[Webinar] AI-Powered Innovation with Confluent & Microsoft Azure | Register Now
Powering Microservices at SEI Investments with Event Streaming
We launched a transformation initiative three years ago that transitioned SEI Investments from a monolithic database-oriented architecture to a containerized services platform with an event-driven architecture based on Confluent Platform.
SEI Investments has been a leader in the investment services industry for more than 50 years, helping professional wealth managers, institutional investors, and private investors create and manage wealth. In that time, we’ve established a reputation for comprehensive, innovative solutions that combine advice, investments, technology, and operations.
While we’re still relatively early in our event streaming journey, we are progressing rapidly on our path to maturity as an organization. We view this path as a series of phases, which we think of as days in our journey:
- Day 1: Proof of concept and auditing of data events
- Day 2: Streaming business events
- Day 3: Integrated streaming and streaming data delivery
- Today: Containerized services
To help others who are on a similar path apply new patterns and recognize opportunities for moving from the monolith to microservices, we would like to share some of the lessons learned and benefits we’ve already realized based on our experience.
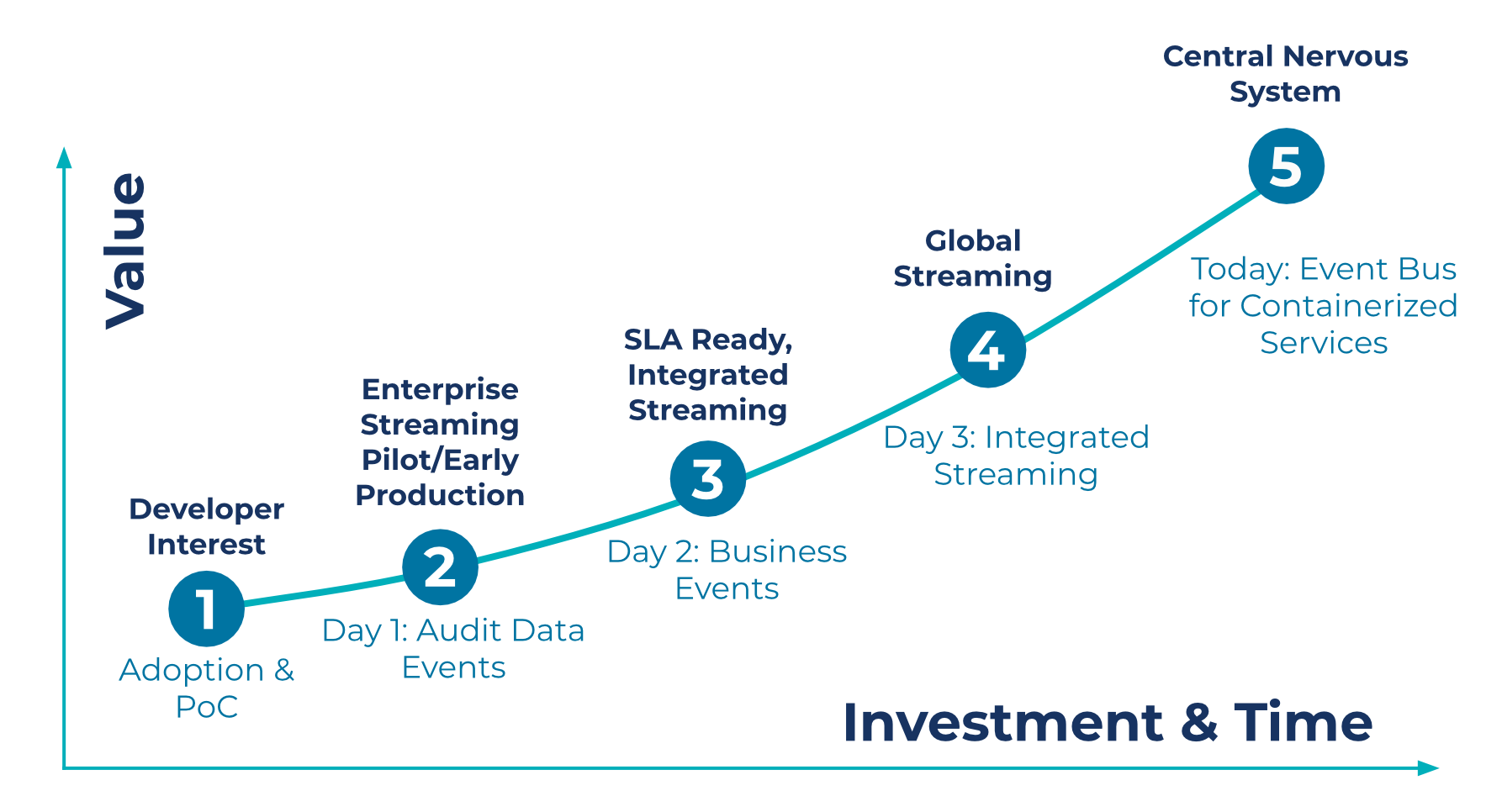
Data Streaming: Typical Maturity Stages
Day 1: First steps with data events
We started our first proof-of-concept for event streaming in 2017. We wanted to start with a use case that provided real benefits but with a simple initial implementation. So, we set a straightforward goal: Use Apache Kafka® as the backbone for the technical audit of our monolithic database application. We replaced hundreds of database triggers by using Oracle GoldenGate for big data, a tool for change data capture (CDC), to stream data from our database changelogs into Kafka. In 2018, that project went live along with several others, and we’ve since expanded to dozens of streaming applications today. This first use case for Kafka enabled us to get our foot in the door with event streaming and gave our developers the opportunity to become more familiar with Kafka.
Governance
Governance is a key aspect of managing any new technology, and Kafka is no exception. We had to build up several key practices, standards, and procedures as part of a governance model to enable our developers to work efficiently with event streaming. Topic creation was our governance entry point. We disabled automatic topic creation; any team that wanted to create a topic in our integrated environments had to open a request and get it approved by our governing group. Adding this one minor hurdle provided us the opportunity to review new products, control the usage of Kafka within SEI, and ensure that our developers followed proper, established patterns. Our governance efforts helped to increase project success rates, which is essential when introducing any new technology into an organization, especially a large one.
A closer look at CDC
In taking a closer look at how our change data capture stream works, it helps to consider an example using a typical database transaction. In this example, we execute table operations—inserts, deletes, and updates—on three different tables. When we commit the transaction, the data flows into a database transaction log. This is the same log that the database uses to recover state after failures. Because it sequentially records every database event, the log is a great source for capturing database events for Kafka while incurring no query overhead on the database itself. Each database commit is assigned a system change number (SCN), which we have used in a subsequent project to associate all the individual table operations that make up the commit. More on that later.
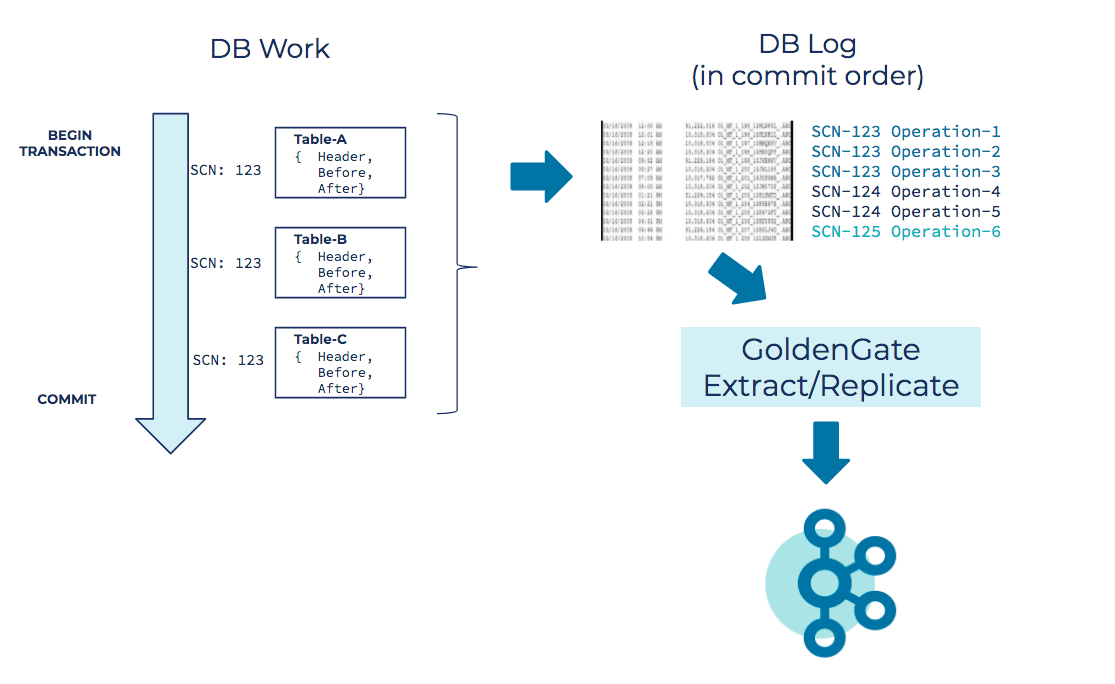 When Oracle GoldenGate replicates each database operation into an event stream, we have raw data operations in Kafka. These insert, update, and delete operations are represented as JSON payloads, with a structure that includes a header, a before image record, and an after image record. Insert operations only have an after image, delete operations only have a before image, and update operations have both. Depending on your use case, you can choose to include all the fields in the image or just the fields that have changed.
When Oracle GoldenGate replicates each database operation into an event stream, we have raw data operations in Kafka. These insert, update, and delete operations are represented as JSON payloads, with a structure that includes a header, a before image record, and an after image record. Insert operations only have an after image, delete operations only have a before image, and update operations have both. Depending on your use case, you can choose to include all the fields in the image or just the fields that have changed.
At this point in our journey, we had already made substantial headway. We were capturing database operation events, which is useful for a variety of use cases including audit alerts, triggering downstream actions from specific database events, pushing notifications, and offloading queries to lighten the load on our database, among others.
Day 2: From data events to business events
The next phase of our evolution was converting the CDC event stream into usable business events. This was a key step for us, because it opened the door for many new use cases. Up until this point, we were streaming raw data events sourced from the database. While that liberated the data for new and interesting uses, the much bigger breakthrough for us was getting to real business events, similar to those that a microservice application would write to an event bus.
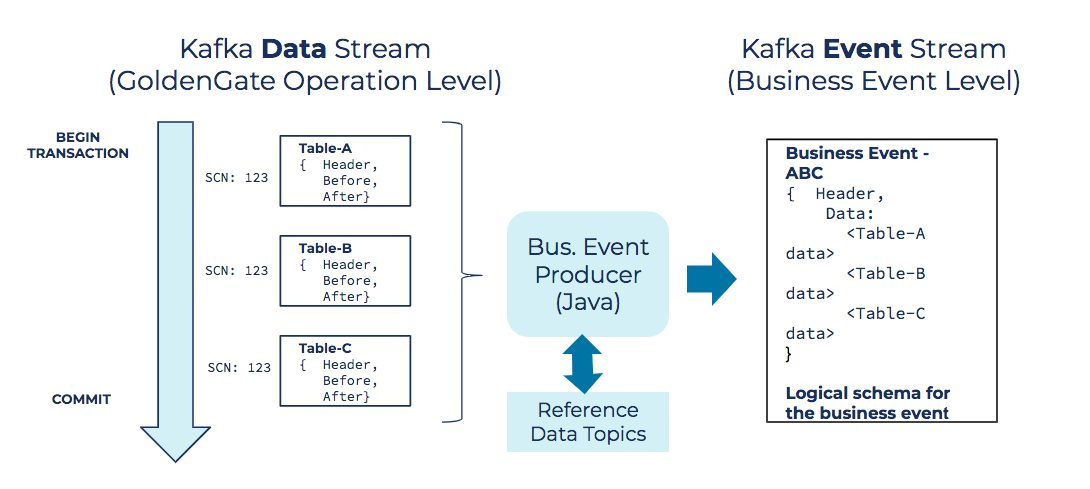 To drive the evolution, we created a consumer/producer application with specific logic for assembling business events from raw database operation events. We began by identifying core sets of tables that relate to specific data domains. From those tables, we created separate CDC streams and used those streams to produce holistic business events. For example, consider a purchase event that involves several related tables, such as inventory, sales orders, customers, and so on. Our consumer/producer application consumes the CDC streams for these tables and produces logical purchase events, which flow to consuming applications downstream.
To drive the evolution, we created a consumer/producer application with specific logic for assembling business events from raw database operation events. We began by identifying core sets of tables that relate to specific data domains. From those tables, we created separate CDC streams and used those streams to produce holistic business events. For example, consider a purchase event that involves several related tables, such as inventory, sales orders, customers, and so on. Our consumer/producer application consumes the CDC streams for these tables and produces logical purchase events, which flow to consuming applications downstream.
The nuts and bolts of producing business events
At a technical level, this process depends on the SCN I mentioned earlier. All related table operations have the same SCN as they were all updated within the same database transaction boundary. The application we built joins these related table updates logically using the SCN. The resulting JSON contains data from all the related tables that make up the business event. Essentially, we denormalize the related tables into an object that is more valuable to downstream consumers. The is similar to how an object-oriented Java application denormalizes relational tables into a unified business object.
Day 3: Integrated streaming and streaming data delivery
Once we were producing business events from database changes, we could begin to carve logic out of our legacy monolithic application. Just as importantly, we were able to address other critical business needs. One such need involved integrating two different financial systems to provide new product offerings. A second required delivering streaming data to clients who needed access to near-real-time events.
Integrating business events
Integrated streaming is a use case that nicely illustrates the power of Kafka as much more than a message queue. In our scenario, we had a legacy database application and a third-party application that we wanted to integrate for a new microservices platform, which would consume information from both systems and enable us to create a new offering for our customers.
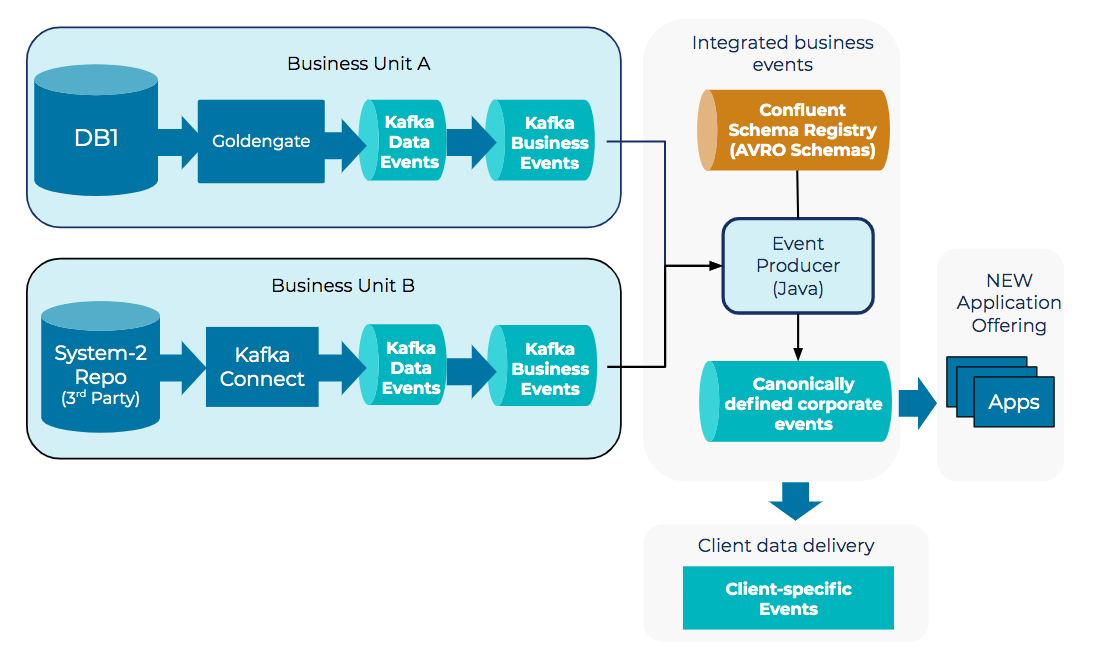
Kafka comes with streaming libraries for complex event processing and a RocksDB state store, which we needed. Beyond that, a key piece of functionality was provided by the Confluent Schema Registry. We use Confluent Schema Registry to normalize the data models to a canonical corporate model with Avro (an open framework for defining JSON schemas). This enables us to both govern the payloads and handle payload schema evolution.
Because we have multiple producing applications and multiple downstream consumers, we needed a way for the producers to evolve the events and schemas over time, making it possible to add new features or functionality without breaking the downstream consumers. With Confluent Schema Registry, our Kafka producers can perform forward and backward compatibility checking of the Avro schema, which acts as a contract between the two producing systems and the microservice consumers.
Having a point of governance for our schema with Confluent Schema Registry was an absolute game changer for us. Beyond better governance, we saw other benefits from this approach as well. Because Avro serves as a binary serialization framework, we could separate the data from the schema (i.e., the values from the keys), which results in a compact binary data format that has a much smaller footprint than the original data. This translates to faster reads and writes, as well as far less disk usage. In fact, using Avro combined with compression, we’ve reduced data payloads by a factor of 10 to 20.
Delivering near-real-time event streams
As our industry moves towards real-time event streams, we’ve also seen increased client interest in receiving data in near real time. To meet this need, we can reuse the same corporate canonical Avro schema that we designed for integrating systems.
After we filter data into separate client-based topics, we use Confluent Replicator to deliver that data to clients as near-real-time streams both reliably and securely (with SASL authentication and ACLs).
Ongoing development: Containerization
Today, we’re using all the patterns described here to help us in our transition to a modular containerized architecture. We’re beginning the process of breaking out application domains and moving them into Kubernetes, using a command query responsibility segregation (CQRS) pattern to move logic out piece by piece. This process isn’t exactly quick or easy; some components are much more difficult to separate than others. However, we’ve put enough of our architecture into place that it is now possible to move logic out of the monolith and into component services.
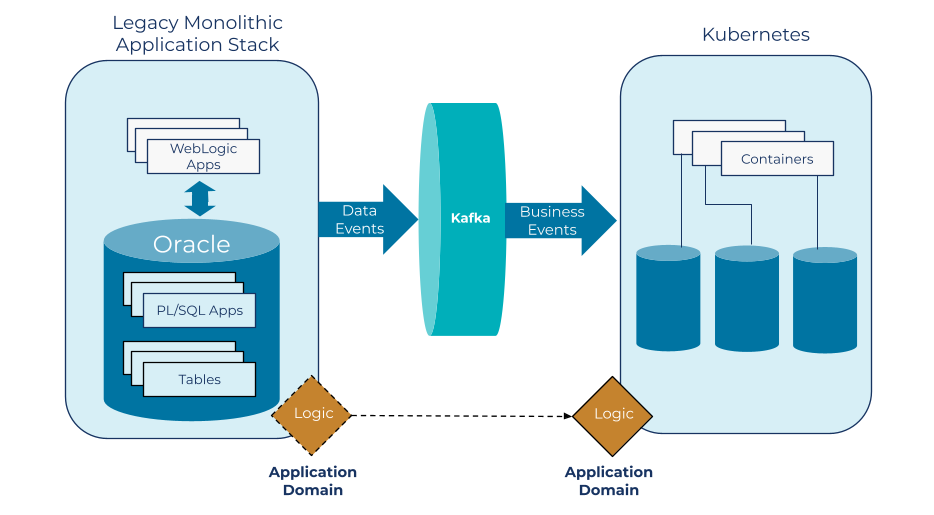
As we decompose legacy systems into containerized applications, each with their own state store, we rely on Kafka as the event streaming platform for communication. Our new containerized applications can write holistic business events directly to the platform. And events sourced from the monoliths are available to new component services being built in Kubernetes. Here again, we use Confluent Schema Registry to govern the payloads and manage the schema that serves as the contract between applications. This paves the way forward to control the evolution of microservice applications and payloads.
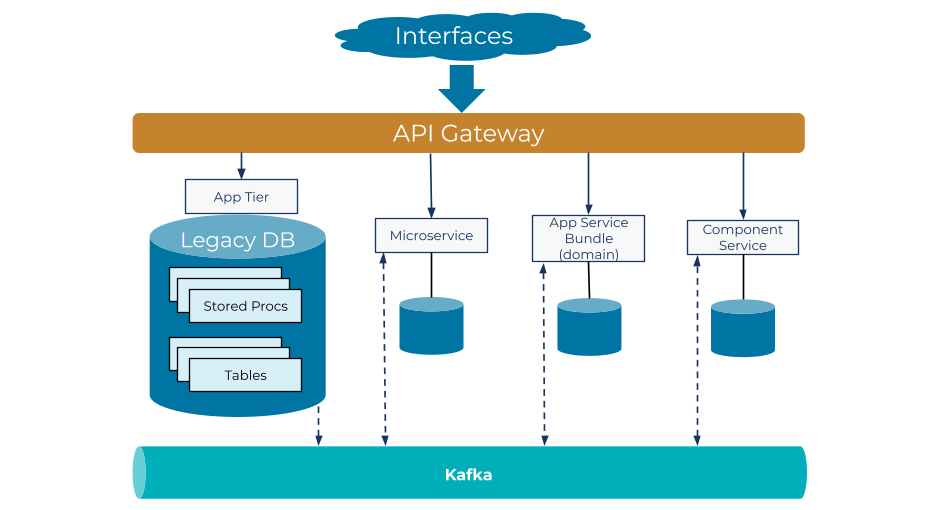
We’ve come a long way since we started our journey, but in many ways, we know we are really just getting started. As we continue to break key functionality out of our monolith, we are opening up new possibilities for application components to integrate with other components and third-party applications. This simply would not have been possible for us before the introduction of Confluent Platform. We are looking forward to capitalizing on these possibilities and turning them into even bigger business opportunities in the days to come.
If you’d like to know more, you can download the Confluent Platform to get started with a complete event streaming platform built by the original creators of Apache Kafka.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



3 Strategies for Achieving Data Efficiency in Modern Organizations
The efficient management of exponentially growing data is achieved with a multipronged approach based around left-shifted (early-in-the-pipeline) governance and stream processing.



Chopped: AI Edition - Building a Meal Planner
Dinnertime with picky toddlers is chaos, so I built an AI-powered meal planner using event-driven multi-agent systems. With Kafka, Flink, and LangChain, agents handle meal planning, syncing preferences, and optimizing grocery lists. This architecture isn’t just for food, it can tackle any workflow.