[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Announcing ksqlDB 0.9.0
We’re pleased to announce the release of ksqlDB 0.9.0! This version includes support for multi-join statements, enhanced LIKE expressions, and a host of usability improvements. We’ll go through a few of the key changes, but you can see the changelog for a detailed list of all fixes and improvements.
Multi-join expression support
ksqlDB has allowed you to use queries with joins since its inception, but multiple joins in a single statement were not possible.
Starting today, you can collapse multiple joins into a single statement. This is crucial not only because it makes ksqlDB programs more concise, but also because it reduces the number of intermediate streams and topics for temporary joined data and is a much more efficient way to execute multiple joins.
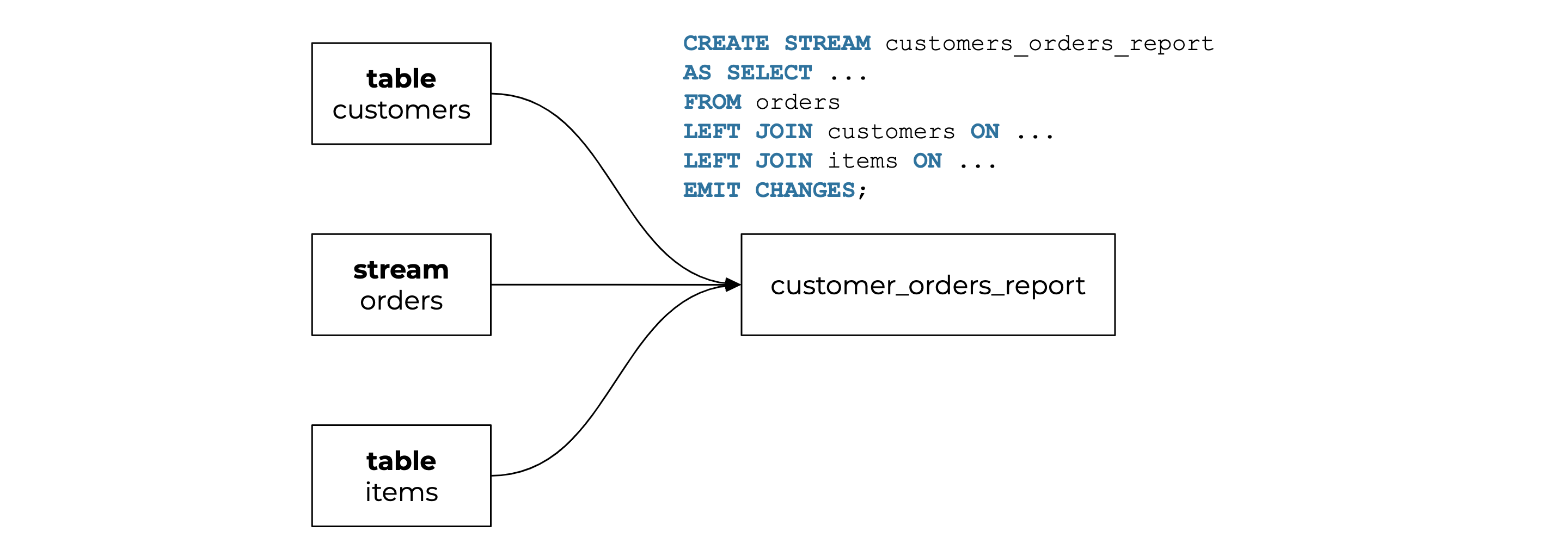
For example, let’s say we have two tables (customers and items) and one stream (orders) that have purchasing orders from an online store.
ksql> CREATE TABLE customers (customerid STRING, customername STRING) WITH (KAFKA_TOPIC='customers', VALUE_FORMAT='json', KEY='customerid');
ksql> CREATE TABLE items (itemid STRING, itemname STRING) WITH (KAFKA_TOPIC='items', VALUE_FORMAT='json', KEY='itemid');
ksql> CREATE STREAM orders (orderid STRING, customerid STRING, itemid STRING, purchasedate STRING) WITH (KAFKA_TOPIC='orders', VALUE_FORMAT='json', KEY='orderid');
| ℹ️ | Note: As of 0.10, the KEY property in the WITH clause is not supported. To specify a key, use the PRIMARY KEY keyword for tables, and the KEY keyword for streams in the schema column definition. For example:
CREATE TABLE customers (customerid STRING PRIMARY KEY, ...) CREATE STREAM orders (orderid STRING KEY, …) |
With these example records:
# customers
{"customerid": "1", "customername": "Adrian Garcia"}
{"customerid": "2", "customername": "Robert Miller"}
{"customerid": "3", "customername": "Brian Smith"}
# items
{"itemid": "1", "itemname": "Television 60-in"}
{"itemid": "2", "itemname": "Laptop 15-in"}
{"itemid": "3", "itemname": "Speakers"}
# orders
{"orderid": "1", "customerid": "1", "itemid": "1", "purchasedate": "2020-05-01"}
{"orderid": "2", "customerid": "1", "itemid": "2", "purchasedate": "2020-05-01"}
{"orderid": "3", "customerid": "2", "itemid": "1", "purchasedate": "2020-05-01"}
{"orderid": "4", "customerid": "3", "itemid": "1", "purchasedate": "2020-05-03"}
{"orderid": "5", "customerid": "2", "itemid": "3", "purchasedate": "2020-05-03"}
{"orderid": "6", "customerid": "2", "itemid": "2", "purchasedate": "2020-05-05"}
…let’s generate a report of all orders and customers who made purchases, and write that report in the topic customer_orders_report. This should include customer and item names.
Using the old way (ksqlDB 0.8.x and lower), you would need to create a temporary stream to join customers - orders records, then create your final stream to join the temporary_stream - items to generate the report:
ksql> CREATE STREAM tmp_join AS SELECT customers.customerid AS customerid, customers.customername, orders.orderid, orders.itemid, orders.purchasedate FROM orders INNER JOIN customers ON orders.customerid = customers.customerid EMIT CHANGES;
ksql> CREATE STREAM customers_orders_report AS SELECT customerid, customername, orderid, items.itemname, purchasedate FROM tmp_join LEFT JOIN items ON tmp_join.itemid = items.itemid EMIT CHANGES;
With ksqlDB 0.9.0, just create the final stream with the joins you need to create the report:
ksql> CREATE STREAM customers_orders_report AS
SELECT customers.customerid AS customerid, customers.customername, orders.orderid, tems.itemid, items.itemname, orders.purchasedate
FROM orders
LEFT JOIN customers ON orders.customerid = customers.customerid
LEFT JOIN items ON orders.itemid = items.itemid
EMIT CHANGES;
Take a look at this query, which reads data from your previous report. It shows columns from customers, items, and orders.
ksql> SELECT customername, itemname, purchasedate FROM customers_orders_report EMIT CHANGES; +-----------------+----------------------------------+ | CUSTOMERNAME | ITEMNAME | PURCHASEDATE | +-----------------+-----------------+----------------+ | Adrian Garcia | Television 60" | 2020-05-01 | | Adrian Garcia | Laptop 15" | 2020-05-01 | | Robert Miller | Television 60" | 2020-05-01 | | Brian Smith | Television 60" | 2020-05-03 | | Robert Miller | Speakers | 2020-05-03 | | Robert Miller | Laptop 15" | 2020-05-05 |
This also works with any previously supported joins, such as inner, left, and outer joins. There is no limit to the number of joins in a single statement. Normal restrictions apply (e.g., you can’t repartition tables).
More powerful LIKE expressions
ksqlDB supports pattern matching using LIKE expressions. Until now, the wildcard character, %, was supported only at the start and end of the pattern expression.
With ksqlDB 0.9.0, LIKE expressions support the % character at any position. You can also use the underscore (_) character to match exactly one character in the value.
Furthermore, the new ESCAPE clause has been added to complement LIKE expressions. ESCAPE allows you to specify an escape character in the pattern, so that special characters in the condition are interpreted literally.
This is what a LIKE clause looks like:
SELECT ... FROM ... WHERE field [NOT] LIKE condition [ESCAPE escape_string]
The following statement queries all records that contain a message with 90—99% of CPU usage (assuming there are no letters next to the “9” number):
SELECT * FROM logs WHERE message LIKE “%cpu = 9_/%%” ESCAPE ‘/’;
And there’s more!
A new built-in function, COALESCE, as well as various bug fixes and other improvements are included in this release. See the full list of fixes and improvements in the changelog.
If you haven’t already, join our #ksqldb Confluent Community Slack channel and get started with ksqlDB today!
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Stop Treating Your LLM Like a Database
GenAI thrives on real-time contextual data: In a modern system, LLMs should be designed to engage, synthesize, and contribute, rather than to simply serve as queryable data stores.



Generative AI Meets Data Streaming (Part III) – Scaling AI in Real Time: Data Streaming and Event-Driven Architecture
In this final part of the blog series, we bring it all together by exploring data streaming platforms (DSPs), event-driven architecture (EDA), and real-time data processing to scale AI-powered solutions across your organization.