[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Migrating Confluent Cloud’s Most Critical Services into a New Deployment Management Platform
Confluent Cloud is a hosted platform for Apache Kafka®, Stream Designer, Connect, ksqlDB, and Schema Registry. All services that power Confluent Cloud are either packaged as a Kubernetes Helm chart or as a custom format that maps to a Custom Resource Definition (CRD). This blog post describes how we operationalized and migrated some of the most critical Helm-based services to our in-house deployment management platform.
Useful preliminaries
-
Helm: A package manager for Kubernetes manifests. Users can package their Kubernetes manifests as Helm charts. Optionally, the manifests can be templated using go templates. Helm comes with an API and a CLI to deploy Helm charts onto Kubernetes clusters.
-
CRD: Kubernetes API can be extended with Custom Resource Definitions (CRD). These are resources that are specific to the user infrastructure that are not natively supported by Kubernetes. Confluent Cloud uses CRDs to promote self-healing, elastic, and highly available deployment patterns. For more details, please refer to the Kubebuilder book.
-
Vault: Vault is an identity based secret management system. It supports several kinds of identity providers and several kinds of secrets. It has an internal identity system that acts as a bridge between custom identities and the secret engines. Vault allows users to export this identity as JSON Web Tokens (JWT).
-
JSON Web Token: A tamper-proof token that includes several predefined claims like when the token expires, who is this token meant for, and an opaque identity of the token holder. These claims are later signed and encrypted by a private key. Typically, a provider of JWTs also exposes an endpoint that is used to fetch public keys for decrypting these JWTs. Additionally, the specification also allows for custom claims, which can be used by services to include additional metadata.
-
Service version YAML: The declarative YAML spec used by our deployment platform to manage Helm repository, Helm version, and Helm values and other notification-related metadata.
Why a new deployment management platform?
Confluent Cloud supports AWS, Azure, and GCP cloud providers and runs on their managed Kubernetes offerings. Thus Confluent Cloud needs to deploy Helm-based services on multiple Kubernetes across all cloud providers. Before we built our new deployment management platform, deployments at Confluent were known as “Big Bang Releases” and happened every month. Every release had a directly responsible individual (DRI), who was responsible for getting sign-offs and deploying the entire infrastructure, enabling Confluent Cloud through either Terraform or Helm. This was a painful, undifferentiated, and error-prone process.
We built this deployment management platform to help alleviate some of the operational toil.
Deployment management platform overview
This section provides a brief overview of both the requirements and the high-level system architecture.
Requirements
- Support Helm service templates that reference Kubernetes metadata
- Deploy Helm service templates that reference secrets from Vault
- Allow Helm services to declaratively specify eligible Kubernetes cluster instances
- Automatically bootstrap foundational Helm services on newly provisioned Kubernetes
System architecture
Our platform embraces the controller pattern. Every Helm service specifies Kubernetes selection rules. During deployment time, the selection rules specified by the service are evaluated against all Kubernetes clusters and the service is queued for deployment on the selected Kubernetes instances. The controller orchestrates all necessary infrastructure changes to maintain this desired state. A reconcile loop runs periodically and attempts to deploy each service on all selected Kubernetes.
The reconcile loop encapsulates the core deployment logic and can be summarized as follows:
- Evaluate Helm template values from Vault secrets and/or Kubernetes metadata.
- Render the service Helm chart using the evaluated Helm values from the previous step. This produces a list of Kubernetes manifests.
- Stash the rendered Kubernetes manifests in a staging area. An agent running in each Kubernetes periodically polls this staging area and applies all manifests onto its Kubernetes.
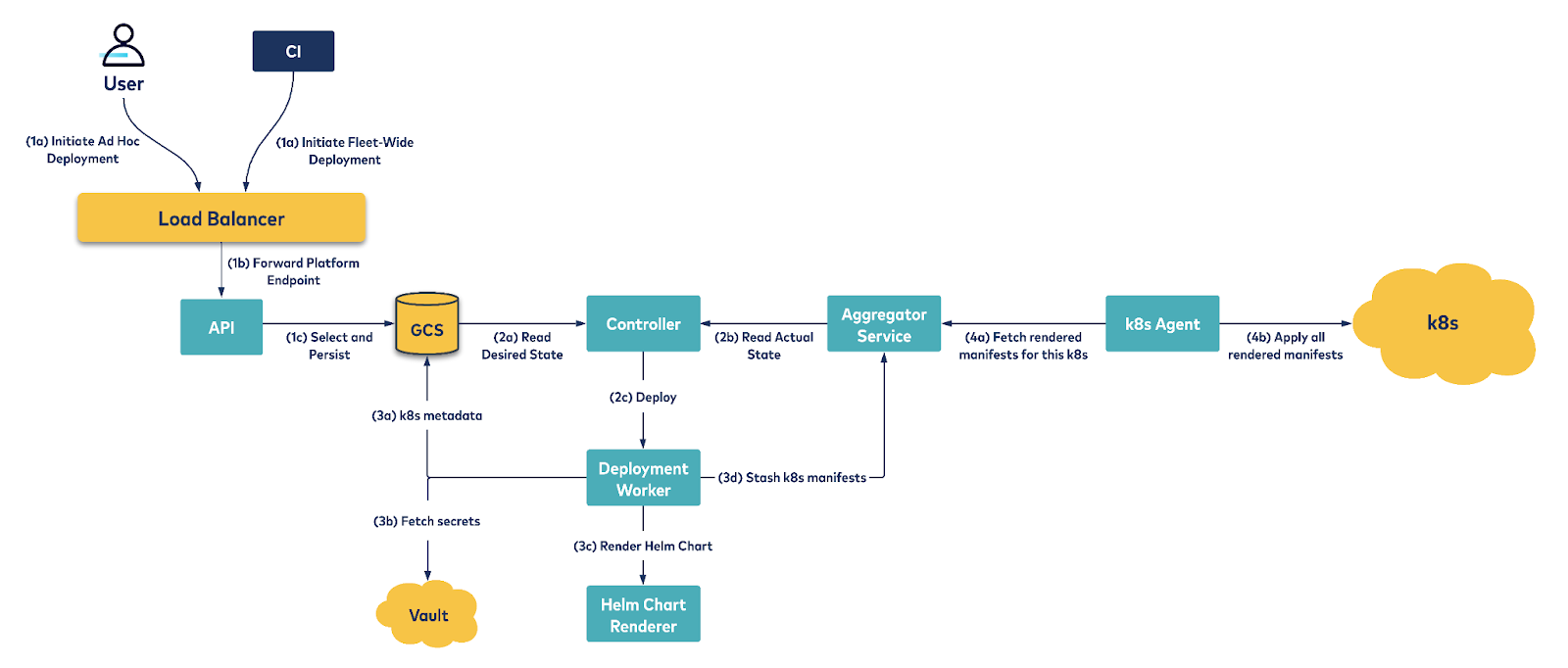
Additionally, the platform provides the following features:
- Deployment feedback
- Only consider a deployment as successful after the associated workload resources are up and running. This opens the door for service teams to configure deep health checks as readiness and liveness probes and fail fast.
- Auditable prod deployments
- Every time a deployment is scheduled to a prod environment, a Slack notification is sent to a configurable on-call channel. This notification includes details like Helm chart version, identity, location of the initiator, and more.
- Notifications on stuck deployments
- A deployment can get stuck due to a service error or an internal failure. Our platform tries to disambiguate between these two failure modes and sends Slack notifications to service on-call channels for the former and pages our on-calls for the latter.
- Declarative target selection
- Data plane Kubernetes clusters can come and go any time. Users should not have to keep track of the current set of Kubernetes and remember to include them during a fleet-wide deployment. Our deployment management platform leverages the ability to tag clusters and allows service owners to define target selection rules based on the cluster tags and other metadata.
- Immutable service version
- A service in our platform encapsulates a Helm chart and template Helm values. A service can have multiple versions and each version is considered immutable. This supports reproducible deployments and easy rollbacks. The service itself is managed as a YAML within a GitHub repository. This promotes Infrastructure-as-Code best practices.
- No circular dependencies
- The deployment platform will underpin all services that power Confluent Cloud. Hence we took care not to take dependency on any Confluent Cloud product while building this platform.
- Good CI integration
- Every push to the mainline branch of a repository automatically triggered the CI. Our deployment management platform integrates with the CI to generate a new service version and automatically deploy this version to the first pre-prod environment.
- Automatic Kubernetes bootstrapping
- Confluent Cloud automatically provisions new Kubernetes clusters to run customer workloads. These Kubernetes require internal services to manage several cross-cutting concerns. Our deployment management platform automatically deploys eligible internal services on new Kubernetes clusters.
Problem statement
The task was to migrate all control plane services that power Confluent Cloud to our new deployment platform. This migration was necessary to make the deployment process more secure, auditable, and less error prone.
Design considerations
Some of the key tenets were:
- Simple and boring migration
- Our users had to learn a new deployment platform and perform undifferentiated work to migrate to it. Hence one of our North Star goals was to remove any ambiguity. We achieved this by building new features, investing in automation, and taking over some parts of the migration process. In addition, we also wrote up precise migration guides and walked through the migration in several company-wide forums.
- Scalable
- At the time of this migration, each component of the deployment platform ran on a single pod and was only vertically scalable. Ideally, we’d have liked it to be horizontally scalable. But the migration was also fairly urgent. Hence the challenge was to identify and fix some obvious performance bottlenecks and prove that the platform would be able to support the new services being migrated.
- Secure
- At the time of this migration, all agents shared the same credential. This was a huge security risk as a compromised Kubernetes could impersonate any other Kubernetes and fetch its manifests.
Detailed design
Simple and boring migration
Our overall migration strategy was based on the following observation:
As long as no immutable attributes of Kubernetes manifests (like Helm-release name, Kubernetes deployment selectors, etc.) change, the migration can be done in place. In particular, we don’t need to spin up a new instance of the service in a separate namespace. Further, if there wasn’t any change in the corresponding workload’s podTemplateSpec, it would be a zero downtime migration.
This observation led to a simple migration strategy:
- Users define their service version YAML and submit a PR
- Our team ensures that there is no difference in the dry-run output produced using the previous deployment tool and the dry-run output produced using the new deployment management platform
- Once approved, the user proceeds to deploy their service using the new deployment management platform
We also made several improvements that simplified both the YAML definition step and the verification step:
- Support existing secret handling semantics: Existing deployment tool stored Helm values as YAML in a secret store. It used to only support reading individual keys from objects stored in the secret store. We added support for reading Helm value fragments stored as YAML from the secret store. This allowed users to reuse their existing secrets without having to copy them over.
- Automate migration process: We observed that most of the migration involves copying over Helm values from an existing repository and saving them into a new service YAML format. We automated this process with scripts, so users could simply use our tool to generate their service YAMLs and submit PRs.
- Dry run and diff tools: We improved the verification process by adding several CLI tools in the platform. These tools helped with producing deployment dry runs and diffing against the dry run output of the existing tools.
Additionally, as a way of earning trust, our team signed up to migrate the most critical Confluent Cloud service early in the migration timeline. Once we demonstrated how seamless the migration process was, it created a snowball effect and everyone signed up to migrate their services over.
Scalable
Our new deployment management platform is composed of several components. Each is managed as a Kubernetes Deployment workload with a single pod. At startup, each component loads all its state into memory and serves all read requests from memory. Thus our deployment management platform was only vertically scalable.
The services that power Confluent Cloud are heavily developed and hence could pose significant load on the deployment platform. One option was to delay the migration until after the platform was made horizontally scalable. However, the migration was very critical in securing and improving the deployment experience for our internal users and delaying it was the last resort. So we identified several improvements and wanted to test the effects of making these improvements.
- Reduce GCS default buffer size: GCS was used as our backend data store. The controller made several calls to GCS as it was reconciling between the desired and actual state. By default GCS uses ChunkSize of 16MB. Because most of the objects managed by our platform are a lot smaller, this caused a lot of internal memory fragmentation especially during each run of the controller job.
- Load software versions on demand: Our platform keeps every object in memory. Confluent Cloud service repositories typically receive lots of commits on a daily basis. Thus our platform could be quickly overwhelmed. We made a change to keep only the deployed service versions in memory.
- Turn off MADV_DONTNEED: We migrated to go-1.16. By default, MADV_DONTNEED is enabled. Turns out this can be disruptive to workloads that allocate lots of small objects.
Together, these changes helped to reduce the memory footprint from over 3GB to about 256MB. We essentially applied a bunch of tactical fixes and performed load testing to verify that we will be able to absorb the services. Please scroll down to learn more about our future plans.
Scale testing
The next step was to do load simulation and verify the limits of our platform.
For any performance testing, it is helpful to come up with a load factor and important service metrics. Then, we iteratively modify various dimensions of the load factor and measure the service metrics. The point at which service metrics drop below our SLO is typically considered a tipping point.
As mentioned earlier, the core component of our architecture is a controller process. Its sole job is to ensure that all service deployments in all Kubernetes clusters are successful. As of Q2 2021, it took about 800ms to run an iteration of the controller loop. Thus, our load factor is defined as the cross product of the number of Kubernetes and the number of services deployed in each Kubernetes.
Our testing strategy was to increase the number of Kubernetes and the number of services deployed in each Kubernetes and measure both the end-to-end deployment latency and the controller runtime.
Provisioning a large number of new Kubernetes clusters for testing purposes would have been prohibitively costly. Hence we simulated lots of Kubernetes by spinning up a separate process which ran thousands of goroutines, each corresponding to a modified Kubernetes. Additionally, we also simulated fake services that would be deployed to each Kubernetes.
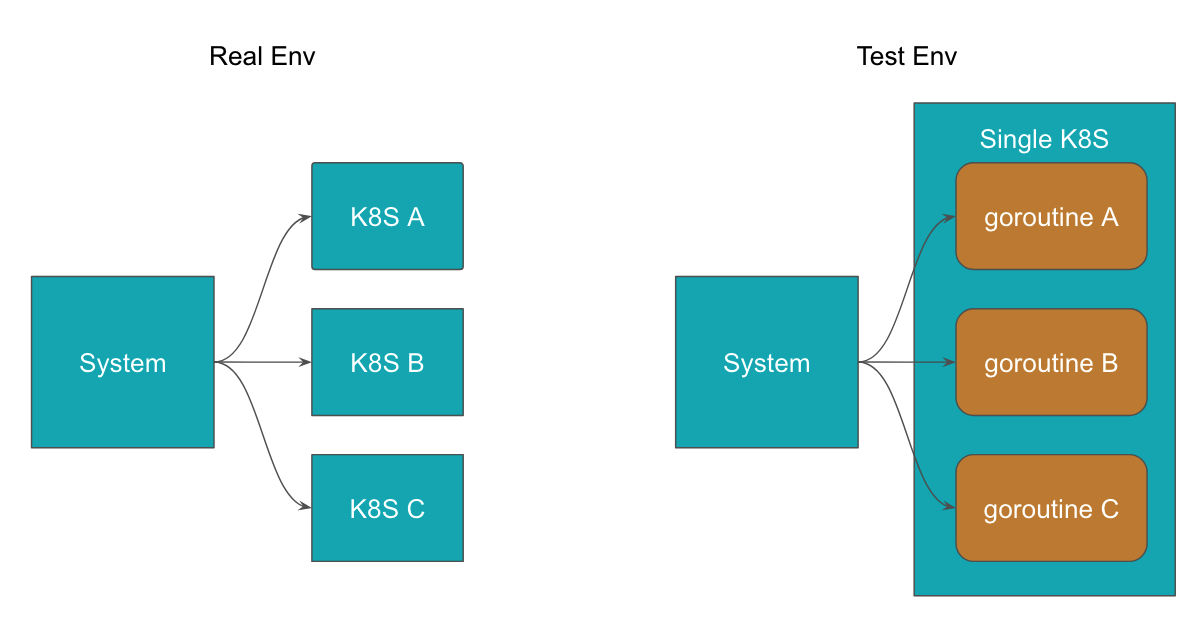
With this setup, we were then able to quickly iterate on testing.
We were able to prove that our platform could support up to 10x the expected new load without too much degradation in controller runtime or end-to-end deployment latency.
Secure
Primer on service-to-service authentication using Vault
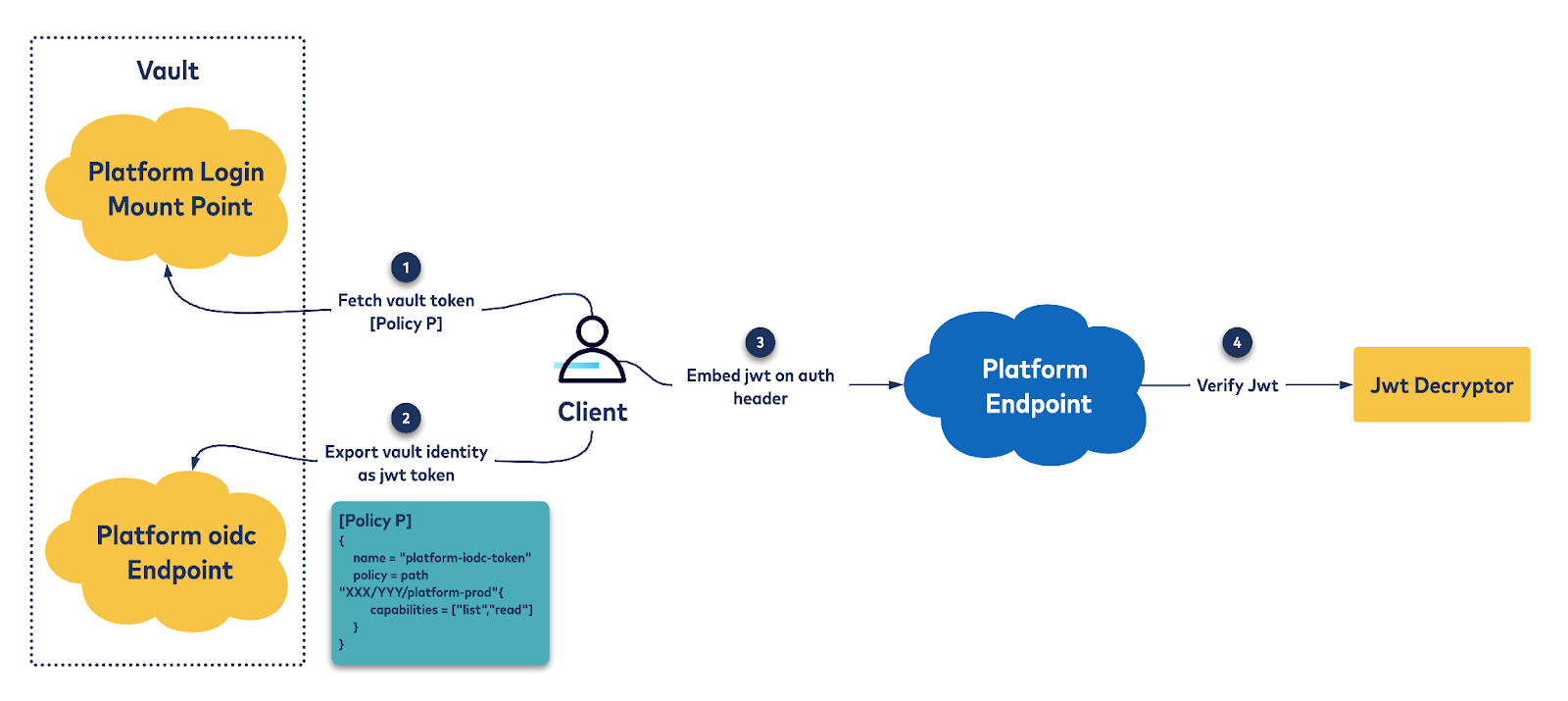
The deployment management platform uses Vault to perform service-to-service authentication. In particular, it uses the Identity secret engine. The basic idea is that the deployment management platform exposes an OIDC provider endpoint using Vault to export authenticated Vault-tokens as signed JSON Web Tokens (JWTs). These JWTs have custom claims that can be used to uniquely identify the caller and associate permissions. Let’s look at the user journey.
Client side
- Log in to Vault using one of the supported auth methods. This yields a Vault token. If this client is allow-listed to access our platform, their token contains a policy granting them access to our OIDC endpoint.
- Issue a request to our platform’s OIDC endpoint. This exchanges the Vault token for a signed JWT. This JWT has several custom claims that are used by our platform to verify the caller and their permissions.
- This signed JWT is set as the auth header of the request and sent via TLS to the server.
Server side
- Extract the signed JWT and decrypt it using the Vault OIDC discovery endpoint.
- Verify that the caller has permissions to issue the request on the corresponding resource.
Problem
All Kubernetes agents used the same Vault authentication role. Thus a compromised Kubernetes can impersonate any other Kubernetes and fetch the manifests not meant for it.
Approach
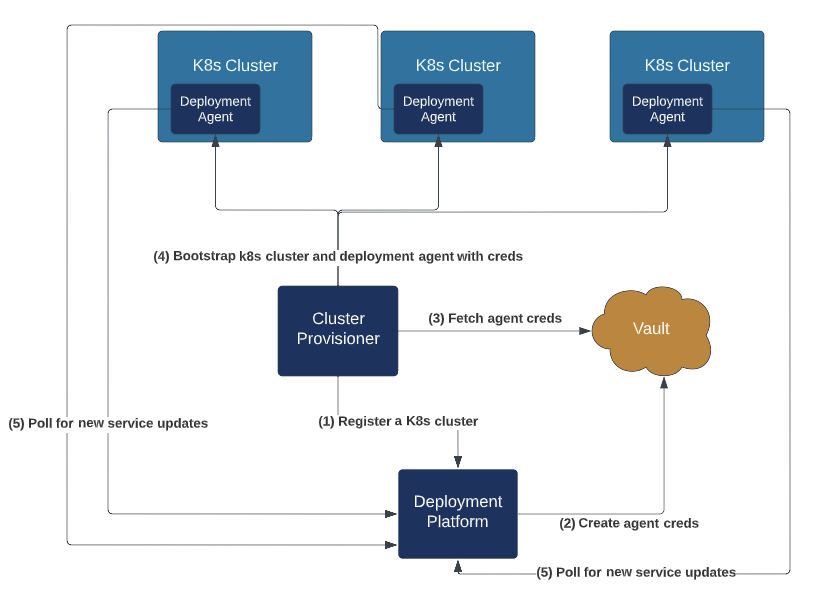
At a very high level, we dynamically created Vault authentication roles for each new Kubernetes. We also migrated the existing Kubernetes off of the shared Vault authentication role. The biggest challenge was arranging coordination between the various actors in a backwards compatible manner.
This solution involved several actors. The following lists each of them and their role in the solution:
- Bootstrap Vault infrastructure
- Set up a new Vault authentication mountpoint.
- This isolated the new authentication roles to each specific cluster and helped restrict permissions on who can create and manage these roles.
- Kubernetes provisioner
- Invoked a new deployment platform endpoint to configure the Vault login role for each Kubernetes.
- Bootstrap the Kubernetes using the role created above.
- Deployment platform
- Expose a new endpoint for configuring a login role for each Kubernetes. This endpoint encapsulated backwards compatibility and allowed staged rollout of this feature.
- Register the expected identity that each Kubernetes agent will be presenting. This was compared with the actual identity presented by the Kubernetes agent and manifests were returned only if the identity matched.
- Kubernetes agent
- Use the new role to login to Vault.
- Continue to stamp the JWT in the auth header of each request.
Other security fixes
In addition to securing Kubernetes agent communication, we also added support for RBAC in each endpoint of the deployment management platform. This helped us restrict:
- Who can deploy a given service?
- Who can manage Kubernetes?
Impact
- As part of the team's goals for Q3 2021, we wanted to migrate about 70% of the services in the control plane fabric into our deployment platform. We not only migrated all of them but we also migrated all services in the monitoring plane into our platform.
- We were able to reduce costs through driving down memory utilization by 90%.
- We migrated away from global shared authentication roles. Each Kubernetes had its own authentication role, promoting the critical cybersecurity principle of least privilege.
- We locked down all our endpoints and enabled RBAC support for all mutating endpoints. We continued to grant access to all on-call operators to our read endpoints.
- We invested heavily on improving visibility on stuck deployments. We also wrote up detailed user guides to help troubleshoot stuck deployments.
- Last but not the least, we defined SLOs, created new KPI dashboards, and participated in the company-wide operational readiness reviews.
Future
Our team is experiencing a challenging yet exciting time!
We’re beginning to see the limits of vertical scaling in our aggregation server. We’re also beginning to see some operational challenges in using Vault-based service-to-service authentication. Users are coming to us with increasingly complex services that fully embrace controller patterns and services that need target selection at runtime and across different failure domain boundaries.
This is forcing us to go back to first principles and re-architect the system from the ground up. As we go through this process, we are seeing how much our users care about our platform, which makes all of us super proud!
If managing cloud-native infrastructure at scale interests you, please reach out to Rashmi Prabhu, Decheng Dai, or Ziyang Wang—we’re hiring!
Credits
While the authors were responsible for planning and executing this migration, we received a lot of support and guidance along the way.
First and foremost, we wish to thank all Confluent teams for trusting us enough to onboard some of their critical workloads on this platform. They onboarded in a timely manner and provided tons of feedback for improving the platform as well. Second, we want to thank the founding members of this platform for their tireless efforts in developing and productionizing it. We also thank the entire leadership team and the TPM team for being enthusiastic supporters and guides. Last but not the least, we wish to thank our Kubernetes infrastructure group of teams. They worked closely with us to arrange the security fixes.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



How Confluent Treats Incidents in the Cloud
An inevitable consequence of rapid business growth is that there will be incidents: even the best, most well-planned systems will begin to fail when you expand them very quickly. The […]

Design Considerations for Cloud-Native Data Systems
Twenty years ago, the data warehouses of choice were Oracle and Teradata. Since then, growth and innovation has shifted to the cloud, and a new generation of data systems have […]