[Live Demo] Tableflow, Freight Clusters, Flink AI Features | Register Now
Migrating Data from On-Premises Data Platforms to Databricks Delta Lake in AWS
Today, we are excited to announce the preview release of Confluent’s Databricks Delta Lake Sink Connector for Confluent Cloud. This connector allows you to reliably and cost effectively implement continuous real-time syncs by offloading data from legacy on-premises databases, data lakes, and data warehouses to Databricks Delta Lake using Confluent to transform and enrich data from multiple sources. This will accelerate migrations and modernization initiatives to unlock new real-time analytics with Databricks in the cloud.
For example, enterprises can pull on-premises data warehouse (e.g., Oracle) data into Confluent Cloud, preprocess and prep the data in ksqlDB, and send it off to Databricks Delta Lake with our fully managed connector. This allows data warehouse modernization initiatives to reduce the total cost of ownership (TCO) of data pipelines with fully managed connectors, open up net new vertical-specific analytics in Databricks, and have a multicloud and hybrid environment that allows for data to be immediately migrated in days rather than years.
Our new fully managed connector eliminates the need for the development and management of custom integrations, and thereby reduces the overall operational burden of connecting your data between Confluent Cloud and Delta Lake on Databricks.
Before we dive into the Delta Lake on Databricks Sink Connector for Confluent Cloud, let’s cover what Databricks Delta Lake is and what it does.
What is Delta Lake on Databricks and how does Confluent make it better?
Databricks Delta Lake is an open format storage layer that delivers reliability, security, and performance on your data lake—for both streaming and batch operations. By replacing data silos with a single home for structured, semi-structured, and unstructured data, Delta Lake is the foundation of a cost-effective, highly-scalable lakehouse.
Together, Databricks and Confluent form a powerful and complete data solution focused on helping companies operate at scale in real-time. With Confluent and Databricks, developers can create real-time applications, enable microservices, and leverage multiple data sources driving better business outcomes.
The Databricks Delta Lake Sink connector supports exactly-once semantics “EOS”, by periodically polling data from Apache Kafka® and copying the data into an Amazon S3 staging bucket, and then committing these records to a Databricks Delta Lake instance.
Databricks Delta Lake Sink Connector for Confluent Cloud in action
Let’s now look at how you can create a CDC pipeline between Oracle Database and Databricks Delta Lake with Confluent’s fully managed Databricks Delta Lake Sink Connector. While this demo focuses on sourcing the data from Oracle, you can use the Databricks Delta Lake Sink Connector with many other sources like Teradata, DB2, HDFS, SQL Server, Postgres, and Salesforce. Check out the many source options on Confluent Hub.
Demo scenario
Your company—we’ll call it Big Bank—is a big Oracle shop and runs lots of Oracle databases to store transactions related to the business. Big Bank implemented Salesforce a couple of years ago to perform CRM functions and we’ll be using account and contact data from Salesforce. You’re a security engineer on the newly minted Security Data Science team charged with helping to avoid cost by leveraging Databricks Delta Lake to detect (and prevent) fraud based on customer behavior. The Security Data Science team wants to harness existing customer data and apply the latest machine learning technologies and predictive analytics to enrich historical customer data with real-time financial transactions. However, there are three challenges:
- Your DBAs likely don’t want the Data Science team to directly and frequently query the tables in the Oracle databases due to the increased load on the database servers and the potential to interfere with existing transactional activity
- The security data science team doesn’t like the transactional schema anyway and really just wants to write queries against Databricks for performing predictive analytics
- If your team makes a static copy of the data, you need to keep that copy up to date in near real time
Confluent’s Oracle CDC Source Connector can continuously monitor the original database and create an event stream in the cloud with a full snapshot of all of the original data and all of the subsequent changes to data in the database, as they occur and in the same order. The Databricks Delta Lake Sink Connector can continuously consume that event stream and apply those same changes to the Databricks Delta Lake Enterprise Data Warehouse.
This blog post covers the high-level steps for configuring the connector, for more detailed information please see the Databricks Delta Lake Sink Connector for Confluent Cloud documentation. For more details on sourcing data from Oracle Databases see the Oracle CDC Source Connector for Confluent Platform documentation.
Set up the connector
The Databricks Delta Lake Sink Connector is currently only available as a preview Confluent Cloud on AWS.
For our example, we’ll be using a Confluent Cloud Cluster on AWS. If you are new to Conflent Cloud and need to set up a cluster, check out Quick Start for Apache Kafka using Confluent Cloud.
From the Databricks SQL Notebook, create your target table. The connector adds a field named partition which is used to support the exactly-once semantics (EOS) feature. Your Delta Lake table must include a field named partition using type INT (partition INT) per the example below.

On the Cluster overview page, select Add a fully managed connector and then choose the Databricks Delta Lake Sink connector.
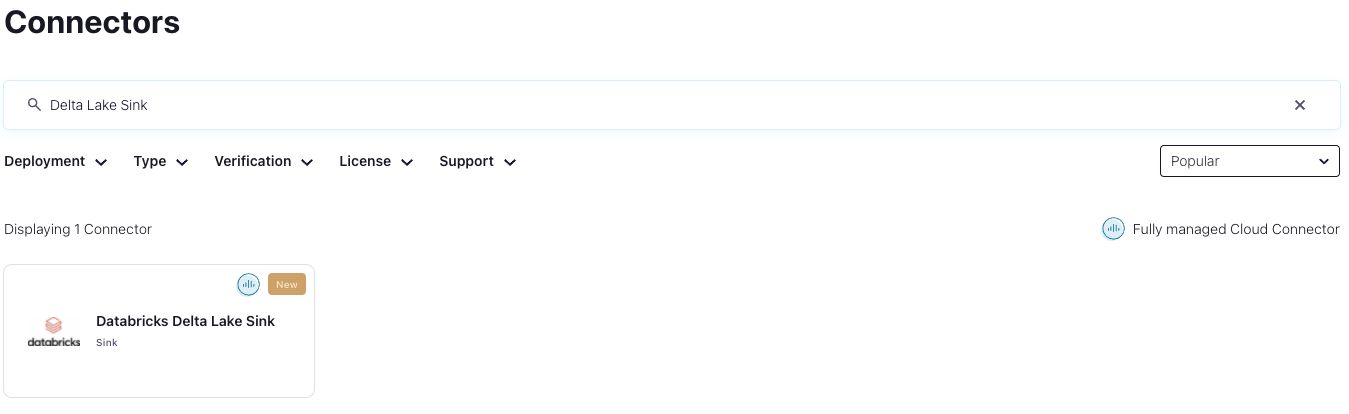
The “Add Databricks Delta Lake Sink Connector” form opens and you can specify your topic(s), input message format, and Confluent Cloud credentials.
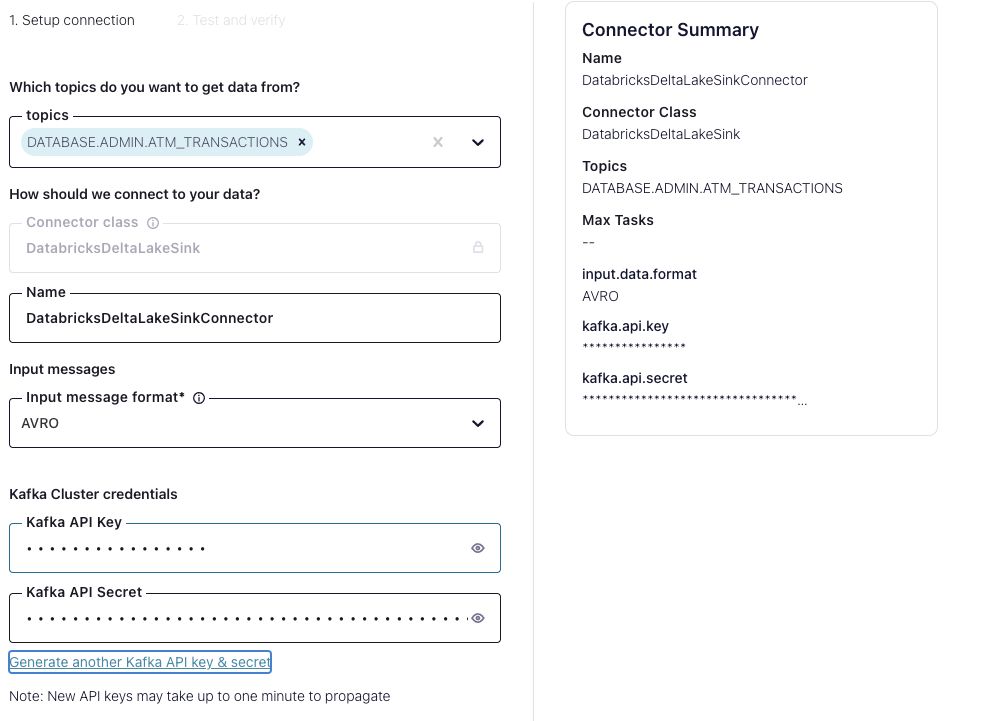
Complete the connector configuration by entering your Delta Lake Host Name, Delta Lake HTTP Path, Delta Lake Token and Delta Lake Table(s), AWS S3 staging bucket credentials, and S3 Staging bucket that you have configured for use with the connector.

At the bottom of the form, click Next to review the details for your connector, and click Launch to start it.

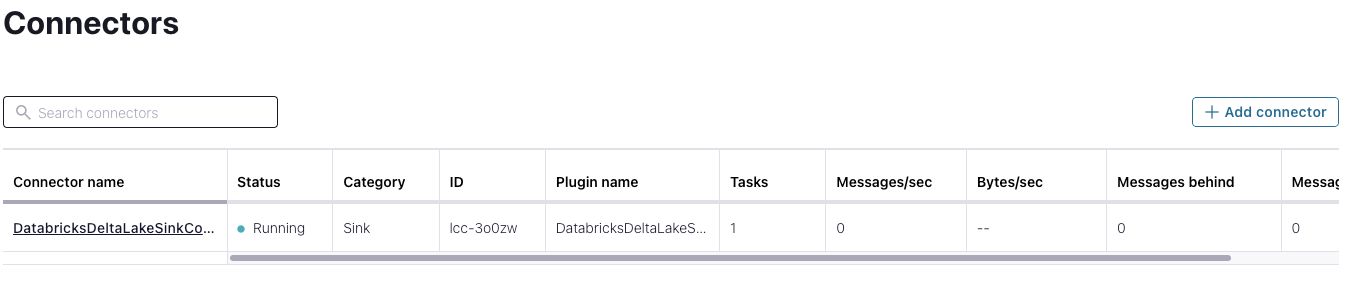
On the “Connectors” page, the status of your new connector reads “Provisioning”, which lasts for a few minutes. When the status changes to “Running”, your connector is copying data to the Databricks Delta Lake ATM_TRANSACTIONS table.
Using Databricks SQL Notebook, verify the data in your target table(s).
![]()
You now have a working CDC pipeline from an Oracle database through to Databricks Delta Lake Sink Connector for Confluent Cloud.
Learn more about the Databricks Delta Lake Sink Connector for Confluent Cloud
To learn more about Databricks Delta Lake Sink Connector for Confluent Cloud, visit us at AWS re:Invent. Stay tuned for the General Availability of the connector!
If you’d like to get started with Confluent Cloud, sign up in AWS Marketplace and get a free trial of Confluent Cloud* and check out the Databricks Delta Lake Sink Connector preview!
Further reading
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Streaming Data Fuels Real-time AI & Analytics: Connect with Confluent Q1 Program Entrants
This is the Q1 2025 Connect with Confluent announcement blog—a quarterly installment introducing new entrants into the Connect with Confluent technology partner program. Every blog has a new theme, and this quarter’s focus is on powering real-time AI and analytics with streaming data.



Driving Real-Time Innovation: Meet the Five New Build with Confluent Partners
Jump-start a new use case with our new Build with Confluent partners and solutions.