both of the services:
# Change Events Processor service az spring-cloud app create -n change-events-processor -s <enter the name of Azure Spring Cloud service instance> -g <enter azure resource group name> --runtime-version Java_11Search API service
az spring-cloud app create -n search-api -s <enter the name of Azure Spring Cloud service instance> -g <enter azure resource group name> --runtime-version Java_11 --is-public true
Deploy the JAR files for the respective applications that you just created:
# for the Change Events Processor service az spring-cloud app deploy -n change-events-processor -s <enter the name of Azure Spring Cloud service instance> -g <enter azure resource group name> --jar-path change-events-processor/target/change-events-processor-0.0.1-SNAPSHOT.jarfor the Search API service
az spring-cloud app deploy -n search-api -s <enter the name of Azure Spring Cloud service instance> -g <enter azure resource group name> --jar-path search-api/target/search-api-0.0.1-SNAPSHOT.jar
Time to see real-time search in action!
Now that we have all the components in place, we can test the end-to-end functionality. We will start by adding new product data to the MySQL database and use the Search app to make sure it has propagated all the way to Redis.
Insert the following sample data:
INSERT INTO `products` VALUES (42, 'Outdoor chairs', NOW(), '{"brand": "Mainstays", "description": "Mainstays Solid Turquoise 72 x 21 in. Outdoor Chaise Lounge Cushion", "tags": ["Self ties cushion", "outdoor chairs"], "categories": ["Garden"]}');
INSERT INTO products VALUES (43, 'aPhone', NOW(), '{"brand": "Orange", "description": "An inexpensive phone", "tags": ["electronics", "mobile phone"], "categories": ["Electronics"]}');
Get the URL for the Search API service using the portal or the CLI:
az spring-cloud app show -n search-api -s <enter the name of Azure Spring Cloud service instance> -g <enter azure resource group name>
Use curl or another HTTP client to invoke the Search API. Each of these queries will return results in form of a JSON payload, like so:
[
{
"created": "1614235666000",
"name": "Outdoor chairs",
"description": "Mainstays Solid Turquoise 72 x 21 in. Outdoor Chaise Lounge Cushion",
"id": "42",
"categories": "Garden",
"brand": "Mainstays",
"tags": "Self ties cushion, outdoor chairs"
},
{
"created": "1614234718000",
"name": "aPhone",
"description": "An inexpensive phone",
"id": "43",
"categories": "Electronics",
"brand": "Orange",
"tags": "electronics, mobile phone"
}
]
Here are a few examples to get you started. Note that the query parameter q is used to specify the RediSearch query.
# search for all records curl <search api URL>/search?q=*search for products by name
curl <search api URL>/search?q=@name:Outdoor chairs
search for products by category
curl <search api URL>/search?q=@categories:{Garden | Electronics}
search for products by brand
curl <search api URL>/search?q=@brand:Mainstays
apply multiple search criteria
curl <search api URL>/search?q=@categories:{Electronics} @brand:Orange
You can continue to add more product information and check the pipeline. You may also want to try the following:
- Confirm that information is flowing to the Kafka topic in Confluent Cloud
- Check the logs for the consumer application deployed to Azure Spring Cloud—you will be able to see the events that are getting processed (use az spring-cloud app logs -n <app name> -s <service name> -g <resource group> )
- Take a look at the RediSearch query syntax and try other queries as well
- Connect to the Azure Cache for Redis instance and run the RediSearch queries directly just to double-check
Connect to the Azure Cache for Redis instance using the redis-cli:
redis-cli -h <enter host name> -p <enter port i.e. 10000> -a <enter redis password/access key> --tls
Export data to Azure Data Lake
If you want to store this data in Azure Data Lake Storage longer term (cold storage), Confluent’s ADLS Gen2 connector has you covered. In our scenario, we already have product data flowing into the Kafka topic in Confluent Cloud on Azure—all we need to do is configure the connector to get the job done.
And guess what—that’s available as a fully managed offering as well!
Here is what you need to do:
- Create a storage account
- Configure the connector and start it; make sure to use the same topic name as you did before (e.g., myserver.products)
- Confirm that the data was exported to the Azure storage container in the ADLS account
For a step by step guide, please follow the documentation.
Delete Azure resources
Once you’re done, delete the services so that you do not incur unwanted costs. If they are in the same resource group, simply deleting the resource group will suffice. You can also delete the resources (MySQL, Confluent Cloud organization, Redis, and Azure Spring Cloud instance) individually.
Summary
The urgency for real-time applications will grow exponentially as more businesses undergo digital transformation. With the new integration between Confluent and Azure along with the fully managed Kafka connectors available to export and source data into Azure data and storage services, you will be able process huge volumes of data much faster, simplify integration, and avoid the challenges of setting up and maintaining complex distributed systems.
This complete guide showed you the high-level architecture on how to run this solution on Azure based on managed PaaS services. The benefit of this is that you don’t have to set up and maintain complex distributed systems, such as a database, event streaming platform, and runtime infrastructure for your Spring Boot Java apps.
Bear in mind that this is just one part of a potentially larger use case. Thanks to Kafka, you can extend this solution to integrate with other systems as well, such as Azure Data Lake, using yet another fully managed ADLS Gen2 connector.
Want to learn more?
If you’d like to learn more, Get started with Apache Kafka on Confluent Cloud via Azure Marketplace and follow the quick start. When you sign up, you’ll receive $400 to spend within Confluent Cloud during your first 60 days. Use the promo code CL60BLOG to receive an additional $60 of free usage.*
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Empowering Customers: The Role of Confluent’s Trust Center
Learn how the Confluent Trust Center helps security and compliance teams accelerate due diligence, simplify audits, and gain confidence through transparency.



Unified Stream Manager: Manage and Monitor Apache Kafka® Across Environments
Unified Stream Manager is now GA! Bridge the gap between Confluent Platform and Confluent Cloud with a single pane of glass for hybrid data governance, end-to-end lineage, and observability.