[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Data Privacy, Security, and Compliance for Apache Kafka
Why data privacy for Apache Kafka®?
As companies seek to leverage all forms of data for competitive advantage, there is a growing regulatory and reputational risk that calls for the protection of sensitive data. Through a unified platform for handling real-time data feeds, the distributed event streaming platform Apache Kafka has created a new paradigm for rapid insights into data, but the project has no built-in protocol to de-identify sensitive data in accordance with GDPR, CCPA, HIPAA, PCI DSS, and other similar regulations. Even so, data privacy regulations are as relevant to real-time data as they are to data sitting in traditional data warehouses, batch environments, or cloud storage.
Overview
This blog describes how the Privitar Data Privacy Platform and its integration to Confluent Platform through the Privitar Kafka Connector provides the capability to protect data privacy on streams that contain sensitive data without losing analytical utility. We’ll demonstrate how Privitar augments Kafka’s messaging capabilities with privacy techniques that achieve compliance and without the overhead and limitations of managing scripts or point solutions, all while allowing Confluent’s value-adding tools, such as ksqlDB, work with full referential integrity.
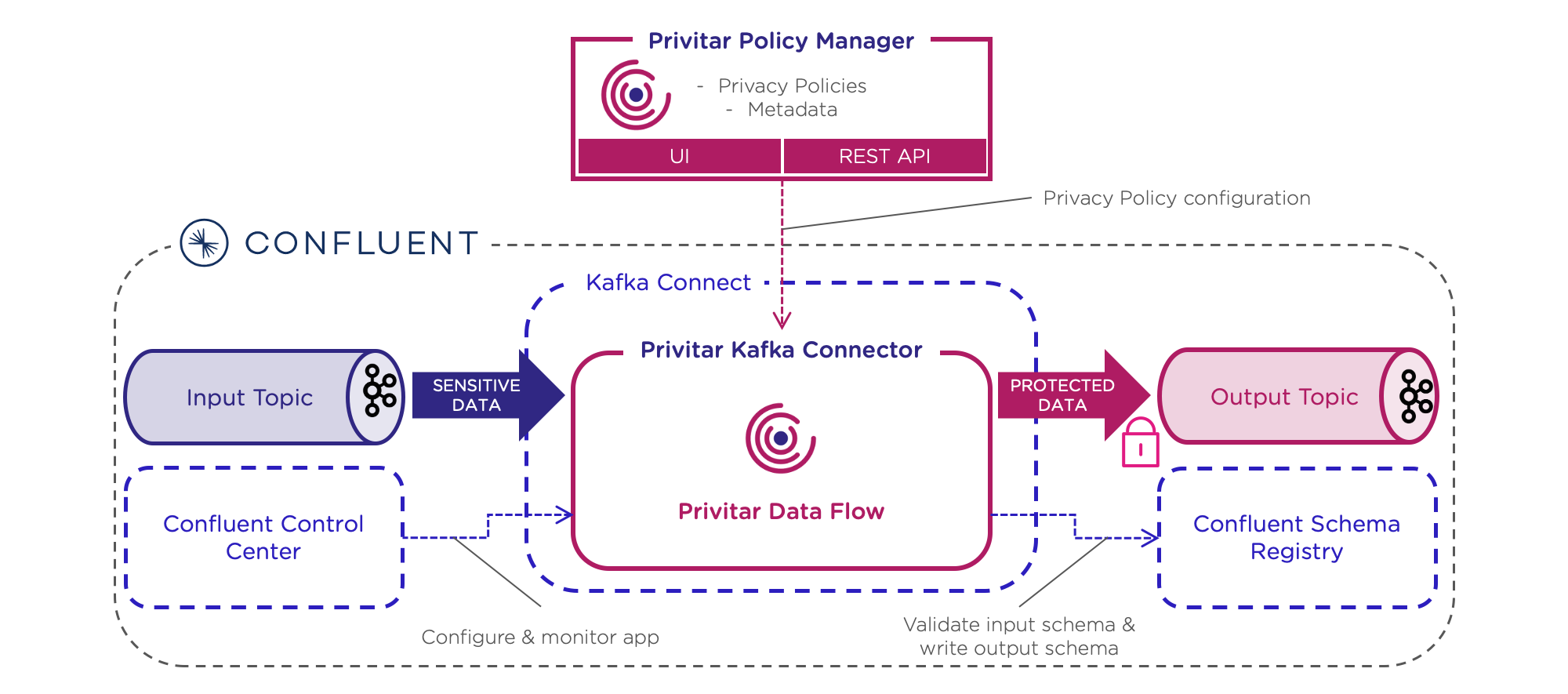
As illustrated above, Privitar uses predefined Privacy Policies to drive the real-time transformation of sensitive data in Kafka Connect into protected data, ready for secondary use. Integration to Confluent Control Center and Confluent Schema Registry allows for further configuration, monitoring, and validation.
The Privitar Policy Manager provides a single access point where a user can define all the privacy rules, audit controls, and other privacy-related management, in a single pane of glass. Privacy Policies define how a particular set of fields within a message schema are de-identified and whether there is any option to re-identify values later. A policy contains a set of rules describing the particular de-identification techniques with their associated parameters to run. The Privitar Policy Manager can be configured using a traditional web UI or automatically with APIs that support integration with data catalogs and Schema Registry tools.
Privacy Policies execute as a Privitar job within an execution engine. In the case of Kafka deployments, the execution engine is the Privitar Kafka Connector, a purpose-built connector, verified by Confluent. When Privitar’s connector receives a message, it matches an associated policy with the message, and the appropriate policy rules are applied to each field before forwarding the message to an output topic.
A de-identification scenario
The following simple scenario illustrates how Privitar can bring data privacy protections to Kafka stream processing: A JSON document is published to the input topic, a Privacy Policy is applied, and an updated JSON document is forwarded to the output topic. A consumer subscribing to the output topic receives privacy-protected messages. The table below illustrates how sensitive data in the input topic is transformed so that the consumer cannot infer the identity of any data subject.
{
"fname": "Daniel",
"lname": "Seydouxr",
"gender": "M",
"id": 1,
"dollars": 234.10
}
|
Policy Rules Retain Original Value Replace with a constant Replace with XXX Tokenize Perturb |
{
"fname":"Daniel",
"lname":"Name Redacted",
"gender":"XXX",
“id":"801".
"dollars":235.30
}
|
The initial message structure, in the left column above, is a simple JSON document with five fields. The middle column contains the list of rules that must be applied, defining the policy. On the right is a sample output message generated as a result of the policy being applied to the initial message.
In the Privitar Policy Manager, a user maps the individual fields to the appropriate rule, as shown in the screenshot below. A rule is applied to each of the fields and the schema is read as a single table structure, named testfile. These rules can be applied for every instance of the schema.
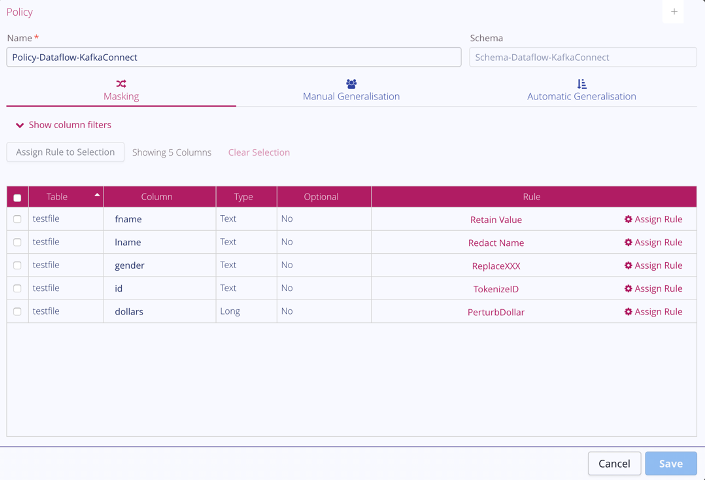
Each rule is individually configurable to allow specific actions. While most shown above are self-explanatory, such as replacing any gender value with the constant XXX, some are more nuanced. An example is the TokenizeID rule, shown below.
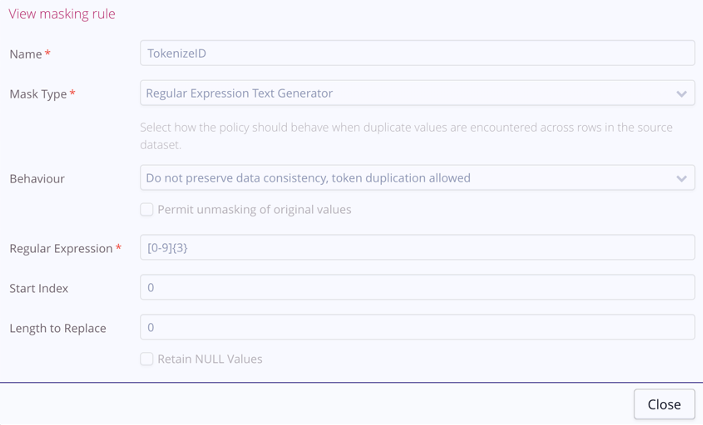
With the TokenizeID rule, a simple regular expression text generator is utilized so that a regex string in the field Regular Expression defines the output characteristics. The specific option selected in the Behaviour field, “Do not preserve data consistency, token duplication allowed,” means that a second message with the same value in the ID field will not necessarily use the same token. In other words, the same token could be used multiple times.
./bin/kafka-avro-console-producer --broker-list localhost:9092 --topic sensitive_data --property value.schema='{"type" : "record","name" : "SensitiveData","fields" : [ {"name" : "fname","type" : [ "string", "null" ]}, {"name" : "lname","type" : [ "string", "null" ]}, {"name" : "gender","type" : [ "string", "null" ]}, {"name" : "id","type" : [ "string", "null" ]}, {"name" : "dollars","type" : [ "long", "null" ]} ]}' < data.txt
Above shows a set of messages publishing to the SensitiveData topic, which is the standard Kafka command. The sample dataset published is shown below. Note that a person named Bob Welshmer has two entries with different dollar amounts, although all other fields remain the same.
{"fname": {"string": "Daniel"}, "lname": {"string": "Seydoux"}, "gender": {"string": "M"}, "id": {"string": "1"}, "dollars": {"long": 234.10}}
{"fname": {"string": "Daniel"}, "lname": {"string": "Seydoux"}, "gender": {"string": "M"}, "id": {"string": "1"},"dollars": {"long": 876.32}}
{"fname": {"string": "Judi"}, "lname": {"string": "Richards"}, "gender": {"string": "F"}, "id": {"string": "3"},"dollars": {"long": 777.87}}
{"fname": {"string": "Kristina"}, "lname": {"string": "Hatcher"}, "gender": {"string": "F"}, "id": {"string": "4"},"dollars": {"long": 997.63}}
As a result of the previously defined policy, the output appears as follows:
{"fname": {"string": "Daniel"}, "lname": {"string": "Name Redacted"}, "gender": {"string": "XXX"}, "id": {"string": "801"}, "dollars": {"long": 235.30}}
{"fname": {"string": "Daniel"}, "lname": {"string": " Name Redacted "}, "gender": {"string": "XXX"}, "id": {"string": "734"},"dollars": {"long": 874.47}}
{"fname": {"string": "Juli"}, "lname": {"string": " Name Redacted "}, "gender": {"string": "XXX"}, "id": {"string": "987"},"dollars": {"long": 780.87}}
{"fname": {"string": "Kristina"}, "lname": {"string": " Name Redacted "}, "gender": {"string": "XXX"}, "id": {"string": "801"},"dollars": {"long": 996.65}}
In the original data, two messages represent two records that are identical except for the dollar amount. Note that the first record has a tokenized ID value of 801 and the second record has a tokenized ID value of 734. The third record also has a tokenized ID value of 801. The main goal has been achieved as it is now impossible to determine the identity of the data subject within each row; the fields have been anonymized. Perturbing the dollar amount means that if an attacker knows a specific dollar amount, they still cannot identify the associated person.
This output allows a user to leverage ksqlDB to determine total counts or other functions without any privacy concerns. When the perturbation rule is defined correctly, no single value within a large dataset remains identifiable, but the resulting dataset remains statistically relevant. Data scientists or analytics tools can still utilize avg, max, min, and other functions.
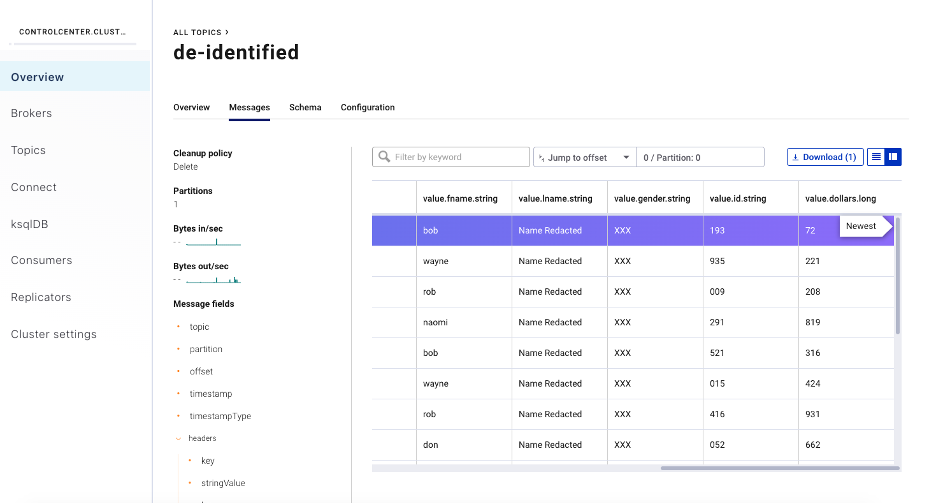
The screenshot below of Confluent Control Center, where rules have been applied on similar messages with the topic de-identified, shows that messages can still be viewed using the standard tools.
Data consistency and re-identification
The Privitar Platform supports the optional capability to re-identify data that was previously de-identified in a controlled manner so that legitimate action can be taken. Re-identification involves applying a job to a tokenized ID value to return its original value. This would be important for a data scientist trying to perform a count per ID or other statistical groupings, but it’s also critical in use cases like customer 360 where the business needs to act on analysis. Data consistency is necessary to re-identify a token, so re-identification requires a different tokenization strategy to that outlined in the previous section.
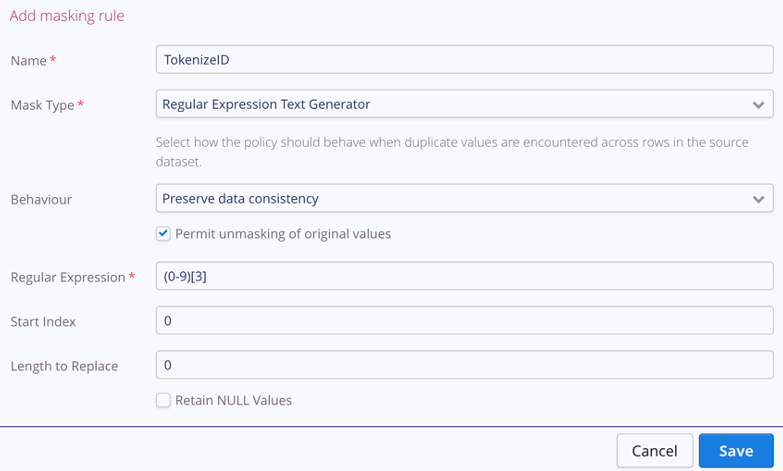
The screenshot above shows how the TokenizeID rule can be configured within the Privitar Policy Manager to allow consistent tokenization of the ID field, either within the Kafka topic or in a target data platform, if preferred. The option selected in the Behaviour field, “Preserve data consistency,” ensures that every time a specific ID is encountered in the source messages, it will always map to the same token (e.g., 1 maps to 801). By selecting “Permit unmasking of original values,” it’s possible for an authorized user to re-identify values (e.g., 801 to 1). Re-identification actions are privileged and audited within the Privitar Platform to deter malicious user behaviour and ensure compliance through traceability.
Publishing the original messages through the updated TokenizeID rule ensures that the first two source messages, with the ID of 1, are consistently mapped to the tokenized ID value of 801, as shown in the dataset below. Equally important, the fourth message cannot share the value 801 and instead has the distinct value of 934. This enables a user to perform count or sum operations on messages with the same ID token.
{"fname": {"string": "Daniel"}, "lname": {"string": "Name Redacted"}, "gender": {"string": "XXX"}, "id": {"string": "801"}, "dollars": {"long": 235.30}}
{"fname": {"string": "Daniel"}, "lname": {"string": " Name Redacted "}, "gender": {"string": "XXX"}, "id": {"string": "801"},"dollars": {"long": 874.47}}
{"fname": {"string": "Juli"}, "lname": {"string": " Name Redacted "}, "gender": {"string": "XXX"}, "id": {"string": "987"},"dollars": {"long": 780.87}}
{"fname": {"string": "Kristina"}, "lname": {"string": " Name Redacted "}, "gender": {"string": "XXX"}, "id": {"string": "934"},"dollars": {"long": 996.65}}
Deployment and setup
The Privitar Kafka Connector requires some basic configuration in order to be in a position to apply a specific Privacy Policy to messages and create their de-identified versions. To set up an instance of the connector, the following attributes need to be configured:
- Privitar hosts: The connector needs to connect to the Privitar Policy Manager to download the relevant Privitar job definition
- Privitar user credentials: The connector will log into Privitar Policy Manager, with specific privileges
- Privitar job ID: Each component in Privitar has a unique, system-generated identifier, including the job; this unique job ID is used to pick the appropriate job definition, which is shown below with the ID 2v2fqpfe
- Inbound/outbound topic: This refers to the name of a topic that will receive clear messages and that de-identified messages will be published to
With this information, administrators are able to apply policies to any Kafka topic and message structure. For smaller deployments, the standard UI can be used. For larger deployments spanning multiple geographies, clusters, and organizational silos, it’s possible to automate deployment through an extensive set of APIs.

Next steps
The Privitar Data Privacy Platform is a comprehensive data privacy solution that fully integrates with Confluent Platform through the Privitar Kafka Connector, enabling any organization to define, control, and audit data privacy as they utilize Apache Kafka. Privitar users gain the ability to implement appropriate levels of automation and human control to deploy policies to Kafka, and provide the audit and traceability necessary to show regulatory compliance.
From a central point, Privacy Policies can be deployed in any part of the organization to intercept messages, ensure they conform to both corporate standards and local privacy regulations, and provide the data utility needed to extract valuable insights.
The Privitar Kafka Connector is listed on the Confluent Hub and available to organizations with a license for the Privitar Data Privacy Platform.
You can learn more about the business benefits of data privacy and the Privitar Kafka Connector in this solution brief or by visiting Privitar’s webpage.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


