[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Optimizing Kafka Streams Applications
With the release of Apache Kafka® 2.1.0, Kafka Streams introduced the processor topology optimization framework at the Kafka Streams DSL layer. This framework opens the door for various optimization techniques from the existing data stream management system (DSMS) and data stream processing literature.
In what follows, we provide some context around how a processor topology was generated inside Kafka Streams before 2.1, with a focus on stateful operations like aggregations and joins. Along with it, we will demonstrate a few known issues that impact efficiency of the generated processor topology. Then we will describe how the processor topology generation phase was refactored to allow optimizations in Kafka 2.1, along with a few optimization techniques already offered in this release. We will wrap up this article with some operational guidelines on how to turn on topology optimizations when upgrading your Streams application to Kafka 2.1 and newer versions.
Kafka Streams topology generation 101
Before we present the topology optimization techniques introduced since the Kafka 2.1 release, let’s first examine how a user’s specified processing logic is presented in the constructed Streams processor topology, and why such a topology could be better optimized in the first place.
In Kafka Streams, there are two ways you can specify your application logic—via the Processor API or the Streams DSL. Both of them will construct the application’s computational logic as a processor topology, which is represented as a graph of stream processor nodes that are connected by stream edges.
Let’s take a look at a simple Streams application that performs the following steps:
- Consumes from a source topic named input
- Filters based on the contents of the value
- Transforms the value by extracting the first three characters
- Writes the updated key/value pairs to a topic named output
Below shows how this simple application can be written with the Processor API:
final Topology topology = new Topology();topology.addSource("SourceTopicProcessor","input" ); topology.addProcessor("FilteringProcessor", FilterProcessor::new, "SourceTopicProcessor"); topology.addProcessor("MappingProcessor", MapValuesProcessor::new, "FilteringProcessor"); topology.addSink("SinkProcessor", "output", "MappingProcessor");
System.out.println(builder.describe()); final KafkaStreams streams = new KafkaStreams(builder, properties); streams.start();
Using the Processor API, you have full control constructing the topology graph by adding processor nodes and connecting them together. Note that it is also possible to add state stores to the topology and connect them to processor nodes, though such functionality is omitted in this example.
When building a topology with the Processor API, you explicitly name each processing node in the topology, and also provide the name(s) of all of its parent nodes (the only exception are source nodes, which do not have any parents). For example, when adding the processor node named MappingProcessor, we declare its parent node is FilteringProcessor. Note that the MappingProcessor and FilteringProcessor code is omitted here for clarity.
Now let’s take a look at how the same Kafka Streams application logic can be written in the Streams DSL:
final StreamsBuilder builder = new StreamsBuilder();builder.<String, String>stream("input") .filter((k,v) -> v.endsWith("FOO")) .mapValues(v -> v.substring(0,3)) .to("output");
final Topology topology = builder.build(properties);
final KafkaStreams streams = new KafkaStreams(topology, properties); streams.start()
As you can see, while the Processor API provides more control and flexibility when constructing your topology, the Streams DSL encapsulates a lot of stream processing complexities in a functional programming interface. In practice, you can actually combine these two APIs, giving you the best of both worlds:
In addition, the above example involves a transformValues operator. This operator can take an arbitrary transform processor similar to the Processor API and be associated with a state store named stateStore to be accessed within the processor. Another good example of combining the two approaches can be found in the Real-Time Market Data Analytics Using Kafka Streams presentation from Kafka Summit.
Illustrate a generated topology graph
In order to investigate the generated topology from either the Processor API or the Streams DSL, you can render a string representation of it by calling Topology#describe() and printing the results either to the console or in a log file, as shown in the previous StreamsDSLAndProcessorExample.java example.
The results of Topology#describe()#toString() (shortened here for clarity) will look like this:
Topologies:
Sub-topology: 0
Source: KSTREAM-SOURCE-0000000000 (topics: [input-topic-one])
--> KSTREAM-KEY-SELECT-0000000002
Processor: KSTREAM-KEY-SELECT-0000000002 (stores: [])
--> KSTREAM-FILTER-0000000014
<-- KSTREAM-SOURCE-0000000000 Processor: KSTREAM-FILTER-0000000014 (stores: []) --> KSTREAM-SINK-0000000013
<-- KSTREAM-KEY-SELECT-0000000002
Sink: KSTREAM-SINK-0000000013 (topic: KSTREAM-KEY-SELECT-0000000002-repartition)
<-- KSTREAM-FILTER-0000000014 Sub-topology: 1 Source: KSTREAM-SOURCE-0000000001 (topics: [input-topic-two]) --> KSTREAM-KEY-SELECT-0000000003
Processor: KSTREAM-KEY-SELECT-0000000003 (stores: [])
--> KSTREAM-FILTER-0000000017
<-- KSTREAM-SOURCE-0000000001 Processor: KSTREAM-FILTER-0000000017 (stores: []) --> KSTREAM-SINK-0000000016
As you can see from our abbreviated example here, printing a simple topology is very useful, but once you start developing more complex ones, it can be a bit cumbersome to navigate the full textual representation. For help with viewing a textual representation of your topology, Joshua Koo developed a fantastic web tool that takes your topology description as input and automatically creates hand-drawn-like diagrams that visually represent the topology. We will use his tool to generate graphical illustrations of all topologies in this blog post.
Keyed stateful operators: Way to go, parallelism!
At a high level, when you use the Streams DSL, it auto-creates the processor nodes as well as state stores if needed, and connects them to construct the processor topology. To dig a little deeper, let’s take an example and focus on stateful operators in this section.
An important observation regarding the Streams DSL is that most stateful operations are keyed operations (e.g., joins are based on record keys, and aggregations are based on grouped-by keys), and the computation for each key is independent of all the other keys. These computational patterns fall under the term data parallelism in the distributed computing world. The straightforward way to execute data parallelism at scale is to just partition the incoming data streams by key, and work on each partition independently and in parallel. Kafka Streams leans heavily on this technique in order to achieve scalability in a distributed computing environment.
More specifically, Kafka Streams will redistribute the input streams based on the operation keys (the join key, the grouped-by key, etc.) before sending them to the downstream processor nodes that do the actual computation when constructing the processor topology, if necessary. (Later, we will explain in more detail how Streams determines the necessity to repartition data). This redistribution stage, usually called data shuffling, ensures that data is organized in partitions that can be processed in parallel. The reshuffled streams are stored and piped via specific Kafka topics called repartition topics.
By using Kafka topics to persist reshuffled streams instead of relying on interprocess communication directly, Kafka Streams effectively separates a single processor topology into smaller sub-topologies, connected by those repartition topics (each repartition topic is both a sink topic of the upstream sub-topology and a source topic of the downstream sub-topology). Sub-topologies can then be executed as independent stream tasks through parallel threads.
As a result, when a join/aggregate operator is added via the Streams DSL, Kafka Streams first decides if a repartition topic needs to be injected into the topology so that the input streams sent to the downstream operators are guaranteed to be partitioned on the operation key. Today this decision is made “conservatively” since Streams does not know exactly how user-defined parent processors of the stateful operations would manipulate the incoming stream. As a concrete example, consider the following Streams application:
final KStream<String, String> streamOne = builder.stream("input-topic-one"); final KStream<String, String> streamTwo = builder.stream("input-topic-two");final KStream<String, String> streamOneNewKey = streamOne.selectKey((k, v) -> v.substring(0, 5)); final KStream<String, String> streamTwoNewKey = streamTwo.selectKey((k, v) -> v.substring(4, 9));
streamOneNewKeyspan.join(streamTwoNewKey,(v1, v2) -> v1+":"+v2, JoinWindows.of(Duration.ofMinutes(5))).to("joined-output");
We’ve taken two streams and changed the key in order to join both streams. Kafka Streams detects this key change because we’ve used the selectKey() operator. But since the passed-in subString function parameter is agnostic to the Streams compiler, it would not know if the stream key has actually been modified or not. For example, users can always just use a lambda that returns the original key and value, but the Streams’ compiler still has to assume that the stream keys have indeed been changed.
Because the new keys are now being used as the join key in the join operators, as a result, Kafka Streams will repartition both streams based on the newly selected keys so that they are co-partitioned on the join key (i.e., the source topics have the same number of partitions so that the join operation can be executed in parallel). Hence, downstream join processors can be executed in parallel on the partitioned streams.
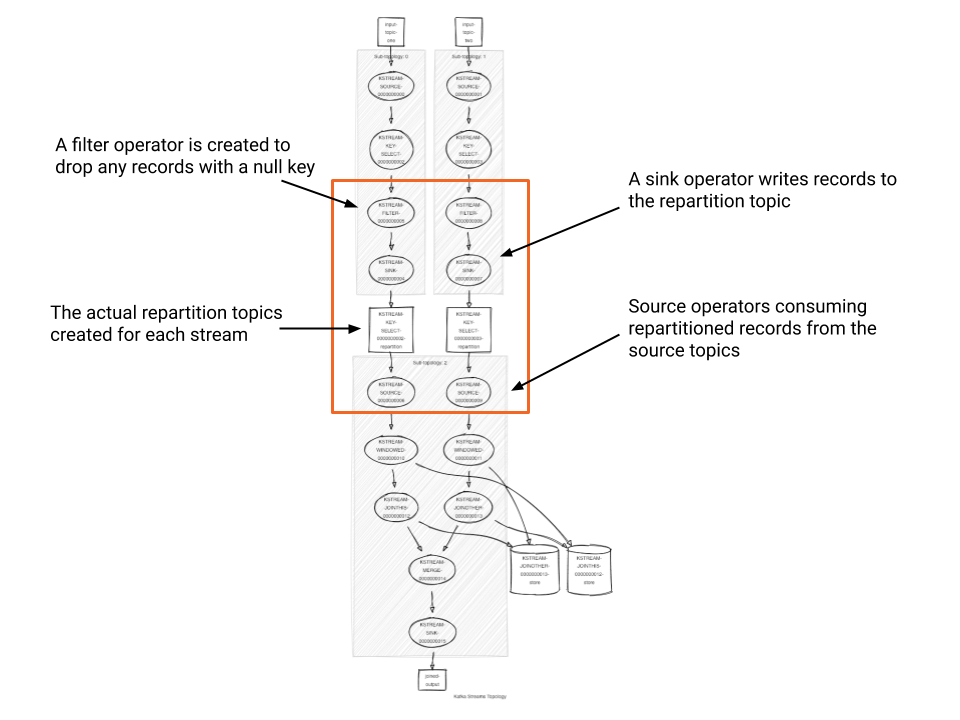
Now let’s look at the generated topology’s processors (as indicated by the highlighted box) from the join example shown above:
- First, Kafka Streams creates a filter operator to drop any records that have a null key as you must have a valid key to repartition the data records.
- Then, Kafka Streams adds a sink processor to write the records out to the repartition topic.
- Kafka Streams creates the repartition topic under the covers. This topic is an internal topic that is abstracted away from the users. Its name is prefixed with the application ID of the Streams program and suffixed with the keyword repartition.
- Finally, we have the source processor consuming records from the repartition topic, where messages with the same join keys come from the same partition. The join processors are added after the source processor to execute the join. The join algorithms here are similar to the collocated hash join algorithm in parallel database systems.
When can we avoid unnecessary repartitioning?
The Kafka Streams DSL defines processing logic for stateful operations by reshuffling the input streams via an inserted repartition topic in the processor topology. This is done whenever it cannot guarantee that the input stream key is already the same as the operation key. In other words, operations such as map, transform or selectKey, which may change the stream keys would cause Streams to insert repartition topics for stateful operations added after them, even when your passed-in map function does not change the key at all.
Although this unnecessary shuffling of phases based on repartition topics would not incur any correctness issues, it would indeed introduce performance penalties as well as a larger footprint on the Kafka cluster. Thus, it should be avoided whenever possible. Users leveraging the Processor API to construct their processor topologies can avoid unnecessary repartition topics if they know the incoming stream before the stateful operations have already been partitioned on the operation key, given they have full control on adding such topics along with processor nodes and state stores. The question is, what about the higher-level Streams DSL?
Key changing vs. value-changing operations
One rescue for the Streams DSL user is to adopt the built-in operators that only allow value transformations where possible. For example, if you only want to modify the value of the upcoming stream, replace your map operator with mapValues, which will only apply the mapper function to the values of the stream while retaining keys. With this operator, Kafka Streams can infer that keys stay unmodified and, therefore, won’t inject a repartition topic if you perform an aggregation or join operation following this operation.
So a rule of thumb is whenever you need to perform a transformation that does not need to modify the key, make sure to use the value-only variant of the transformation. Note that you can get read-only access to the key within mapValues by using a ValueMapperWithKey instead of a ValueMapper (similar XxxWithKey functions are available for other operators, too).
Below is a table summarizing the different key/value and value-only transformations available in the Kafka Streams DSL. There are also operations that will not modify either key or value and thus prevent Streams from injecting repartition topics for stateful operations afterwards, such as filter, peek and merge, which we omit in this article.
| Key-Changing Operation | Value-Only Operation |
| map | mapValues |
| flatMap | flatMapValues |
| transform | transformValues |
Topology generation: An optimization problem
As we have seen in the previous sections, when using the Streams DSL to define a stream processing application’s computational logic, you have to pay attention to the generated processor topology in case it is not efficient—unnecessary repartition topics is just one example, but there are other cases that may contribute to inefficiency, such as redundant materialized state stores, duplicated intermediate topics for multiple stateful operations, etc.
One way to avoid these inefficiencies would be printing the generated processor topology via TopologyDescription (see the previous section for details), spotting inefficiency factors and trying to rewrite your code in the Streams DSL to avoid them. However, as a programming interface, such a tedious development cycle should not be the design philosophy of the Streams DSL. Instead, it should try to hide as much of the topology generation details from the developer as possible. So the problem is: How can the Streams DSL be able to “rewrite” a user’s specified computational logic automatically to generate efficient processor topologies?
This problem is not new in data processing. In DBMS, for example, it has a famous term: query optimization. The key idea behind it is to have two layers of representation to user-defined computational logic:
- The first layer is called a logical plan that captures all the logical operators and their correlations, and is generated by parsing and translating the written code
- The second layer is called a physical plan, which gets generated from the logical plan by a query optimizer, and represents the actual execution routine.
In Kafka Streams, the physical plan is the processor topology. Therefore, in order to allow the Streams DSL to be smarter about the processor topology (i.e., the physical plan) it generates, we need to maintain a logical representation that first captures the full picture of user-defined computational logic. Then by tweaking the logical plan, we can optimize the generated processor topology.
Topology optimization in the Kafka Streams DSL
Before Apache Kafka 2.1, the Kafka Streams DSL did not maintain a logical plan when parsing a user’s written code. More specifically, it constructed the processor topology immediately following a one-operator-at-a-time translation approach: When parsing each of the defined operators, the Streams DSL immediately added processor nodes and state stores that represent each operator’s logic to the topology under construction. Because of that, it was very tricky to “review” the constructed processor topology and look for any optimization opportunities.
Since 2.1 we’ve augmented the Streams DSL framework to add an intermediate logical plan that the user code would initially translate to. This logical plan is also represented as a diagram of nodes, where each node represents operators. After the logical plan is constructed, the Streams library will make a second pass on it and try to rewrite part of the diagram to reduce the footprint, save inter-transmission cost, etc.
Finally, the logical plan is compiled into the physical plan, also known as the processor topology. Code written via the high-level Streams DSL will first translate into the logical plan, and only when StreamsBuilder#build() is called, the optimization process kicks in and tries to rewrite the logical plan before returning the compiled processor topology to the caller. With this “two-pass” framework, Kafka Streams can now look for hints in the existing topology to make it more efficient. Again, this optimization framework is very similar to standard query optimization in a database.
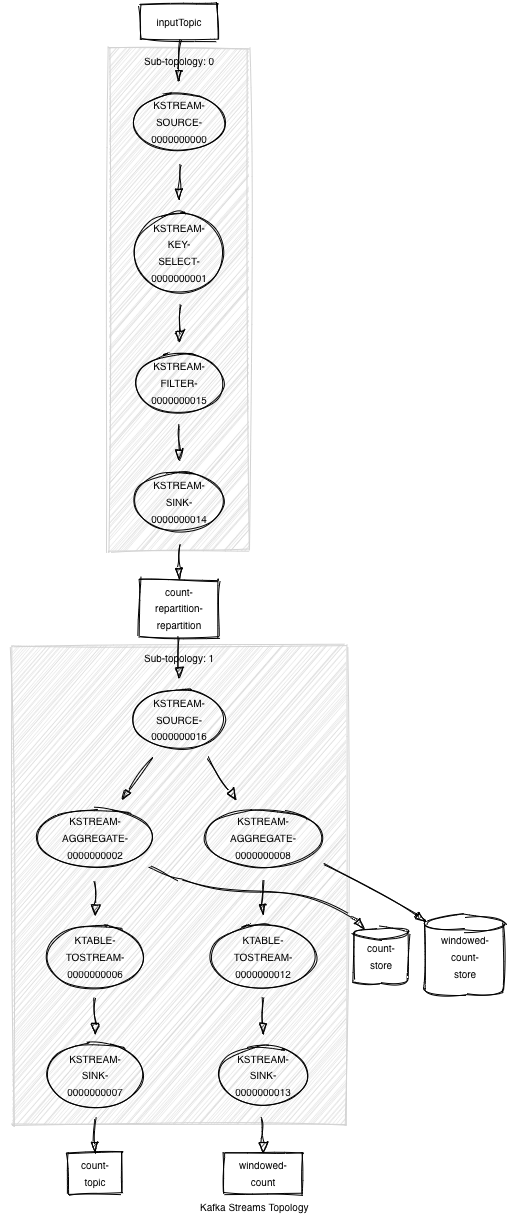
For a concrete example, let’s consider the following Streams application where repartition topics would be needed:
final StreamsBuilder builder = new StreamsBuilder(); final KStream<String, String> inputStream = builder.stream("inputTopic");
final KStream<String, String> changedKeyStream = inputStream.selectKey((k, v) -> v.substring(0,5));
// first repartition changedKeyStream.groupByKey(Grouped.as("count-repartition")) .count(Materialized.as("count-store")) .toStream().to("count-topic", Produced.with(Serdes.String(), Serdes.Long()));
// second repartition changedKeyStream.groupByKey(Grouped.as("windowed-repartition")) .windowedBy(TimeWindows.of(Duration.ofSeconds(5))) .count(Materialized.as("windowed-count-store")) .toStream().to("windowed-count", Produced.with(WindowedSerdes.timeWindowedSerdeFrom(String.class), Serdes.Long()));
final Topology topology = builder.build(properties); final KafkaStreams kafkaStreams = new KafkaStreams(topology, properties); kafkaStreams.start();
Above, we make a call to KStream#selectKey to change the key of the records. Under the covers, Kafka Streams infers that a repartition topic will be needed downstream if the new key is involved in stateful operations. Then, the updated stream is involved in two aggregation operations. In older versions of Kafka without topology optimization, the resulting processor topology would look like the following:
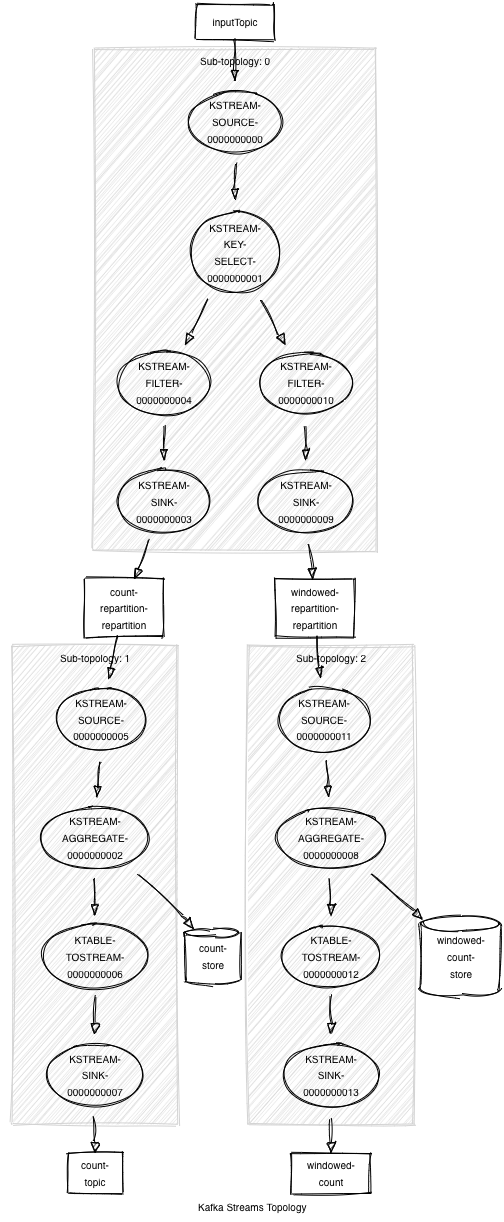
As you can see, two repartition topics were created in our topology even though repartitioning the data once is sufficient. When the Streams DSL constructs the processor topology, these stateful operations were being parsed and compiled independently into the topology.
We could, instead, inject a single repartition topic immediately after the selectKey operator, leading to substantial savings in resources and processing time. From a user’s perspective, this is doable by adding a KStream#through() operation after the selectKey operation to inject a intermediate topic, as well as adding the aggregation/join operations after the resulted stream. Since the source stream piped out of this intermediate topic is known to be partitioned by the key already, Streams would not enforce repartitioning any more. Of course, this would require you to have deep knowledge of Streams DSL topology generation internals (or to have been a reader of this blog post 😃) in order to make the appropriate code changes.
With the topology optimization framework added to the Streams DSL layer in Kafka 2.1, however, a manual process is no longer needed, as Kafka Streams will perform topology rewrites automatically via logical plan optimization. For this specific case, when the StreamBuilder#build() method is called, Streams will “push up” the repartitioning phase of the logical plan based on the captured metadata before compiling it to the processor topology. As a result, no other repartitioning is needed for the downstream stateful operations.
Here’s a detailed view of what we have before optimization is enabled:*
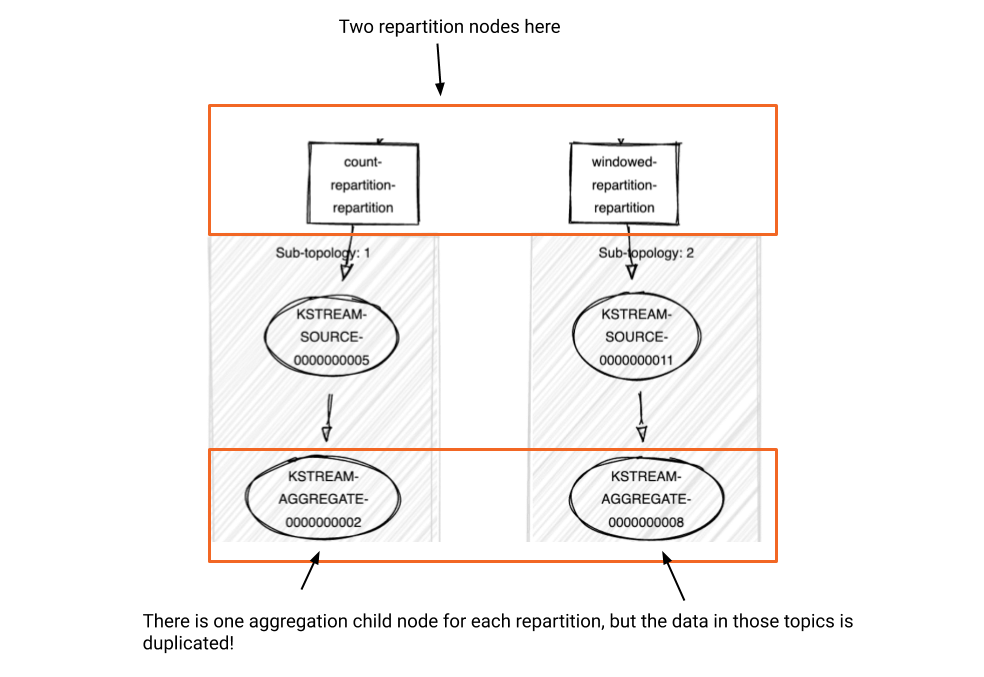
*Note that it is not representing the logical plan; instead, it is showing the physical plan, also known as the processor topology, for illustration purposes.
After the optimization phase is complete, the compiled topology will look like this:
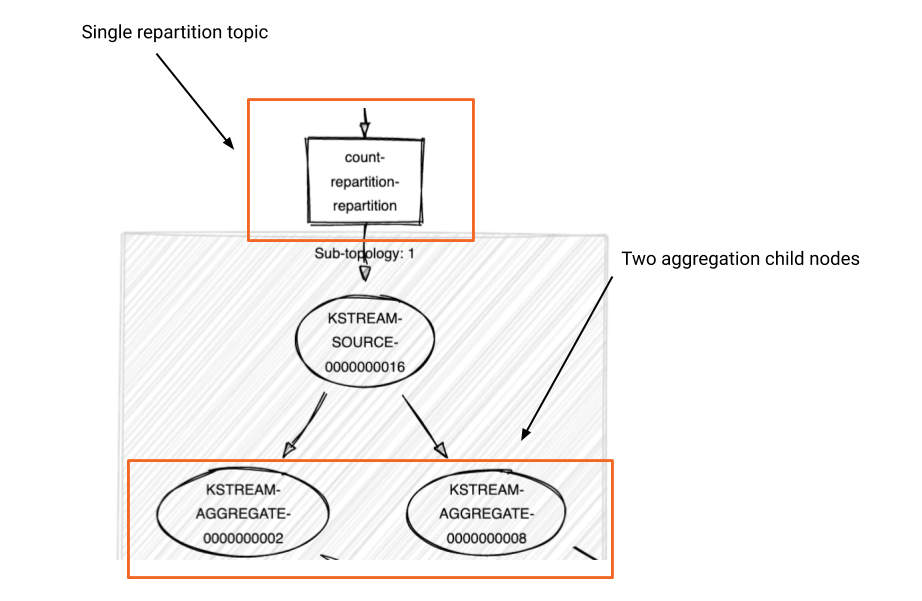
And here’s the complete generated processor topology for the written code above after the two-phase optimization/compilation process:
We used the repartition topics “push-up” case as an example to illustrate how we can generate more efficient processor topology with the newly added framework. There are more optimization rules that have been added since the Kafka 2.1 release, and if you are interested, please refer to this KAFKA-6034 for more details.
How to enable optimizations
To take advantage of optimizations, you need to set the new configuration StreamsConfig.TOPOLOGY_OPTIMIZATION to StreamsConfig.OPTIMIZE. Next, you need to pass the Properties object via the overloaded StreamBuilder#build(Properties props) method to signal to Streams that you want to optimize your topology.
By default, optimizations are turned off to maintain backward compatibility of the generated topology with older versions of Kafka Streams. If you already have a Streams application up and running, then when you want to swap in the new versioned Kafka byte code in order to enable optimization, you need to consider the following:
- First of all, when enabling optimizations for the first time, you can’t do a rolling redeployment. You’ll need to stop all your Streams instances, update the configuration value and then restart all your instances again.
- If the newly generated topology has different intermediate topics compared with the old topology, then the previously existing intermediate topics will become obsolete and any unprocessed records left on those topics will be dropped as new topics are created.
- If you need to ensure that you process all records, then you’ll need to use the application reset tool once you’ve stopped all your Streams instances. Using the application reset tool, you can rewind your input topic(s) to a known point and reprocess your records from there.
What’s next?
This blog post focused on reducing unnecessary intermediate repartition topics and presenting the topology optimization framework, a significant optimization rule added in the Apache Kafka 2.1 release. Although the Kafka Streams library is “data schema agnostic” today and therefore cannot leverage many standard techniques from the query processing literature, such as predicate pushdown, there is still a large optimization room on structural topology formation for it to explore. In fact, in the newly released 2.2.0 version we’ve added new optimization rules, including the one that uses logical views instead of physical materializations to reduce state store footprints.
Stay tuned for more things to come! If you have any feedback or ideas about this topic, feel free to jump in on the discussion, propose a KIP or even send a PR! And if this stuff sounds like an interesting challenge, you can work with us on it full time!
About Apache Kafka’s Streams API
If you have enjoyed this article, you might want to continue with the following resources to learn more about Apache Kafka’s Streams API:
- Get started with the Kafka Streams API to build your own real-time applications and microservices
- Walk through the Confluent tutorial for the Kafka Streams API with Docker and play with the Confluent demo applications
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Stop Treating Your LLM Like a Database
GenAI thrives on real-time contextual data: In a modern system, LLMs should be designed to engage, synthesize, and contribute, rather than to simply serve as queryable data stores.



Generative AI Meets Data Streaming (Part III) – Scaling AI in Real Time: Data Streaming and Event-Driven Architecture
In this final part of the blog series, we bring it all together by exploring data streaming platforms (DSPs), event-driven architecture (EDA), and real-time data processing to scale AI-powered solutions across your organization.