[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Real-Time Database Streaming with Confluent and Amazon Aurora
Hello there, we are glad you are here with us in this blog post today. We will be taking a journey by using Confluent technology to efficiently migrate data from on-premise to Amazon Aurora. This pattern will not only allow you to work with your relational data in near-real time, you will also be able to take advantage of the low operational overhead of both Confluent Cloud and Amazon Aurora. We are going to make a few assumptions, first is that you have already bought into the idea of tying your relational database into Confluent Cloud using our connectors. If you have not, check out these links: Confluent and Relational Database landing page, Confluent Database Modernization blog post, and last but not least, a demonstration. Our second assumption is that you no longer wish to manage your relational database, either running on prem or in the cloud. Legacy databases, like Oracle, MySQL, SQL Server, etc. were designed for static, on premises installations and not purpose built for the cloud. In turn, creating limiting factors for the speed at which businesses can make decisions, how quickly they can innovate in today’s dynamic digital first environment, and frankly ruin DevOps engineer’s weekends.
Speaking of on-premises, I remember the days of running MySQL or PostgreSQL clusters on hardware that was nearing end of support or tied to SANs that were nearing capacity which makes me think of a line I heard before but resonates to this day. “The only thing worse than developing software you can buy is running a system someone else will run for you.” Today’s organizations need a modern, cloud-native database strategy that includes streaming data piplines and integration to enrich operations to be increasingly agile, elastic, and cost efficient, at speed as they develop cloud applications. Confluent helps companies accelerate their modernization initiatives with our fully managed data streaming platform that lowers costs and synchronizes data during their on-prem to cloud migration to get the full value of existing infrastructure and new investments.
In this blog, we will explore using Confluent Cloud as a mechanism to not only build real-time applications using legacy or existing data sources but also as a means to migrate to a fully managed cloud database like Amazon Aurora. By moving to real-time streaming and pulling data from any environment across cloud and on-prem, organizations can provide application teams with the data they need faster and deliver new features and capabilities to customers at scale. Let’s talk about Amazon Aurora which was purpose built for running relational databases in the cloud.
Amazon Aurora is a cloud-native modern relational database service, offering performance and high availability at scale, fully open source MySQL- and PostgreSQL-compatible editions, and a range of developer tools for building serverless and machine learning (ML)-driven applications.
Aurora features a distributed, fault-tolerant, and self-healing storage system that is decoupled from compute resources and auto-scales up to 128 TB per database instance. It delivers high performance and availability with up to 15 low-latency read replicas, point-in-time recovery, continuous backup to Amazon Simple Storage Service (Amazon S3), and replication across three Availability Zones (AZs).
Amazon Aurora is also a fully managed service that automates time-consuming administration tasks like hardware provisioning, database setup, patching, and backups while providing the security, availability, and reliability of commercial databases at 1/10th the cost.
For the migration let’s start with this first diagram which includes your legacy relational database being sourced by Confluent Cloud. You might be pulling in customers data or transactions, who knows, but you have already considered and hopefully implemented something similar to what we see below:
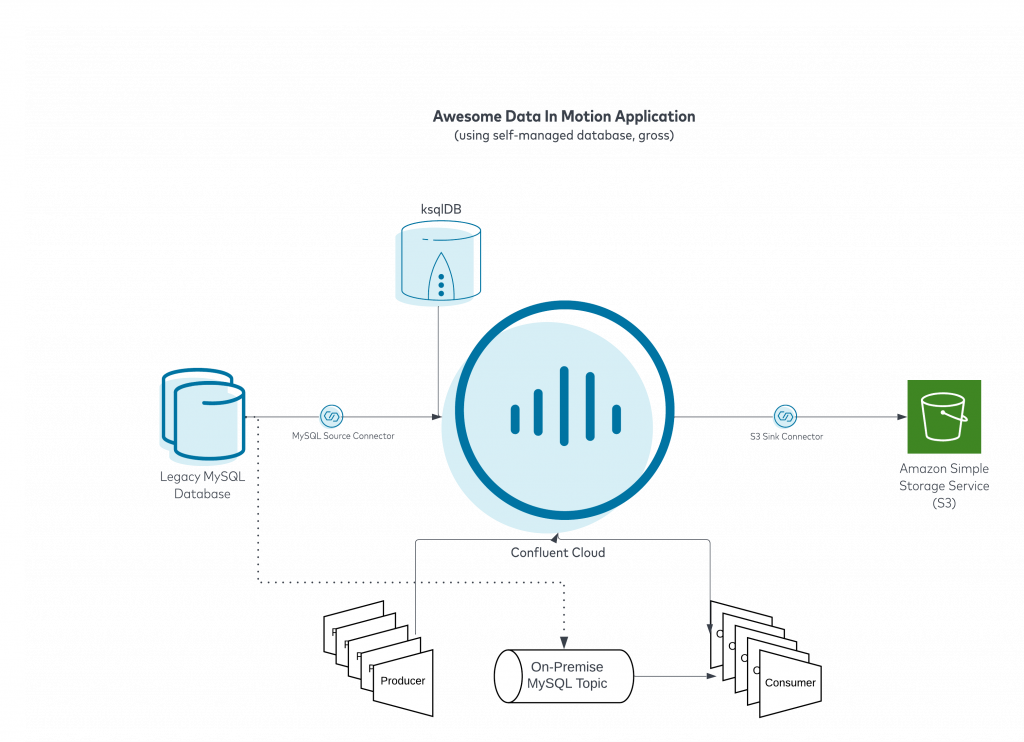
Get more data to and from your DB by connecting to any app or data source.
In the above, we source data from our database that is being used in conjunction with incoming data from our producers. We merge data from the database and the incoming producer events using ksqlDB. We have consumers reading and acting on these events in real time. There is also an S3 sink setup to dump all of our events for long term storage and use in our data lake. The above is working hunky dory, however, the Legacy MySQL Database is running on hardware that is nearing the end of support. Frankly, the person that set up all of this left years ago and you consider this “tech debt”. Let’s take a look at a quick enhancement we can make. First, we will need to spin up Amazon Aurora in AWS. Then we will set up a fully-managed Confluent MySQL sink to send the sourced MySQL data into Aurora like below:
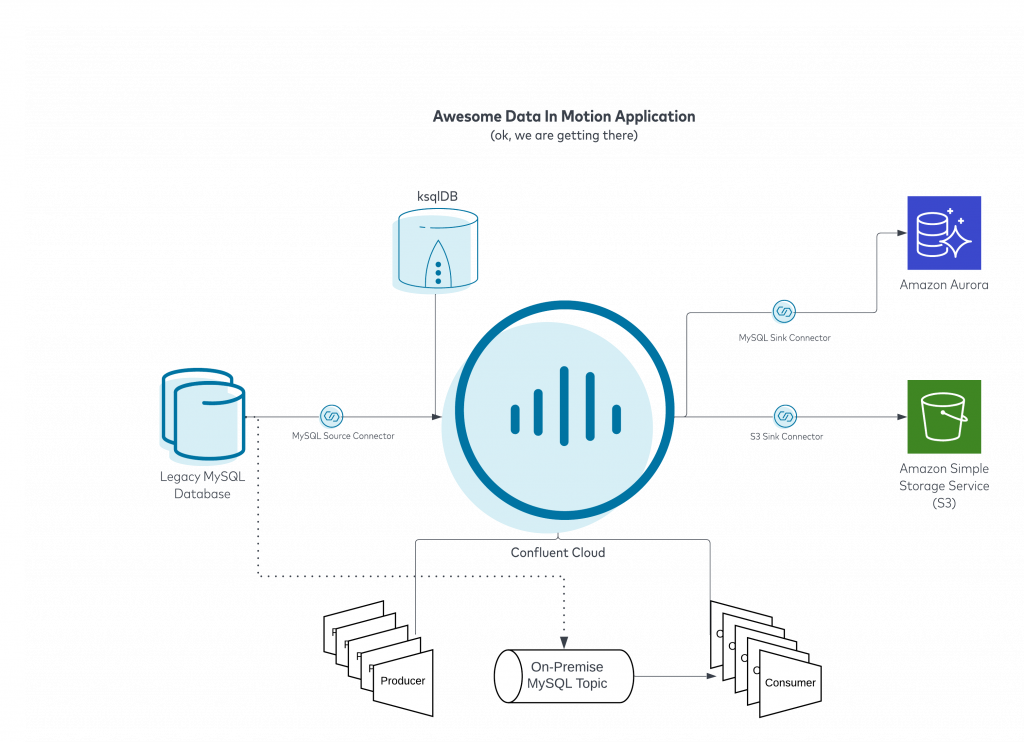
Power new apps with next gen data streaming fully integrated with your cloud database
Now I must call out to you that you still need to set up standard database things on Aurora, you will want to ideally recreate your tables, authentication requirements, stored procedures, triggers, etc. in Aurora before setting up the connector. Confluent is going to keep all of the data in the tables synchronized making cutover easier but you still need to get the new house in order before cutting over. Let’s set up our MySQL Sink connector to get the data we already have in Confluent Cloud into the new Aurora database.
 Let’s search for our connector (Data Integration Menu -> Connectors)
Let’s search for our connector (Data Integration Menu -> Connectors)
In this example, we will pick our fully-managed MySQL Sink Connector, then pick the topic we want to send from.
We will just need to supply some connection details for the database and how we want to insert the data.
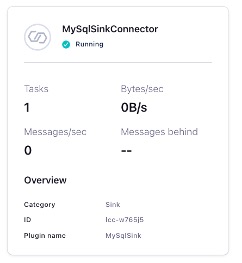
Once our connector status is Running we can go check out new Aurora database
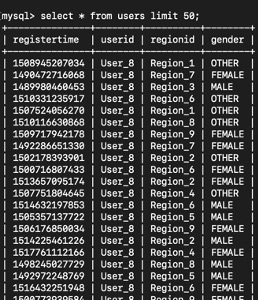
Our data is in Aurora MySQL
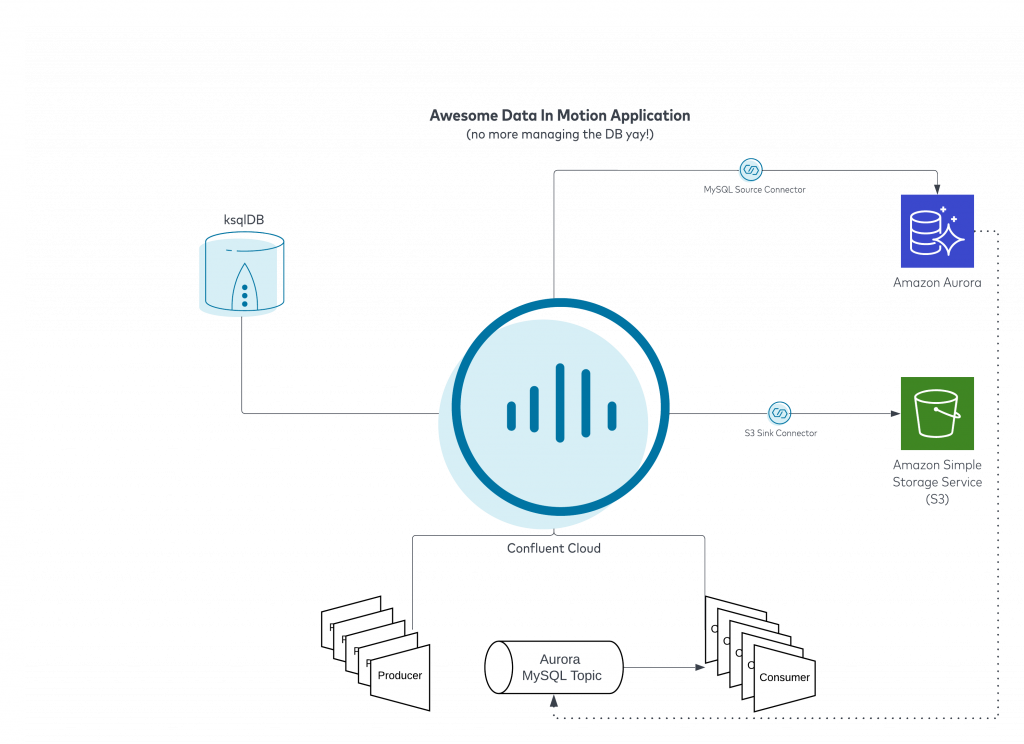
So after some verification steps we have confirmed that all of our data is being replicated to Amazon Aurora in real time. We just have three more steps before we can shut down “ole reliable” on the left. First we need to set up a new MySQL Source Connector to pull tables from Amazon Aurora, unfortunately we cannot use the original connector as there are unique binlog locations in MySQL that the connector uses to track its place in the table which will be different between on-premise MySQL and Aurora. Once the new source connector is set up and running (see diagram below), let’s plan a minor maintenance so we can prevent anything new being written to legacy during the cutover.
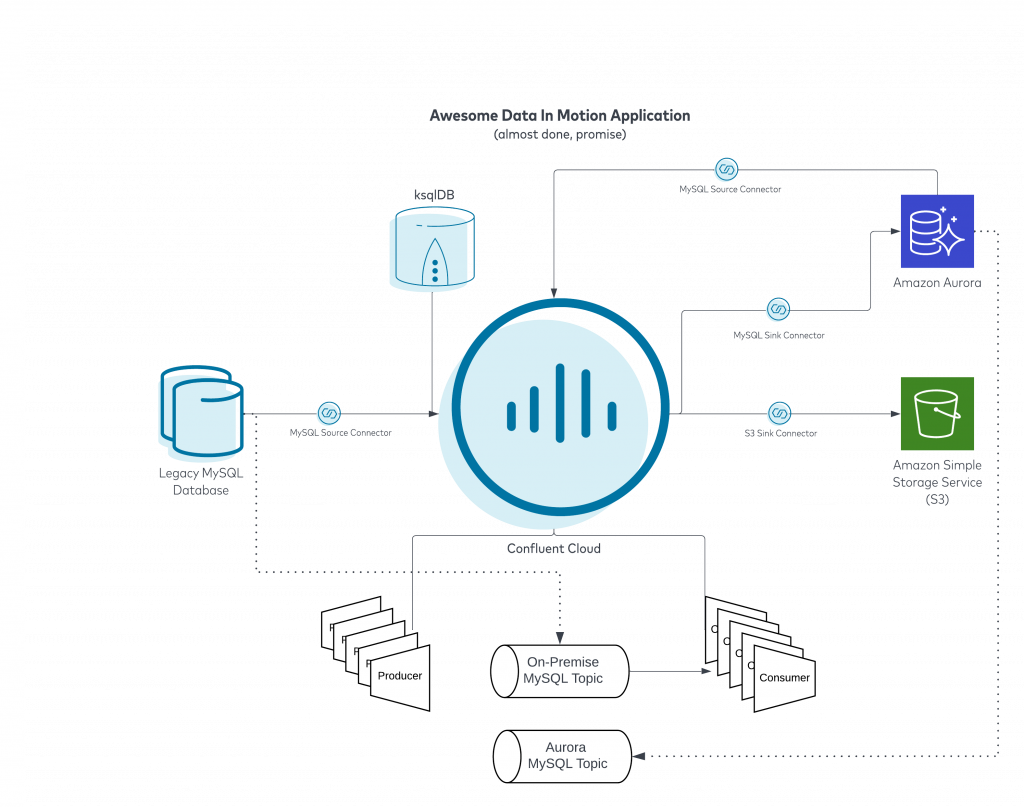
Data pipelines powered by Confluent using fully-managed connectors
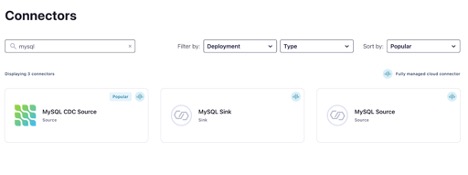
Let’s search for the MySQL CDC Source Connector, select it, and let’s move onto configuration
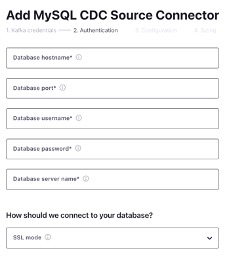
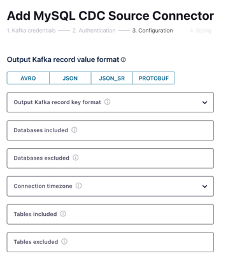
We will just need to supply some connection details for the database, which tables we want to source, and how we want to serialize the data.
Once our connector status is Running we can continue our migration, by pointing our consumers at the new Aurora MySQL topics yielding the following architecture:
Reduce the TCO of hybrid and multicloud data pipelines powering streaming ETL for your database.
We took legacy right out of the picture! Of course we could always fail back to Legacy, it is simply out of mind at this point as the original source and sink are still running. Assuming that all verification steps pass, you would want to repoint any direct users of the Legacy Database to the endpoint of Amazon Aurora, then shut down the old source connector and sink connector we used for migration.
If we check our new topic we can see our data is already there:
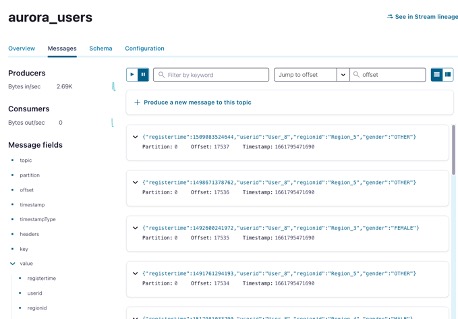
To summarize: We had our old unloved on-premise MySQL DB cluster connected to our awesome data-in-motion applications on Confluent Cloud which already unlocked amazing event driven outcomes using historical data. Eventually the tech debt of the on-premise cluster became too much to bear so we explored cloud-native options and landed on Amazon Aurora since it was compatible with MySQL and AWS will assume much of the operational burden. We used a combination of Confluent Connectors to synchronize data between on-premise and Aurora. Finally we cutover our event driven architecture to source data from Aurora so we can ultimately retire “ole reliable”. We hope you enjoyed reading this as much as we enjoyed writing it! If you want to learn more about Confluent Cloud on AWS please visit: Confluent on AWS and if you just want to learn more about building data-in-motion applications please check out: Our Developer Site.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Beyond Boundaries: Leveraging Confluent for Secure Inter-Organizational Data Sharing
Discover how Confluent enables secure inter-organizational data sharing to maximize data value, strengthen partnerships, and meet regulatory requirements in real time.



Real-Time Toxicity Detection in Games: Balancing Moderation and Player Experience
Prevent toxic in-game chat without disrupting player interactions using a real-time AI-based moderation system powered by Confluent and Databricks.