[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Unlock Real-Time Value from DynamoDB Data with Confluent's CDC Source Connector
Over the years, Amazon DynamoDB has grown into a feature-rich NoSQL database that has deep integrations with various services such as Amazon S3 and AWS Lambda. As businesses increasingly depend on data for decision-making, it is common to use data residing in DynamoDB to contextualize or even drive events at a granular level (as opposed to bulk or batch). By leveraging DynamoDB alongside Confluent’s data streaming platform businesses are able to build event-driven architectures for real-time insights and decision-making.
In a previous blog post we discussed three different ways to capture and transfer data changes from Amazon DynamoDB to Confluent’s data streaming platform. While each approach has its merits, they come with different degrees of complexity. The options include writing and maintaining code with AWS Lambda for data transfer, using the Kinesis Data Streams connector which introduces several intermediate steps, or deploying the open source DynamoDB source connector, which involves self-managing infrastructure and the risk of running it in production without support.
In this blog post, we explore a fourth, simpler option: Confluent Cloud’s source connector for Amazon DynamoDB Change Data Capture (CDC). This source connector is designed to streamline integration between the two platforms, making it easier to capture and transfer data changes from DynamoDB to Confluent.
Introducing Confluent Cloud’s source connector for Amazon DynamoDB CDC data
Confluent Cloud’s source connector for Amazon DynamoDB CDC is a fully managed service that simplifies the process of capturing and transferring data changes from one or more DynamoDB tables to Confluent topics. It eliminates the need for extensive infrastructure management, reduces operational complexity, and provides a seamless integration experience that ultimately allows developers and organizations to focus on more differentiated activities.
Benefits of Confluent Cloud source connector and DynamoDB CDC
No-code integration with Confluent. This connector is fully managed meaning Confluent handles the infrastructure and software management, relieving customers of the heavy lifting associated with running the connector. Instead, data sourcing from DynamoDB is simplified to filling out a simple form. As a result, you can focus on building impactful applications and onboarding meaningful use cases for your business.
Cost-effective streaming with multi-table support: A single connector can capture and replicate data from multiple DynamoDB tables to Confluent Cloud. The connector charges are based on task hours and data processing. By utilizing the same task to stream data from multiple tables, the connector helps reduce costs by eliminating the need for additional tasks.
Multi-purpose usage: The connector can be used in three different modes, depending on your use case. The first mode is SNAPSHOT, which allows a one-time scan of the existing data in the source tables simultaneously. This is useful for one-off cross-account migration of DynamoDB, similar to other traditional methods supported by DynamoDB. The second mode is CDC, which captures change events using DynamoDB streams without an initial snapshot. Finally, there is SNAPSHOT_CDC (Default), which starts with an initial snapshot of all configured tables. Once the snapshot is complete, it automatically continues with CDC streaming using DynamoDB streams, making it ideal for ongoing replication between different DynamoDB tables.
Enhances developer productivity: The connector supports two modes to provide seamless table streaming. In TAG_MODE, the connector automatically discovers multiple DynamoDB tables based on tags and streams them simultaneously (set dynamodb.table.discovery.mode to TAG). TAG_MODE significantly reduces development time because any new table following the TAG convention will automatically be monitored by the connector without any additional effort. In INCLUDELIST_MODE, you can explicitly specify and select multiple DynamoDB table names to stream simultaneously (set dynamodb.table.discovery.mode to INCLUDELIST).
Custom offset support: While set to the CDC mode, the connector allows you to start streaming data from the specified point in time with the
dynamodb.cdc.initial.stream.positionsetting. This allows you to specify whether the connector should start from the oldest available data record (TRIM_HORIZON), start after the most recent data record/fetch new data (LATEST), or start from the record at or after the specified server-side timestamp (AT_TIMESTAMP). For further control of your streams, you can change these offsets for each DynamoDB stream individually, making it especially helpful in preventing data loss and data duplication.IAM AssumeRole support: The connector supports assuming an AWS IAM role meaning your data and AWS resources have enhanced protection because the connector will only have on-demand, temporary access to your DynamoDB tables. This removes the need for long-term access keys that need to be rotated frequently and have the potential to be leaked.
Example of change data capture events
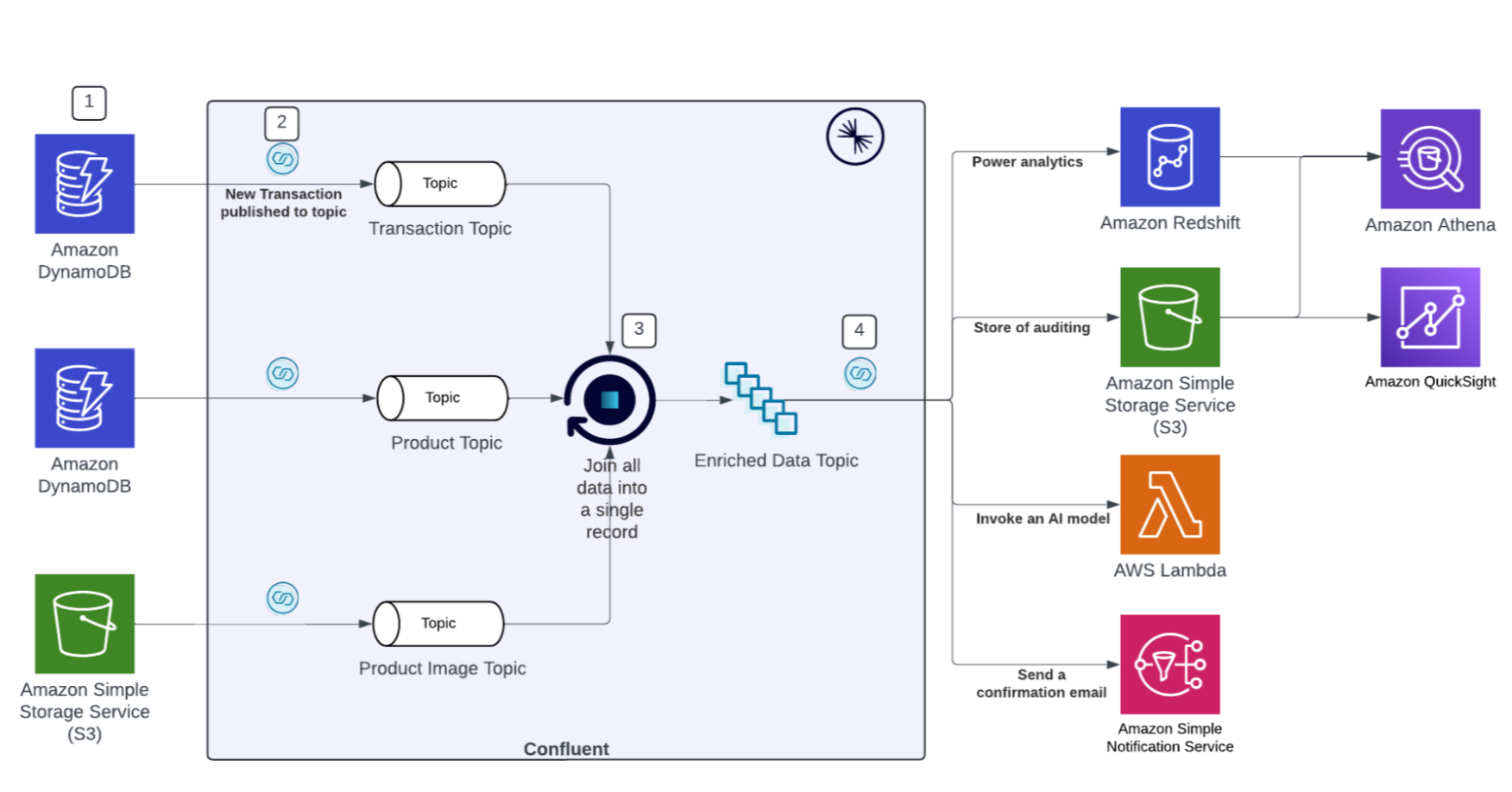
To best illustrate each of the benefits in action, let’s use the flow of events during an online purchase. By using the Confluent Cloud source connector for Amazon DynamoDB CDC transaction changes to the table become triggers for downstream processing and power real-time analytics and enriched customer insights.
A customer makes a purchase. The transaction is recorded in the Transaction table in DynamoDB.
The DynamoDB source connector picks up on the new record and publishes the new record to the transaction topic in Confluent.
Confluent Cloud’s managed offering for Apache Flink® aggregates data from the transaction topic with data that has been sourced from other sources such as an S3 bucket and a different DynamoDB table. This allows the event to be enriched with meaningful, contextual information.
Data is then sent to multiple downstream applications such as the AWS Lambda function that uses Amazon Bedrock to invoke a model, Amazon SNS to send a confirmation email to the buyer, and Amazon Redshift for customer 360 analytics.
What would’ve taken months (~6 months alone per connector per direction, not including standing up the Apache Kafka® clusters themselves) has been greatly reduced to a few minutes. Furthermore, this customer can continue to add more downstream systems to consume off of the enriched data topic or can even add a completely new use case with relatively lesser effort.
Putting the connector to the test
Now that we have covered an example use case of the connector, let’s put the connector to the test.
Prerequisites
Confluent Cloud environment and cluster
DynamoDB Table with data populated
Steps
This example re-creates the source connector portion of the above architecture. As such, below is an example transaction table that we’ve created.
After creating the table and populating it, the next step is to enable DynamoDB streams using the “Export and Streams” tab of the table.
You can select whichever view type works for you, but this example uses the new image.
Last, for this example, we want to tag this DynamoDB table. Simply navigate to the “Additional Settings” tab of the DynamoDB table and add the tag you see below. This will be used later for when we set up the connector to discover DynamoDB tables based on tags.
With the DynamoDB table now set up, we can navigate to Confluent Cloud and create the source connector. In the cluster you want your DynamoDB data, navigate to Connectors and search “DynamoDB CDC Source.”
The following images show the configurations we used. For Discovery mode, we will use the TAG setting. This searches all DynamoDB tables that match what you input into the TAG FILTER field. If your DynamoDB table is not in us-east-1, please refer to the AWS Tag Endpoint documentation and the DynamoDB endpoint documentation to find the proper API endpoints that match the region in which your table resides.
After you set the sizing to one task, you can review and launch your connector. After a short time, your source connector should change to “Running.” At this point, you can navigate to the Topics tab of your cluster and see that the connector created a topic that corresponds to your DynamoDB table (or tables if you chose to select or include multiple tables).
Since we chose SNAPSHOT_CDC, we can verify that the data already existing in DynamoDB has been imported by looking at the messages of the topic. To further experiment, assuming you have selected SNAPSHOT_CDC or CDC for the DynamoDB Table Sync Mode during the connector setup, you can create a new item in your table and see the new record populate in the topic.
Conclusion
By leveraging Confluent Cloud’s Amazon DynamoDB CDC source connector businesses gain various advantages that range from hydrating data lakes to facilitating real-time data processing. Pairing CDC with Confluent not only expands the range of data sources that can be used to enrich DynamoDB data, but also broadens the potential destinations to which the data can be sent. The approach is cost-effective both in terms of time (talent and development) as well as infrastructure (upfront and maintenance), saving organizations at a minimum six months’ time. This means those same organizations will be more agile and flexible in changing or implementing new use cases as developer productivity allows for efforts to be focused on more differentiated activities.
This feature is available across all major clouds, so to get started, visit the connector documentation. If you’re using AWS, you can also deploy the connector directly from the AWS Marketplace.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



How to Source Data From Amazon DynamoDB to Confluent
Amazon DynamoDB is a fully managed, serverless, key-value NoSQL database service that is highly available and scalable. It is designed to deliver single-digit millisecond query performance at any scale. It offers a fast and flexible way to store...

{kind=link}

New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.