[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Set Your Data in Motion with Confluent and Apache Kafka
Today’s consumers have the entire world at their fingertips and hold an unforgiving expectation for end-to-end real-time brand experiences. This has become table stakes. If they have any need, it’s met instantly — whether that’s watching the latest blockbuster movie, sending a friend $5 for coffee, or calling a car to get to the birthday party starting in ten minutes. In fact, consumers today don’t just want their needs to be met quickly. They expect brands to actually anticipate their needs before they do and act to solve problems before they occur. How do companies do this? With data in motion.
Data in motion is the underlying, fundamental ingredient to any truly connected customer experience. It provides a continuous supply of real-time event streams coupled with real-time stream processing to power the data-driven backend operations and rich front-end experiences necessary for any business to succeed within today’s competitive, consumer-driven markets.
Your business and customers are in constant motion. So shouldn’t your data be too?
Bring data in motion to your business
Working with data in motion means working with Apache Kafka®. First developed at LinkedIn by the founders of Confluent, Kafka is a distributed event streaming platform capable of handling trillions of events a day. Initially conceived as a messaging queue, Kafka is based on an abstraction of a distributed commit log. Since being created and open sourced in 2011, Kafka has quickly evolved into a full-fledged event streaming platform for data in motion leveraged by over 70% of the Fortune 500 today.
At the onset, it helps to have a clear understanding of where data in motion and Kafka can take your business. At Confluent, we think about Kafka adoption in terms of an event streaming maturity model which ultimately results in the technology established as the central nervous system to your entire business. This means all data in the organization—covering every team and every use case, whether on-prem or in the cloud—is managed through a single platform for data in motion. A globally scaled and mission-critical event-driven architecture serves up data as a product to be leveraged across countless applications and limitless use cases.
Big opportunity. But where to begin?
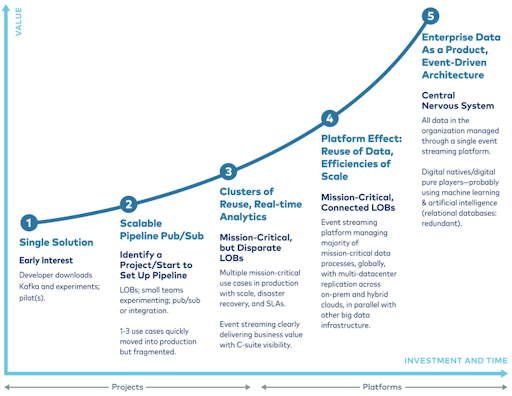
Getting started with data in motion and working with Kafka doesn’t have to be a daunting task. You just have to choose a place to start, and once you do, value is found quickly. We see three common areas where businesses can find the most value with data in motion right out of the gate.
Event-driven Microservices
The popularity of modern architectures based upon event-driven microservices comes from an industry move toward decoupling services into small, reusable components in order to simplify development and management of large data systems. Rather than being tangled within a monolith of code, different functions within an application can operate independently and asynchronously which allows for reduced complexity, reduced risk, and a faster means to both launch and scale new apps. Additionally, with microservices, organizations are able to improve collaboration and increase productivity by designing systems that reflect their different teams. Kafka provides businesses with a single platform to effectively manage communications between these different components.
Learn more now: Attend a Microservices webinar
Streaming ETL
Businesses are in constant need of data integration with ETL (extract, transform, and load). However, modern requirements now call for data integration to run across distributed platforms, with support for more data sources/types, and with fast, real-time processing. Kafka allows for data integration with a broad portfolio of pre-built source and sink connectors while ksqlDB enables real-time processing and enrichment of data in motion.
Learn more now: Watch a Streaming ETL demo
Customer 360
A popular first solution customers march toward with Kafka is Customer 360. Over time, as businesses grow, they develop more and more teams, and those teams hold siloed data sets with valuable customer information trapped within each. Those data sets are exponentially more valuable to a business when they can be aggregated and analyzed together. Kafka allows previously siloed systems to communicate through a single, central platform to deliver a comprehensive view of your customers and their interactions with your business.
Learn more now: Review the Customer 360 solution
These are just three options for introductory use cases and only a scratch of the surface in terms of what you can do with data in motion. Learn more within Confluent’s solutions overview.
Build and launch faster with a fully managed, cloud-native service for Kafka
When it comes to actually deciding how to begin working with Kafka, you’ll have options. Unless you’re in the business of managing data infrastructure, self-managing open source Kafka in a DIY fashion is not an ideal path to take. When accounting for cluster sizing, scaling, Zookeeper management, integrations development, patches, upgrades, and more, the cost of managing open source Kafka grows over time and seriously limits your ability to focus on true value and innovation. Many of these responsibilities stay on your plate with other partially managed services. Instead, leverage a service that allows you to fully focus on your core business priorities. Confluent provides a truly fully managed Kafka service that is cloud-native, complete, and everywhere.

Cloud-native
With Confluent Cloud, you can provision serverless Kafka clusters on demand that scale elastically between 0-100 MBps or get you to GBps+ scale with just a few clicks. Instant elasticity like this means you can easily scale up to meet unexpected demand and just as quickly scale back down to manage cost. You pay for what you need, when you need it, and no more.
You can also store unlimited amounts of data on your Kafka clusters, without any upfront capacity planning or provisioning. Kafka becomes a system of record so you can do more with your real-time events. Most importantly, leveraging a cloud-native platform means running with the confidence that it just works. Our highly available clusters are backed by a 99.95% SLA and always on the latest stable version of Kafka—upgraded and patched in the background like a true cloud-native service.
Complete
Confluent does way more than just manage Kafka for you. You get a complete platform built around it in order to quickly execute projects. We provide out-of-the-box, fully managed connectors for the most popular data sources/sinks in the Kafka ecosystem, Schema Registry and validation to maintain data quality, stream processing with a streaming database, and more—all fully managed in the same cloud UI.
There’s no cutting corners when it comes to data safety and compliance. Confluent secures your Kafka environment with encryption at rest and in transit, role-based access controls, Kafka ACLs, and SAML/SSO for authentication. More granular control with private networking and BYOK for your Kafka environments is available as well. Finally, we design with compliance and privacy in mind with SOC 1/2/3 certifications, ISO 27001 certification, HIPAA/GDPR/CCPA readiness, and more.
Everywhere
Studies have shown that 80 percent of companies use more than one cloud service provider. If you’re one of the lucky ones with a single provider, that’s great. If not, a Kafka deployment that only works in a single environment undercuts your ability to leverage data in motion across your entire business and every customer experience. Confluent lets you link Kafka clusters that sync in real time, so your events are available anywhere—across multiple public or private clouds.
No better way to work with data in motion than with Confluent
Confluent offers the options and assistance you need to move at top speed on your journey with data in motion. Developers can work in their language of choice (including C/C++, Go, .NET, Python, and our REST Proxy) and on whichever major cloud marketplace necessary including AWS, Azure, and Google Cloud. You can even use your existing cloud provider credentials to quickly access Kafka and unify billing by leveraging your existing cloud commitments.
Whether you and your teams are brand new to Kafka or already experienced with building event streaming apps, developers serious about establishing themselves as data-in-motion experts come to Confluent. We take a hands-on, learn-while-you-build approach to technical education. In-product tutorials will guide you from early development to advanced, real-time solutions, stepping you through everything from cluster creation and Schema Registry setup to connector integrations and the creation of your first stream processing app.
Finally, organizations running Kafka for business critical applications need the peace-of-mind and backing from an expert vendor that can provide enterprise-grade support and services. Confluent was founded by the original creators of Apache Kafka and has over 1 million hours of experience building and supporting the technology, enabling us to provide a fundamentally different level of expertise than other vendors. We don’t just help you with break-fix issues; we offer guidance, professional services, training, and a full partner ecosystem to serve your needs with expert-backed best practices throughout the entire application lifecycle.
Simply put, there is no other organization better suited to be an enterprise partner for your Kafka projects, and no other company that is more focused on ensuring your success with data in motion.
Get started today
Ready to take the first steps toward bringing the value of data in motion to your business? Watch a Confluent Cloud demo or jump right in and sign up for a free trial.
Want to dive a little deeper into what it means to set your business’ data in motion? Read the free ebook Set Your Data in Motion with Confluent and Apache Kafka®.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Beyond Boundaries: Leveraging Confluent for Secure Inter-Organizational Data Sharing
Discover how Confluent enables secure inter-organizational data sharing to maximize data value, strengthen partnerships, and meet regulatory requirements in real time.



Real-Time Toxicity Detection in Games: Balancing Moderation and Player Experience
Prevent toxic in-game chat without disrupting player interactions using a real-time AI-based moderation system powered by Confluent and Databricks.