[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Kafka Streams Interactive Queries Go Prime Time
What is stopping you from using Kafka Streams as your data layer for building applications? After all, it comes with fast, embedded RocksDB storage, takes care of redundancy for you, is highly scalable, and provides exactly-once semantics. Building off of the blog post Can Apache Kafka Replace a Database? – The 2020 Update, where Kai Waehner explains how to use Kafka Streams to build highly scalable microservices, this article focuses on the one thing Kafka Streams was missing until now: high-availability guarantees.
Consistency vs. availability
Every application demands different consistency guarantees. A financial application transferring money from one customer to another has to be strongly consistent. In contrast, a recommendation engine may be content with a weaker consistency model if it comes at the cost of availability. One of the fundamental challenges in distributed systems is achieving a delicate balance between consistency and availability. Kafka and Kafka Streams both provide many configurations to tune applications for such a balance. For instance, in Kafka, tuning the number of replicas, in-sync replicas, and acknowledgment gives you a wider range of availability and consistency guarantees.
Similarly, for querying, Kafka Streams (until version 2.4) was tuned for high consistency. You can have N replicas in the system, but querying support is limited to only active partitions. That means, in case you serve the state stored in Kafka Streams with REST APIs, you have downtime if one of the VMs handling active partitions becomes unavailable. The active partitions that went down are only able to serve queries when they get reassigned by a new rebalance, and they restore themselves to their previous state before going down. The process of re-election and restoration can take anywhere between a few seconds to a few minutes. For certain time-sensitive applications, this could be disastrous because data can’t be served for the customers residing on the partitions that went down. At Walmart, system unavailability poses a significant challenge, as serving older data is still a lot better than not serving any data at all for our use case.
Our challenge: Availability at Walmart scale
At Walmart, we have been using Kafka Streams for a couple of years to build our one-stop customer data platform. The platform ingests billions of interaction and transaction events a day, serves the derived knowledge with REST APIs, and also triggers various customer-based machine learning models subscribed to specific events. One of the primary use cases in e-commerce is fraud detection, such as the example depicted below, and using Kafka Streams as a database for this use case makes sense if you are already processing the required profile and transaction events.

The fraud detection model is part of the transaction flow and gets triggered at every cart checkout. So, the process of serving data to the model and running the actual model with it to identify fraud has to be completed in milliseconds. The queries used to fetch user history from the platform come with very stringent SLAs, so we have to optimize Kafka Streams for high availability and low latency. We added a few Kafka Improvement Proposals (KIPs) to Kafka Streams, which reduced serving downtime and helped us achieve single-digit serving latencies. These improvements are covered in the sections below.
Serving from stale stores with KIP-535
As previously discussed, it is common in a cloud environment for VMs to become unreachable, which leads to disruption of service. One of the biggest reasons for this is cloud patches. As much as patches are essential to fix bugs and vulnerabilities, they can potentially impact system availability. A patch on a single VM triggers at least two rebalances in the application, once when it leaves the cluster and again when it rejoins after the patch, and both actions lead to the failure of API requests. For Walmart, a patch takes almost 10–15 minutes per VM. Once the VM rejoins the cluster, the complete exercise of removing it from the cluster, creating a new standby somewhere else, and electing an active, becomes futile.
To avoid this, one option is to increase the session.timeout.ms setting to 15 minutes. The problem with that option is failure of REST calls for the active partitions on the VM, which has gone down. This diminished availability during rebalancing led us to challenge the status quo and find a way to increase the availability of our application during rebalancing or when a VM goes down.
KIP-535 (allowing state stores to serve stale reads during rebalancing) was introduced in the Kafka 2.5 release to solve the challenges discussed above. It added two discovery mechanisms that users can implement to a query routing layer: exposing the partition for a specific key and identifying the location and freshness of each standby for each partition of a store. Furthermore, it introduced a key mechanism needed for a resilient query fetch layer, the ability to serve queries from hot/warm standbys and hot-restoring actives to enable querying during rebalancing. This KIP exposes the lag on each standby, and applications can use it to configure how much lag on a standby it can serve. The illustration below details how this KIP tackles each case and gives an option to developers to increase availability in their application.
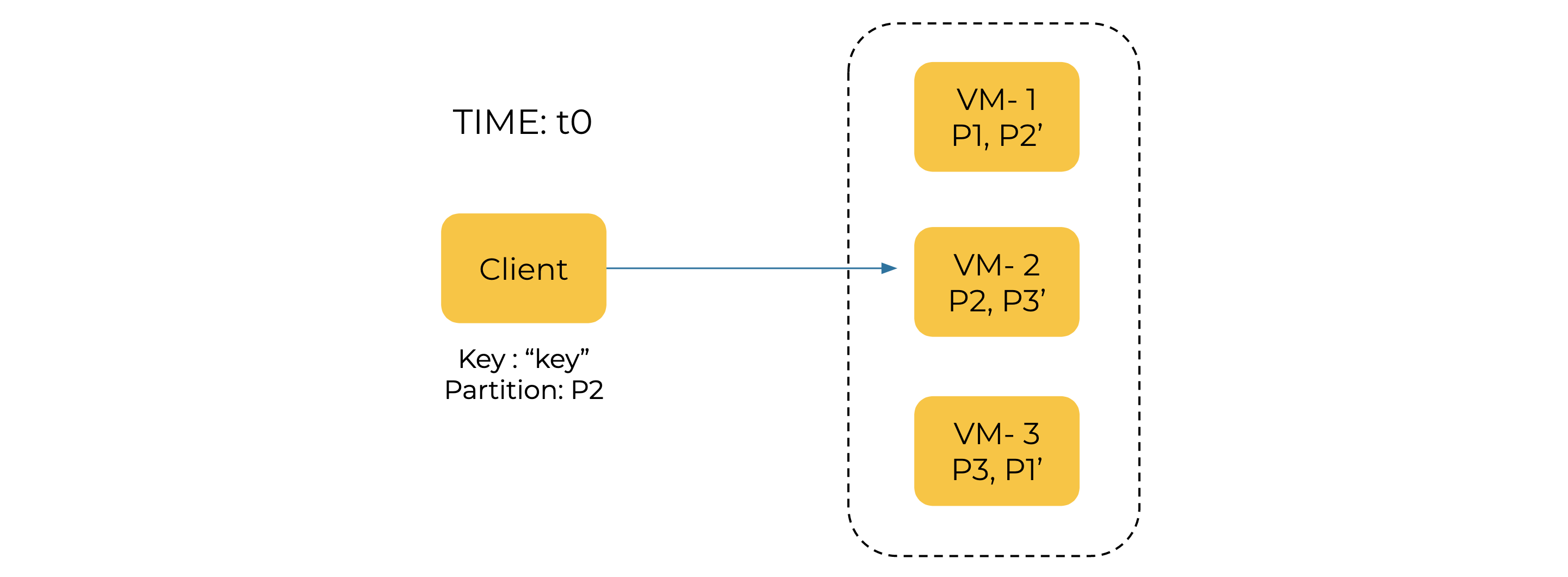
At time t0, the query to the partition P2 is served from the VM-2, where P2 is active partition 2 and P2’ is the standby partition.
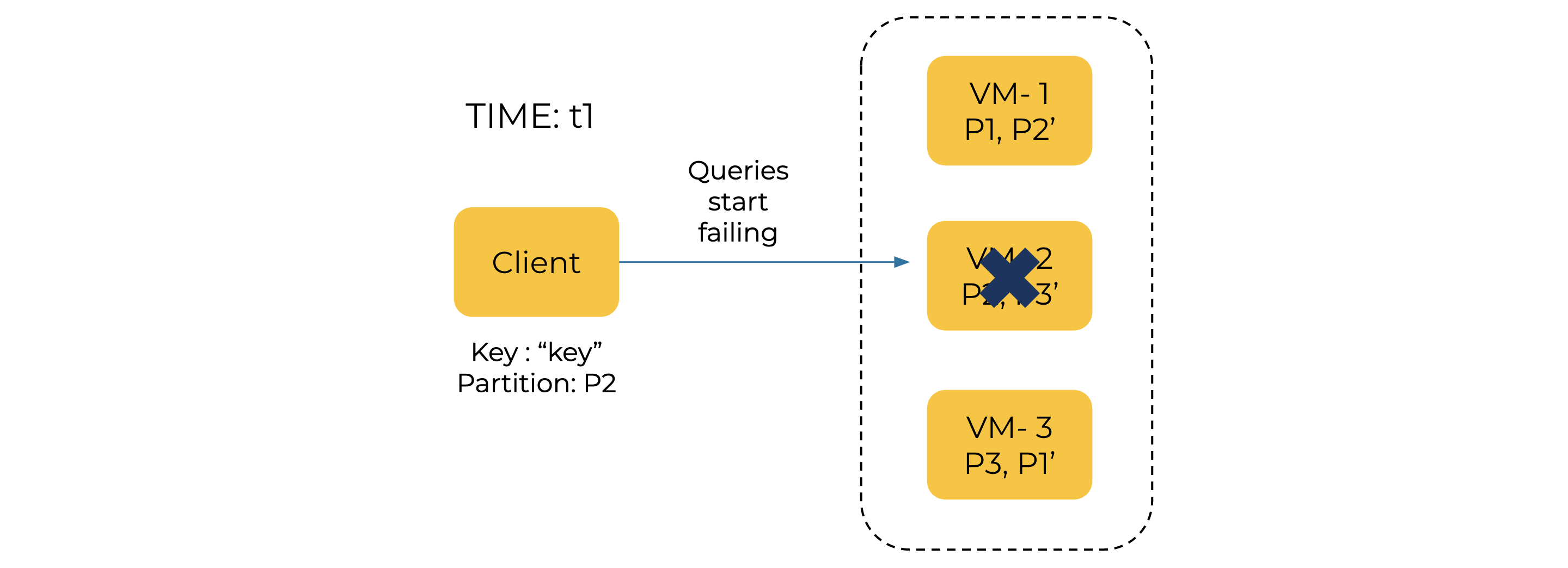
At time t1, VM-2 becomes unavailable. So, all the queries to this VM start failing.
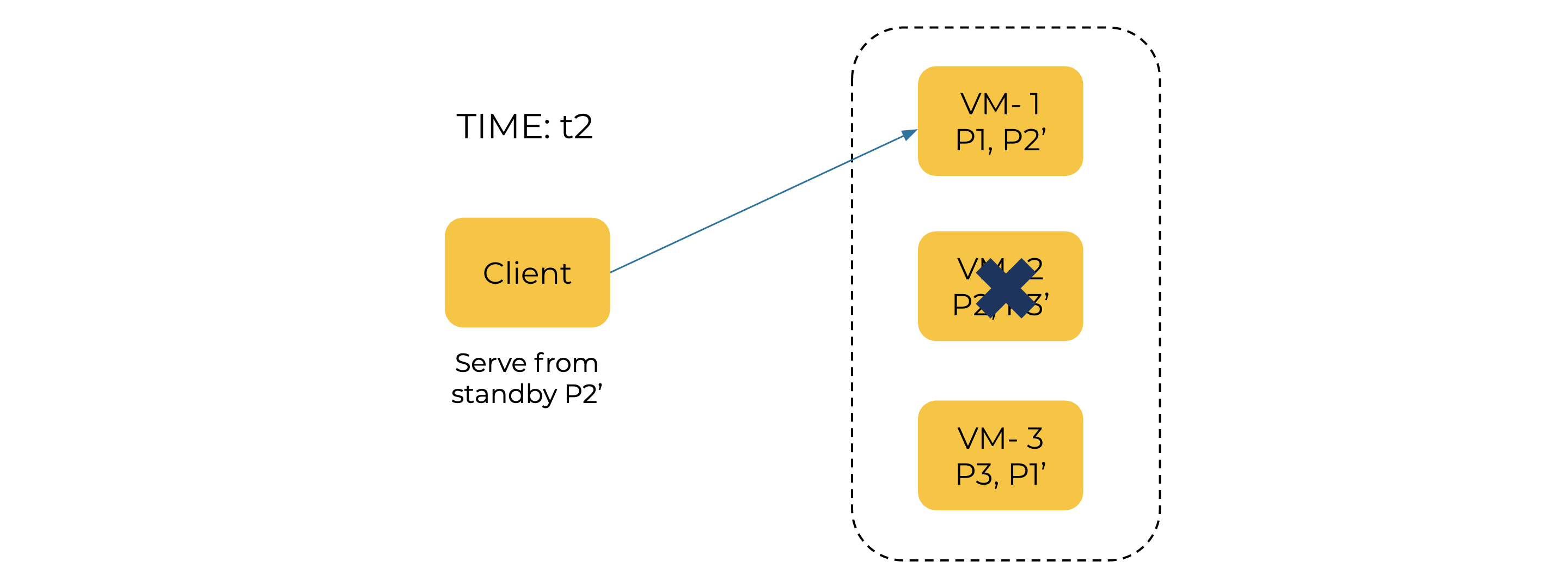
All the queries that can’t be served from VM-2 can now be served from VM-1, until a rebalance takes place, a new instance is chosen for active partition P2, and it restores all the data to become active.
In addition to increasing availability, enabling serving from standbys also offers the benefit of load balancing. If your application is getting abnormally high calls for a particular partition, the standby tasks can reduce the load by serving queries, which has become possible with this KIP.
Serving from a specific partition with KIP-562
The partition information exposed with KIP-535 can be used to fetch data for a key from its specific partition. Unfortunately, the internal implementation of store gets iterated over all the available stores on the instance for all the partitions. This is inefficient and adds considerable latency during each lookup. To improve this flow, we added another improvement, KIP-562, to take in a bunch of store query parameters and allow application developers to write APIs in a way where they can query a specific partition or choose whether or not to query stale stores. The code below shows a snippet using this new KIP:
//find active, standby host list and partition for key final KeyQueryMetadata keyQueryMetadata = kafkaStreams.queryMetadataForKey(TABLE_NAME, key, (topic, “key”, value, numPartitions) -> 0);
//Use the above information to redirect the query to the host containing the partition for the key “key”
//key belongs to this partition final int keyPartition = keyQueryMetadata.getPartition();
//fetch the store for specific partition “keyPartition” where the key belongs and look into stale stores as well final ReadOnlyKeyValueStore<String,String> store = kafkaStreams .store(StoreQueryParameters.fromNameAndType(TABLE_NAME, queryableStoreType).enableStaleStores().withPartition(keyPartition)); String value = store.get(“key”);
Fixing unnecessary restoration of standbys with KAFKA-9169
Imagine that your application rebalances, and after the rebalance, all of the standby tasks restore using the first offset available to them even though they had already restored the data and were hot. This process increases the CPU usage, network, and disk I/O considerably in the cluster and impacts cases where it is unnecessary. For Walmart, the network I/O per standby VM is generally less than 10 MB/s, but due to a bug, it increased to more than 200 MB/s, until the standby was restored completely.
This is one of the critical bugs that KAFKA-9169 fixed in the 2.5 release. Since we have enabled the serving capabilities on standbys, it would be detrimental because standbys can’t serve due to this unnecessary restoration. If you have enabled time retention for the changelog topics, the offsets may not be available, which leads to OffsetOutOfRangeExceptions, and the stores get deleted and recreated again. This bug fix also helps to increase availability in the Kafka Streams cluster by stopping unnecessary restoration in the standby tasks.
Summary
The popularity of ksqlDB (SQL abstraction on Kafka Streams) is a testament to the growing number of use cases based on event streaming databases. Even though it is battle-tested, the future of Kafka Streams and ksqlDB is dependent upon the ability to challenge traditional databases by providing high availability and serving data at low latencies. This will also reduce developer overhead from using different event streaming engines and databases to build a single application. All the improvements discussed above are designed to move us further towards this end goal.
Interested in how queries work in Kafka Streams? Interactive queries are an excellent starting point for serving data with your Kafka Streams application. To see how ksqlDB uses this feature, check out the blog post Highly Available, Fault-Tolerant Pull Queries in ksqlDB and learn more in this podcast.
Disclaimer: The views and opinions expressed in this article are those of the author and do not necessarily reflect the official policy or position of Walmart Inc. Walmart Inc. does not endorse or recommend any commercial products, processes, or services described in this blog.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Stop Treating Your LLM Like a Database
GenAI thrives on real-time contextual data: In a modern system, LLMs should be designed to engage, synthesize, and contribute, rather than to simply serve as queryable data stores.



Generative AI Meets Data Streaming (Part III) – Scaling AI in Real Time: Data Streaming and Event-Driven Architecture
In this final part of the blog series, we bring it all together by exploring data streaming platforms (DSPs), event-driven architecture (EDA), and real-time data processing to scale AI-powered solutions across your organization.