[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Putting Several Event Types in the Same Topic – Revisited
In the article Should You Put Several Event Types in the Same Kafka Topic?, Martin Kleppmann discusses when to combine several event types in the same topic and introduces new subject name strategies for determining how Confluent Schema Registry should be used when producing events to an Apache Kafka® topic.
Schema Registry now supports schema references in Confluent Platform 5.5, and this blog post presents an alternative means of putting several event types in the same topic using schema references, discussing the advantages and disadvantages of this approach.
Constructs and constraints
Apache Kafka, which is an event streaming platform, can also act as a system of record or a datastore, as seen with ksqlDB. Datastores are composed of constructs and constraints. For example, in a relational database, the constructs are tables and rows, while the constraints include primary key constraints and referential integrity constraints. Kafka does not impose constraints on the structure of data, leaving that role to Confluent Schema Registry. Below are some constructs when using both Kafka and Schema Registry:
- Message: a data item that is made up of a key (optional) and value
- Topic: a collection of messages, where ordering is maintained for those messages with the same key (via underlying partitions)
- Schema (or event type): a description of how data should be structured
- Subject: a named, ordered history of schema versions
The following are some constraints that are maintained when using both Kafka and Schema Registry:
- Schema-message constraints: A schema constrains the structure of the message. The key and value are typically associated with different schemas. The association between a schema and the key or value is embedded in the serialized form of the key or value.
- Subject-schema constraints: A subject constrains the ordered history of schema versions, also known as the evolution of the schema. This constraint is called a compatibility level. The compatibility level is stored in Schema Registry along with the history of schema versions.
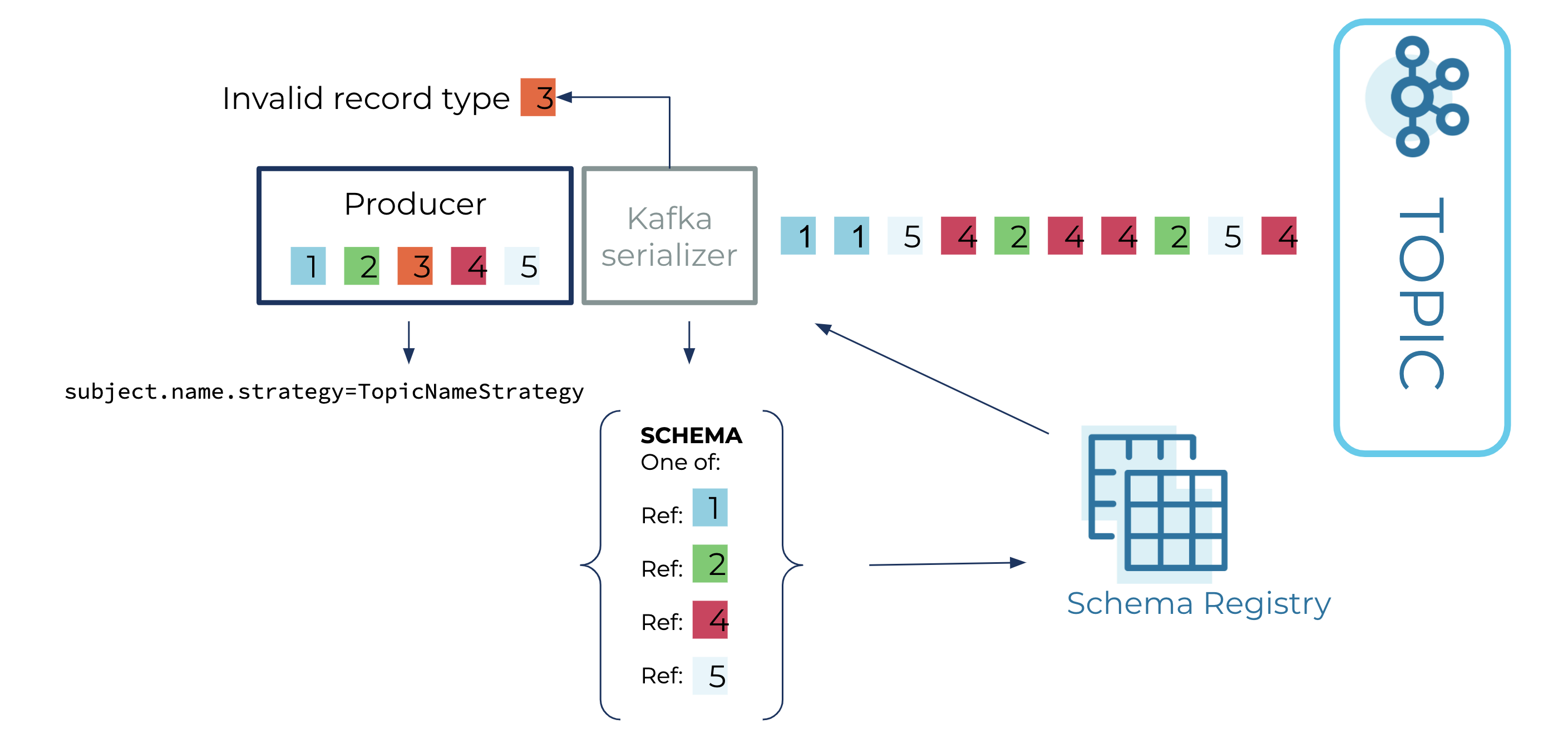
- Subject-topic constraints: When using the default TopicNameStrategy, a subject can constrain the collection of messages in a topic. The association between the subject and the topic is by convention, where the subject name is {topic}-key for the message key and {topic}-value for the message value.
Using Apache Avro™ unions before schema references
As mentioned, the default subject name strategy, TopicNameStrategy, uses the topic name to determine the subject to be used for schema lookups, which helps to enforce subject-topic constraints. The newer subject-name strategies, RecordNameStrategy and TopicRecordNameStrategy, use the record name (along with the topic name for the latter strategy) to determine the subject to be used for schema lookups. Before these newer subject-name strategies were introduced, there were two options for storing multiple event types in the same topic:
- Disable subject-schema constraints by setting the compatibility level of a subject to NONE and allowing any schema to be saved in the subject, regardless of compatibility
- Use an Avro union
The second option of using an Avro union was preferred but still had the following issues:
- The resulting Avro union could become unwieldy
- It was difficult to independently evolve the event types contained within the Avro union
By using either RecordNameStrategy or TopicRecordNameStrategy, you retain subject-schema constraints, eliminate the need for an Avro union, and gain the ability to evolve types independently. However, you lose subject-topic constraints, as now there is no constraint on the event types that can be stored in the topic, which means the set of event types in the topic can grow unbounded.
Using Avro unions with schema references
Introduced in Confluent Platform 5.5, a schema reference is comprised of:
- A reference name: part of the schema that refers to an entirely separate schema
- A subject and version: used to identify and look up the referenced schema
When registering a schema to Schema Registry, an optional set of references can be specified, such as this Avro union containing reference names:
[ "io.confluent.examples.avro.Customer", "io.confluent.examples.avro.Product", "io.confluent.examples.avro.Payment" ]
When registering this schema to Schema Registry, an array of reference versions is also sent, which might look like the following:
[
{
"name": "io.confluent.examples.avro.Customer",
"subject": "customer",
"version": 1
},
{
"name": "io.confluent.examples.avro.Product",
"subject": "product",
"version": 1
},
{
"name": "io.confluent.examples.avro.Order",
"subject": "order",
"version": 1
}
]
As you can see, the Avro union is no longer unwieldy. It is just a list of event types that will be sent to a topic. The event types can evolve independently, similar to when using RecordNameStrategy and TopicRecordNameStrategy. Plus, you regain subject-topic constraints, which were missing when using the newer subject name strategies.
However, in order to take advantage of these newfound gains, you need to configure your serializers a little differently. This has to do with the fact that when an Avro object is serialized, the schema associated with the object is not the Avro union, but just the event type contained within the union. When the Avro serializer is given the Avro object, it will either try to register the event type as a newer schema version than the union (if auto.register.schemas is true), or try to find the event type in the subject (if auto.register.schemas is false), which will fail. Instead, you want the Avro serializer to use the Avro union for serialization and not the event type. In order to accomplish this, set these two configuration properties on the Avro serializer:
- auto.register.schemas=false
- use.latest.version=true
Setting auto.register.schemas to false disables automatic registration of the event type, so that it does not override the union as the latest schema in the subject. Setting use.latest.version to true causes the Avro serializer to look up the latest schema version in the subject (which will be the union) and use that for serialization; otherwise, if set to false, the serializer will look for the event type in the subject and fail to find it.
Using JSON Schema and Protobuf with schema references
Now that Confluent Platform supports both JSON Schema and Protobuf, both RecordNameStrategy and TopicRecordNameStrategy can be used with these newer schema formats as well. In the case of JSON Schema, the equivalent of the name of the Avro record is the title of the JSON object. In the case of Protobuf, the equivalent is the name of the Protobuf message.
Also like Avro, instead of using the newer subject-name strategies to combine multiple event types in the same topic, you can use unions. The Avro union from the previous section can also be modeled in JSON Schema, where it is referred to as a "oneof":
{
"oneOf": [
{ "$ref": "Customer.schema.json" },
{ "$ref": "Product.schema.json" },
{ "$ref": "Order.schema.json }
]
}
In the above schema, the array of reference versions that would be sent might look like this:
[
{
"name": "Customer.schema.json",
"subject": "customer",
"version": 1
},
{
"name": "Product.schema.json",
"subject": "product",
"version": 1
},
{
"name": "Order.schema.json",
"subject": "order",
"version": 1
}
]
As with Avro, automatic registration of JSON schemas that contain a top-level oneof won’t work, so you should configure the JSON Schema serializer in the same manner as the Avro serializer, with auto.register.schemas set to false and use.latest.version set to true, as described in the previous section.
In Protobuf, top-level oneofs are not permitted, so you need to wrap the oneof in a message:
syntax = "proto3";
package io.confluent.examples.proto;
import "Customer.proto";
import "Product.proto";
import "Order.proto";
message AllTypes {
oneof oneof_type {
Customer customer = 1;
Product product = 2;
Order order = 3;
}
}
Here are the corresponding reference versions that could be sent with the above schema:
[
{
"name": "Customer.proto",
"subject": "customer",
"version": 1
},
{
"name": "Product.proto",
"subject": "product",
"version": 1
},
{
"name": "Order.proto",
"subject": "order",
"version": 1
}
]
One advantage of wrapping the oneof with a message is that automatic registration of the top-level schema will work properly. In the case of Protobuf, all referenced schemas will also be auto registered, recursively.
You can do something similar with Avro by wrapping the union with an Avro record:
{
"type": "record",
"namespace": "io.confluent.examples.avro",
"name": "AllTypes",
"fields": [
{
"name": "oneof_type",
"type": [
"io.confluent.examples.avro.Customer",
"io.confluent.examples.avro.Product",
"io.confluent.examples.avro.Order"
]
}
]
}
This extra level of indirection allows automatic registration of the top-level Avro schema to work properly. However, unlike Protobuf, with Avro, the referenced schemas still need to be registered manually beforehand, as the Avro object does not have the necessary information to allow referenced schemas to be automatically registered.
Wrapping a oneof with a JSON object won’t work with JSON Schema, since a POJO being serialized to JSON doesn’t have the requisite metadata. Instead, optionally annotate the POJO with a @Schema annotation to provide the complete top-level JSON Schema to be used for both automatic registration and serialization. As with Avro, and unlike Protobuf, referenced schemas need to be registered manually beforehand.
Getting started with schema references
Schema references are a means of modularizing a schema and its dependencies. While this article shows how to use them with unions, they can be used more generally to model the following:
- Nested records in Avro
- import statements in Protobuf
- $ref statements in JSON Schema
As mentioned in the previous section, if you’re using Protobuf, the Protobuf serializer can automatically register the top-level schema and all referenced schemas, recursively, when given a Protobuf object. This is not possible with the Avro and JSON Schema serializers. With those schema formats, you must first manually register the referenced schemas and then the top-level schema. Manual registration can be accomplished with the REST APIs or with the Schema Registry Maven Plugin.
As an example of using the Schema Registry Maven Plugin, below are schemas specified for the subjects named all-types-value, customer, and product in a Maven POM.
<plugin>
<groupId>io.confluent</groupId>
<artifactId>kafka-schema-registry-maven-plugin</artifactId>
<version>${confluent.version}</version>
<configuration>
<schemaRegistryUrls>
<param>http://127.0.0.1:8081</param>
</schemaRegistryUrls>
<subjects>
<all-types-value>src/main/avro/AllTypes.avsc</all-types-value>
<customer>src/main/avro/Customer.avsc</customer>
<product>src/main/avro/Product.avsc</product>
</subjects>
<schemaTypes>
<all-types-value>AVRO</all-types-value>
<customer>AVRO</customer>
<product>AVRO</product>
</schemaTypes>
<references>
<all-types-value>
<reference>
<name>io.confluent.examples.avro.Customer</name>
<subject>customer</subject>
</reference>
<reference>
<name>io.confluent.examples.avro.Product</name>
<subject>product</subject>
</reference>
</all-types-value>
</references>
</configuration>
<goals>
<goal>register</goal>
</goals>
</plugin>
Each reference can specify a name, subject, and version. If the version is omitted, as with the example above, and the referenced schema is also being registered at the same time, the referenced schema’s version will be used; otherwise, the latest version of the schema in the subject will be used.
Here is the content of AllTypes.avsc, which is a simple union:
[
"io.confluent.examples.avro.Customer",
"io.confluent.examples.avro.Product"
]
Here is Customer.avsc, which contains a Customer record:
{
"type": "record",
"namespace": "io.confluent.examples.avro",
"name": "Customer",
"fields": [
{ "name": "customer_id", "type": "int" },
{ "name": "customer_name", "type": "string" },
{ "name": "customer_email", "type": "string" },
{ "name": "customer_address", "type": "string" }
]
}
And here is Product.avsc, which contains a Product record:
{
"type": "record",
"namespace": "io.confluent.examples.avro",
"name": "Product",
"fields": [
{"name": "product_id", "type": "int"},
{"name": "product_name", "type": "string"},
{"name": "product_price", "type": "double"}
]
}
Next, register the schemas above using the following command:
mvn schema-registry:register
The above command will register referenced schemas before registering the schemas that depend on them. The output of the command will contain the ID of each schema that is registered. You can use the schema ID of the top-level schema with the console producer when producing data.
Next, use the console tools to try it out. First, start the Avro console consumer. Note that you should specify the topic name as all-types since the corresponding subject is all-types-value according to TopicNameStrategy.
./bin/kafka-avro-console-consumer --topic all-types --bootstrap-server localhost:9092
In a separate console, start the Avro console producer. Pass the ID of the top-level schema as the value of value.schema.id.
./bin/kafka-avro-console-producer --broker-list localhost:9092 --topic all-types --property value.schema.id={id} --property auto.register=false --property use.latest.version=true
At the same command line as the producer, input the data below, which represent two different event types. The data should be wrapped with a JSON object that specifies the event type. This is how the Avro console producer expects data for unions to be represented in JSON.
{ "io.confluent.examples.avro.Product": { "product_id": 1, "product_name" : "rice", "product_price" : 100.00 } }
{ "io.confluent.examples.avro.Customer": { "customer_id": 100, "customer_name": "acme", "customer_email": "acme@google.com", "customer_address": "1 Main St" } }
The data will appear at the consumer. Congratulations, you’ve successfully sent two different event types to a topic! And unlike the newer subject name strategies, the union will prevent event types other than Product and Customer from being produced to the same topic, since the producer is configured with the default TopicNameStrategy.
Summary
Now there are two modular ways to store several event types in the same topic, both of which allow event types to evolve independently. The first, using the newer subject-name strategies, is straightforward but drops subject-topic constraints. The second, using unions (or oneofs) and schema references, maintains subject-topic constraints but adds further structure and drops automatic registration of schemas in the case of a top-level union or oneof.
If you’re interested in querying topics that combine multiple event types with ksqlDB, the second method, using a union (or oneof) is the only option. By maintaining subject-topic constraints, the method of using a union (or oneof) allows ksqlDB to deal with a bounded set of event types as defined by the union, instead of a potentially unbounded set. Modeling a union (also known as a sum type) by a relational table is a solved problem, and equivalent functionality will most likely land in ksqlDB in the future.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...