It’s Here! Confluent’s 2026 Data + AI Predictions Report | Download Now
Event Sourcing Outgrows the Database
I’ve always found event sourcing to be fascinating. We spend so much of our lives as developers saving data in database tables—doing this in a completely different way seems almost unfathomable. Yet that is what event sourcing is. It has clear benefits, but there are many lurking questions.
To begin with, you need to determine whether event sourcing is a good fit for the problem you are trying to solve. Deciding whether to use event sourcing or a CRUD-based data solution for your system is similar to deciding whether to use the Cartesian or polar coordinate system for a math problem: Either can be used for the problem, but some problems are better suited to one coordinate system than the other (for example, the motion of the planets around the sun is ideally addressed with polar coordinates).
Once you decide to use event sourcing for your problem, you will need to start reasoning about how to apply it conceptually within your architecture, as I discussed in a previous Kafka Summit talk. The traditional way to implement event sourcing is with a simple relational database, but the more powerful and modern approaches combine data in motion with services-based architectures. Let’s start by introducing the traditional approach and work forwards from there.
Traditional event sourcing (c. early 2000s)
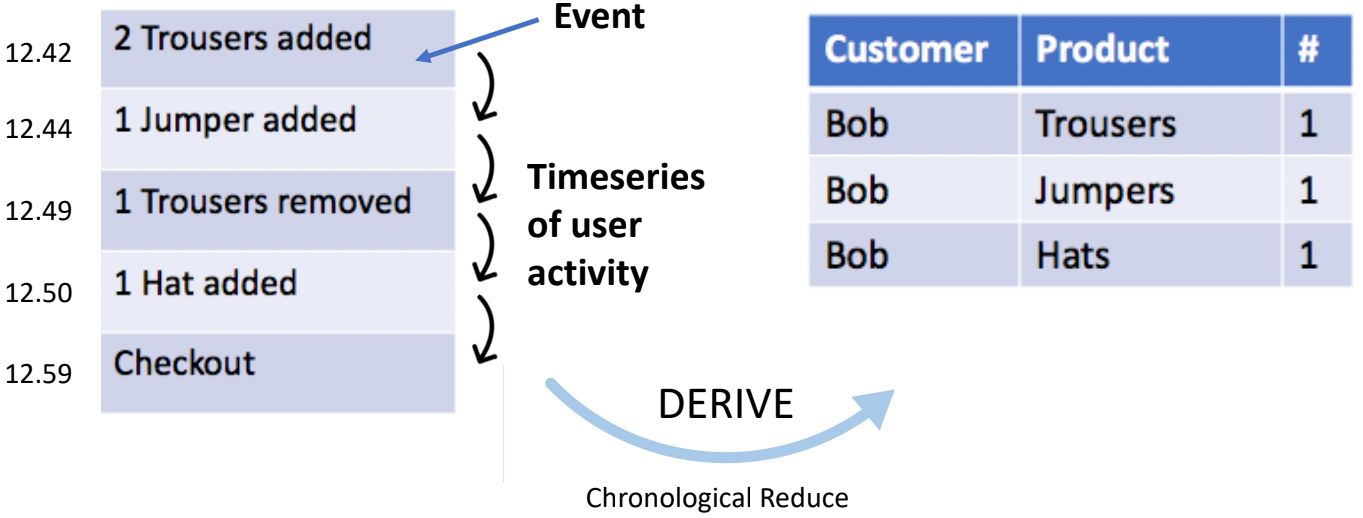
To better understand event sourcing in its traditional sense, you can start by considering it in relation to normal CRUD processes, such as might be used with an e-commerce shopping cart. Say you add three pairs of trousers to a cart, later change your mind and remove two, and then proceed to checkout with only one pair. In a CRUD model, just the end result gets stored in the database, so the fact that you ordered only one pair of trousers would be recorded, and that’s it. But in the event sourcing model, each action you took during the process gets stored, that is, the first action of adding three pairs of trousers, the second action of removing two pairs, and the final checking-out action of buying a single pair. You are effectively collecting a time series of user activity—a journal of the system itself.
You can perform event sourcing with practically any database. Basically, you create a table and append events in the order that they occur. Eventually you query the events, most likely aggregated by customer ID or session ID, and then you perform a “chronological reduce” to filter the events that are relevant for the view you’d like to serve.
Source: Event Sourcing, Stream Processing, and Serverless
The advantages of sourcing events are threefold. First, there are the evidentiary advantages—“accountants don’t use erasers.” Event sourcing creates a version-control-like audit of your system that allows you to determine, for example, why things went wrong at a particular point in time. This leads to the second advantage: “replayability.” If you have data that was corrupted by a bug, for example, one that may have affected systems across your application, you can rewind back to a point before the bug surfaced. The final advantage of collecting so much data is so you can feed it into analytics systems, whether for machine learning or for other types of analysis. To return to the shopping cart concept, because the cart gives us a very truthful record of user behaviour, we could start to try and work out why people aren’t buying that much in our shop at a particular time or within a given category.
So traditional event sourcing and its benefits are relatively straightforward, but can more sophisticated architectures—ones that need to massively scale and stream using a tool like Apache Kafka®—also enjoy its benefits?
Event sourcing with Kafka and CQRS
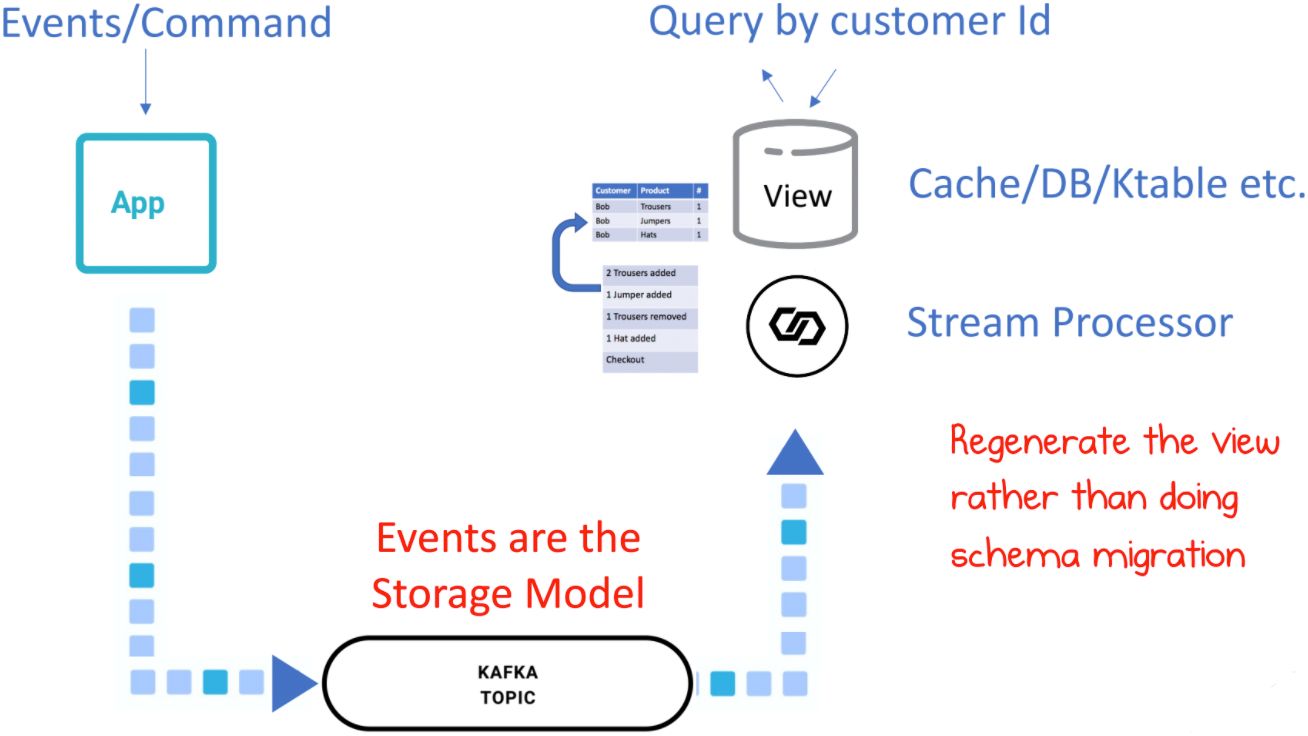
When you begin to reason about event sourcing using a stream processor like Kafka, it’s clear enough that the chronological events go into the log. But when you get to querying, things become a bit weird: How can you perform the necessary event queries in Kafka, given its lack of an internal query API? (This is actually a common question around the internet, one that has inspired many blog posts.)
The tonic is CQRS (command query responsibility segregation), a form of event sourcing that separates the parts of a system that perform “commands” (change state) from those that “query” (return values). Another significant aspect of CQRS is that chronological reductions are done immediately at write time, so views are updated asynchronously before they are served.
Source: Event Sourcing, Stream Processing, and Serverless
So Kafka holds the state but it gets pushed into a stream processor API (generally ksqlDB), where materialized views that suit specific use cases are created. Events are still very much the storage model, and the views can be regenerated anytime from the underlying events.
Even with CQRS, event sourcing is hard
In a CRUD system, there is often just an app and database, but with CQRS there are more moving parts: an app, a Kafka topic, and a view—in even its simplest form. There is no schema migration, so as the schemas of events evolve over time, lots of different ones end up inside the log. And the complexity goes up with the number of schemas, because different parsing code is needed for each. Finally, a key factor of CQRS is that it is only eventually consistent, meaning you can’t necessarily read your own writes.
So there’s a little bit of extra complexity with CQRS, but the model works well for many different kinds of use cases.
For example, The New York Times stores every single edit, image, article, and byline from the newspaper since it started in 1851 in a single Kafka topic. The raw data is stored as events, which services then convert into views to be delivered on the website. The CMS, where the content originates, doesn’t actually need to be immediately consistent with the serving layer. If a different view is needed, the log is rewound, and a new view is created by replaying it.
When you still need CRUD
As an aside, if CRUD makes sense for your application, there are ways to get some of the benefits of event sourcing with it. You can use old-school triggers, or you can change-data-capture (CDC) your data out, a good option if you want to get it into Kafka later. You’ll get some of the beneficial event sourcing properties with these options, but not all of them—it will still be evidentiary and you can do analytics, but you won’t get replayability (if you have a web app, this may not matter). Another option you can experiment with is bitemporal databases, a generally undervalued class of database.
CQRS comes into its own with data in motion
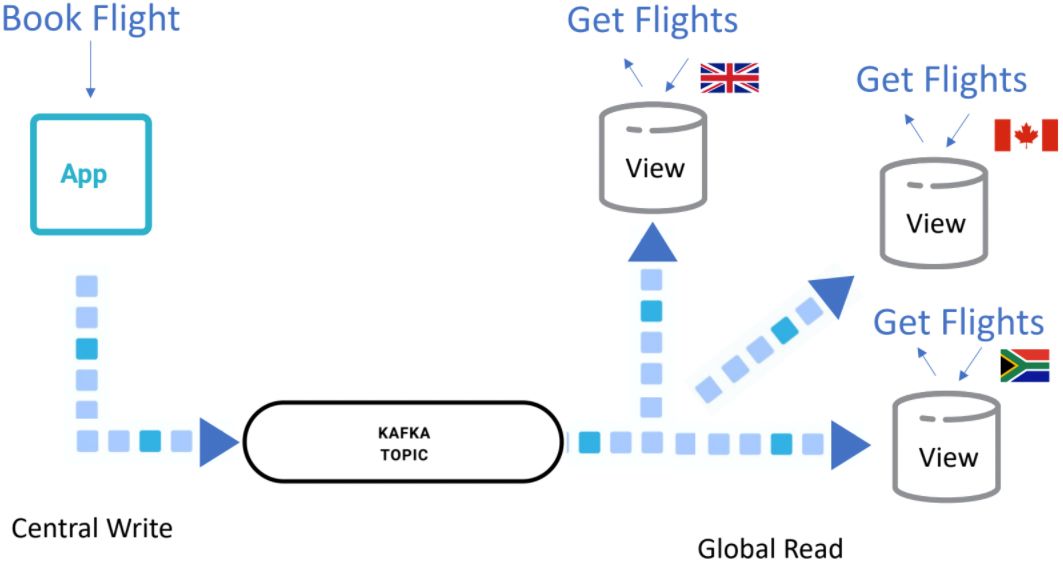
A monolithic application benefits from events, but they really become significant when data has to move—when there are different parts of an application that need to cooperate with one another and share data, potentially on a global scale.
An example is a flight booking system, which may have 10,000 times more reads than writes and is global. You could try and set up the system with a globally distributed database, but that’s not necessarily the most efficient way, because reads themselves will always be eventually consistent whether the data is served from a globally consistent database or not—because of browser caching and other factors. What is most important is that when you book a flight, you definitely get your reservation. So it makes sense to split up reads and writes and have writes go to a consistent place, but have reads go to a place that is eventually consistent.
Source: Event Sourcing, Stream Processing, and Serverless
Where event streaming fits in
Event streaming supersets event sourcing and CQRS. Its events use a shared data model, meaning that numerous services have access to them. And it doesn’t just create views, it sews together data from different sources in real time.
It also features polyglot persistence, which means that each service chooses where and how to store data. This opens up the possibility of event-driven processing, whereby events trigger other actions—really the core of event streaming.
In summary, event sourcing with a database is clearly a very good pattern: It works well for monoliths and has been around for a long time. CQRS is an improvement, but event streaming with both elements is the best option for architectures with microservices that need to scale and share data across many services.
If you’re keen on finding out more on this subject or trying event sourcing out in your favourite programming language, have a look at the free video course Event Sourcing and Event Storage with Apache Kafka to learn more.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Data Streaming Platforms: The Cornerstone of Enterprise AI
Discover how a data streaming platform helps you unlock the full potential of your AI—and translates it into measurable business value.



Developer Experience in the Age of AI: Developing a Copilot Chat Extension for Data Streaming Engineers
AI is bringing changes in developer experience… we shared what we learned in this article about creating our new GitHub Copilot chat extension for data streaming engineers.