[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
How to Make Apache Kafka Clients Go Fast(er) on Confluent Cloud
Imagine your team wants to design a data streaming architecture and you’re in charge of creating the prototype. Within a few minutes, you provision a fully managed Apache Kafka® cluster on Confluent Cloud and run connectors that stream data from different event sources and database tables into the cluster. Then you focus on writing an application to process that data, cleanse and denormalize it, and apply your business logic to it. You show your prototype to your team, how they can discover data through the Streams Catalog, browse record schemas, and trace flows in the lineage graphs. Your team says, “Wow, that was incredible turnaround time!”
You continue on and show them the dashboards and the production and consumption metrics, and they ask, “Can it go even faster?”
But…what does “fast” mean in the first place? In some architectures, “fast” means low latency, which is the elapsed time moving records end to end, e.g., from producers to brokers to consumers. One scenario for low latency is a financial transaction where account balances should reflect debits and credits with as little delay as possible. In other architectures, “fast” means high throughput, which is the rate that data is moved, e.g., from producers to brokers or from brokers to consumers. One scenario for high throughput is an e-commerce site processing millions of events per second.
While latency and throughput do vary with workload, chances are your streams of real-time transactions or telemetry data or customer event information, or whatever, are already performing plenty fast. This is because you can achieve a good balance between low latency and high throughput. With regard to latency, Kafka brokers and the client application default parameter values are already optimized to deliver low latency, and regardless, network latency usually has the bigger latency impact. As for throughput, Confluent Cloud Basic and Standard clusters elastically scale from zero up to 100MBps, and 8.6TB per day is substantial throughput, especially considering that the average message size is small, about 1KB.
Over the years, incredible technical content has been written about data plane performance, general principles and tradeoffs, cloud-native architectures, etc. These writings describe how you can get low latency and high throughput without compromising on a mature and reliable platform that provides persistence, no data loss, audit logs, processing logs, and more—all the things that enable you to go from proof of concept to production. This blog post highlights the top five reading recommendations to help you gain a deeper understanding of what makes applications that run on Confluent Cloud so fast. They cover the key concepts and provide concrete examples of how we do it, and how you can do it too, with specific benchmark testing and configuration guidelines.
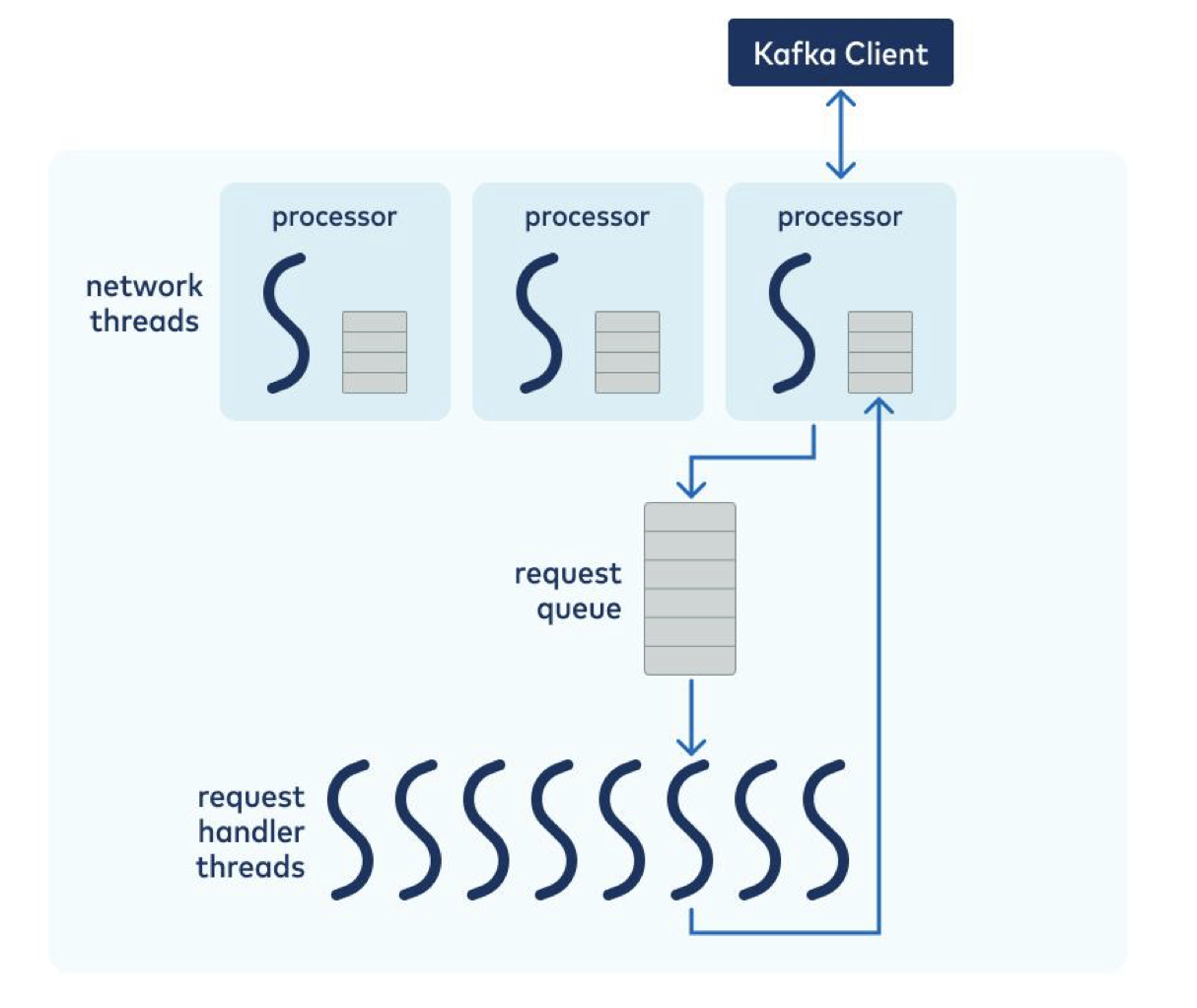
1. Cloud Native Chasm: Lessons Learned from Reinventing Apache Kafka a Cloud-Native, Online Service
This whitepaper talks about key principles that go into a cloud-native design. It’s a very thorough whitepaper, but some of the design considerations discussed that impact performance include:
- Sufficient broker CPU capacity to process client requests
- Dual-tier architecture that enables latency-sensitive apps to safely reside on the same Kafka cluster as applications that read historical data
- Message characteristics that may affect throughput and latency
- Lowering the tail latency of producer workloads with high-IOPS disks
- Topic-partition distribution for different workload distributions
- Achieving higher read and write throughput from underlying storage hardware by tuning the operating system
Related resources:
- Blog series Speed, Scale, Storage: Our Journey from Apache Kafka to Performance in Confluent Cloud
- Podcast Optimizing Cloud-Native Apache Kafka Performance ft. Alok Nikhil and Adithya Chandra
2. Recommendations for Developers using Confluent Cloud
This whitepaper describes how to optimize your Kafka client applications for low latency or high throughput and how to monitor your application performance, consumer lag, and throttling, using JMX and the Metrics API. It discusses best practices for setting producer configuration parameters such as:
batch.size linger.ms compression.type acks buffer.memory enable.idempotence max.in.flight.requests.per.connection session.timeout.ms
And setting consumer configuration parameters such as:
fetch.min.bytes enable.auto.commit isolation.level
3. Benchmark Your Dedicated Apache Kafka® Cluster on Confluent Cloud
This whitepaper presents benchmarks that Confluent ran on a 2-CKU multi-zone Dedicated cluster, and shows the ability of a CKU (Confluent Unit for Apache Kafka®) to deliver the stated client bandwidth. The paper describes the setup up and execution of the benchmarks in sufficient detail, which may be useful if you want to apply the benchmarking framework to your own scenarios. It’s important to test in your production cloud environment so that the benchmarks reflect realistic cloud network performance.
- Setting up benchmark clients
- Running benchmarks: tests and sample output, using the off-the-shelf Kafka producer and consumer performance tools, kafka-producer-perf- test and kafka-consumer-perf-test
- Performance troubleshooting tips
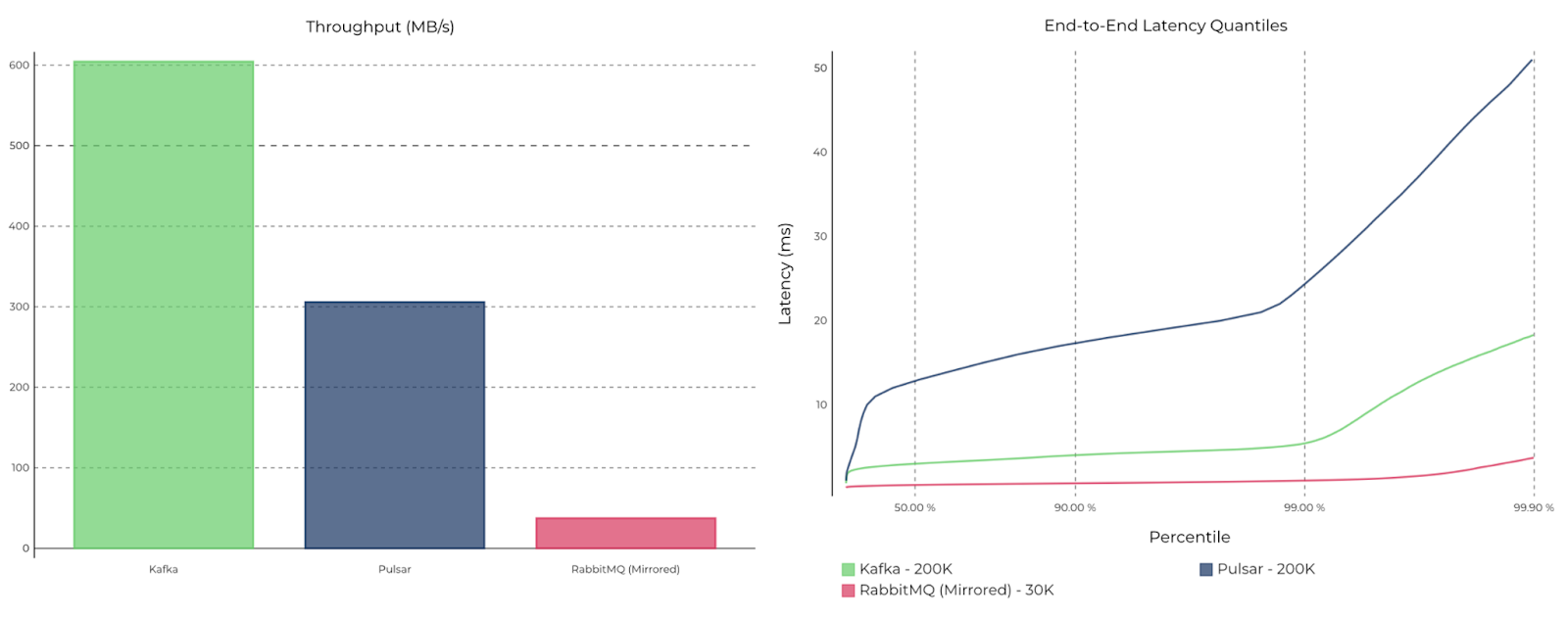
4. Benchmarking Apache Kafka, Apache Pulsar, and RabbitMQ: Which is the Fastest?
This blog post shows how Kafka-based architectures deliver high throughput while providing the lowest end-to-end latencies up to the p99.9th percentile. It goes into technical detail on:
- Consistency and durability guarantees in distributed systems
- Benchmarking framework and drivers
- Testbed environment, disk sizing, OS tuning, and memory configuration
- Throughput test and results
- Latency test and results
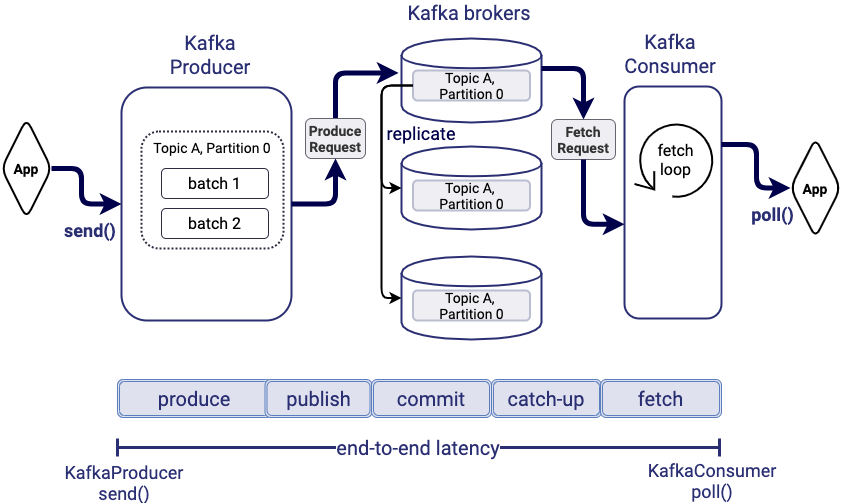
5. 99th Percentile Latency at Scale with Apache Kafka
This blog post explains end-to-end latency, and how to configure and scale your application for throughput while keeping bounds on latency. It goes into more technical detail on the inner workings of Kafka and the various factors that impact latency. Some of the key callouts include:
- More partitions may increase latencies because of the potential for less batching and more overhead
- Optimizing for durability may add replication overhead to latency and replication load to the brokers
- Designing your application such that each producer writes messages to a subset of partitions improves batching without increasing artificial delays
- The impact of the number of clients on tail latency, since more clients increase the number of produce and fetch requests
- Compression configuration may reduce overall end-to-end latency because it can significantly reduce the amount of bandwidth and per-broker load required to process your data
Time to market
There is one more perspective to going “fast”. Thus far we’ve talked about it in terms of data plane latency and throughput, but some people think of “fast” in terms of project time. There is the time to build a prototype, to extract and load data, to test the applications end-to-end, to integrate with operational tools for security, monitoring, and billing, to deploy the solution, and the whole ecosystem of things that achieve the business outcome. Overall this project time is called time to market and everyone wants that to be very fast!
When you’re developing the prototype, you want to focus on developing a client application that consumes that data and apply your own cool business logic. What you don’t want to do is take on additional operational burden, and Confluent takes care of that: Load is automatically distributed across Kafka brokers, partition leadership is automatically reassigned upon broker failure, consumer groups automatically rebalance when a consumer is added or removed, the state stores used by ksqlDB and applications using the Kafka Streams APIs are automatically backed to the cluster. There isn’t a document to point you to that would speak better than just telling you to try it out for yourself.
The fact that you can spin up a prototype quickly on Confluent Cloud, focus on your application, then work with your broader team to integrate it into your business toolchain and go live, enables your business to recognize new opportunities or revenue streams faster. You want something that allows developers to be highly productive and has reduced operational complexity so that it’s faster to deploy to production.
Summary
An event streaming architecture built on Confluent Cloud gives good performance on a mature and reliable platform that elastically scales to fit your business requirements. For more details on achieving low latency and high throughput, here is the summarized list of the five key resources for learning about how to make Kafka go fast(er) on Confluent Cloud:
- Cloud Native Chasm: Lessons Learned from Reinventing Apache Kafka a Cloud-Native, Online Service
- Recommendations for Developers using Confluent Cloud
- Benchmark Your Dedicated Apache Kafka® Cluster on Confluent Cloud
- Benchmarking Apache Kafka, Apache Pulsar, and RabbitMQ: Which is the Fastest?
- 99th Percentile Latency at Scale with Apache Kafka
When performance matters, you should always benchmark in your particular Confluent Cloud environment and with the expected production workloads. Refer to the resources above for guidance on how to configure your Kafka applications and do the testing. If you have any questions along the way, please ask us in the Confluent Forum! If you’re ready to get started with a free trial of Confluent Cloud, use the code CL60BLOG to get an additional $60 of free usage.*
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


