[Webinar] Unlock Data Value Framework for Data Products | Register Now
The New One-Stop Shop for Learning Apache Kafka
Today, I’m very excited to announce an all-new website dedicated to Apache Kafka®, event streaming, and associated cloud technologies. The site is called Confluent Developer, and it represents a significant milestone in our collaboration with the Kafka and Confluent communities.
One of the things that makes Kafka exciting is that it isn’t just another data store; it’s really something quite different. Learning the nuances of the technology involves adapting to a whole new ecosystem alongside a new way of thinking about data. As with many open source technologies, the information you need to answer such questions is available. Yet, many developers face a challenge navigating these disparate resources arranged across the internet in a coherent manner. Confluent Developer helps to solve this problem, compiling all the information you need in one place, from your first steps in event streaming right through to more complex topics: microservice architectures, data pipelines, and company-wide systems for data in motion. Here is a taster of what’s available.
The most complete, free library of Kafka-related courses on the internet
The site ships with a comprehensive selection of courses—each completely free:
- Kafka 101
- Connect 101
- Kafka Streams 101
- ksqlDB 101
- Inside ksqlDB
- Spring Framework and Apache Kafka
- Building Data Pipelines
- Event Sourcing and Event Storage in Apache Kafka
- Data Mesh 101
These courses span various learning styles, with video, written learning materials, and hands-on exercises. The course’s creators work full-time on the technologies they cover. For example, the Kafka Streams course was prepared by Bill Bejeck, a Kafka committer and PMC member, and delivered by Sophie Blee-Goldman, an engineer on our Kafka Streams team. The “Inside ksqlDB” course is prepared and presented by ksqlDB’s Product Manager Michael Drogalis. These are people that sleep, live, eat, and breathe data in motion, and their deep domain knowledge comes through in the courses they deliver.
Getting-started experiences tailored to a wide range of programming languages
Kafka has clients for most programming languages you may wish to use, but it wasn’t always easy to get started. Confluent Developer includes getting-started guides tailored to some of the most popular languages, including Java, Python, Go, REST, .NET, NodeJS, and C/C++. These guides take you through the step-by-step process of building an application with Kafka and the language of your choice in an easily accessible and idiomatic way.

A catalog of design patterns just for event streaming
One section of Confluent Developer that we’re very proud of is the Event Streaming Patterns catalog. The site includes a catalog of more than 50 design patterns, starting with simple ones like Event Stream and Event Processing Application and extending into more complex compositions like Event Collaboration and CQRS.
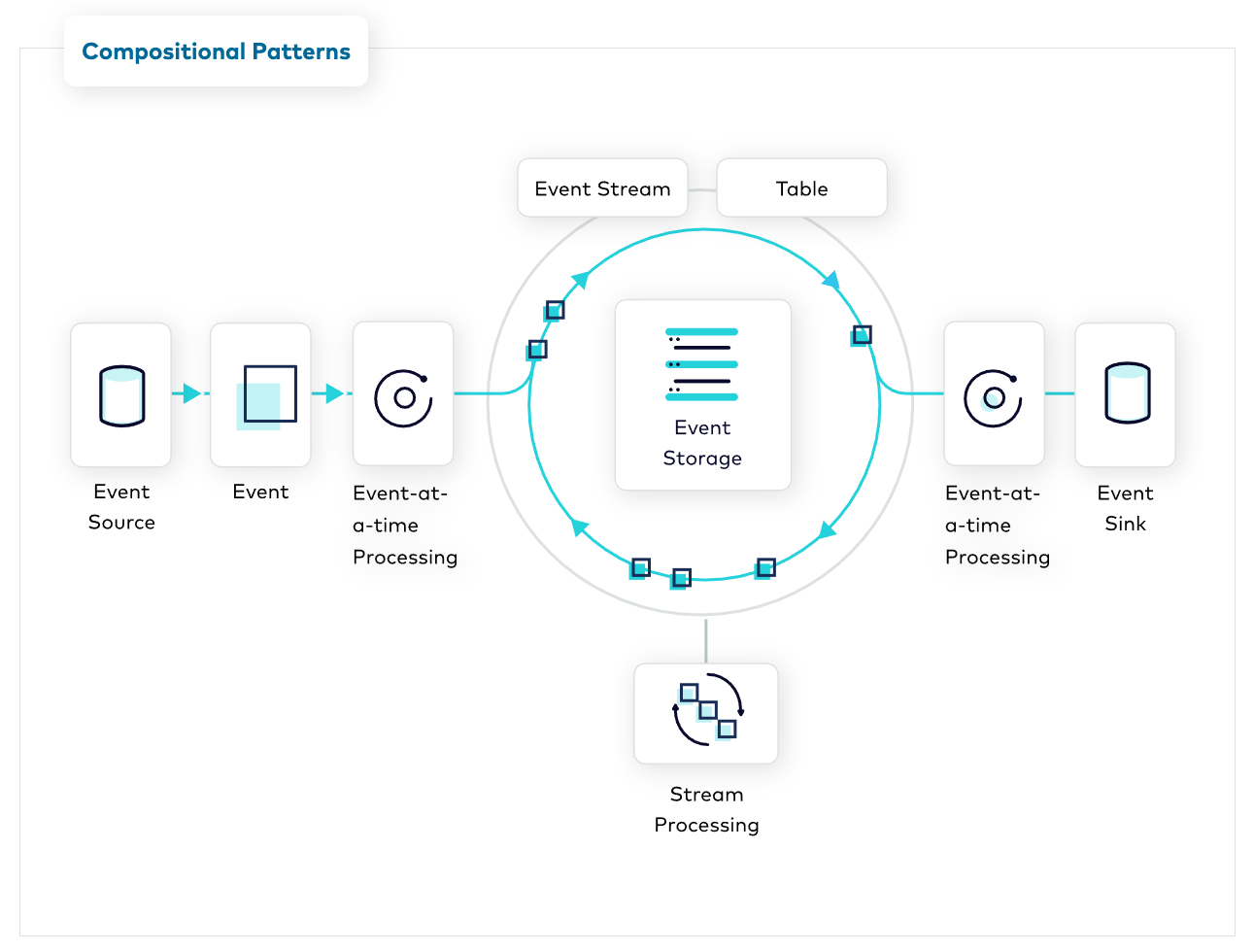
These patterns play several important roles in designing systems for data in motion. For one, they establish a common language, just as you might use the terms singleton, circuit breaker, or proxy today. Secondly, these patterns enumerate the foundational components needed to build more complex systems—a recipe book you can use to piece together the perfect meal.
Interactive exploration of Kafka’s internals
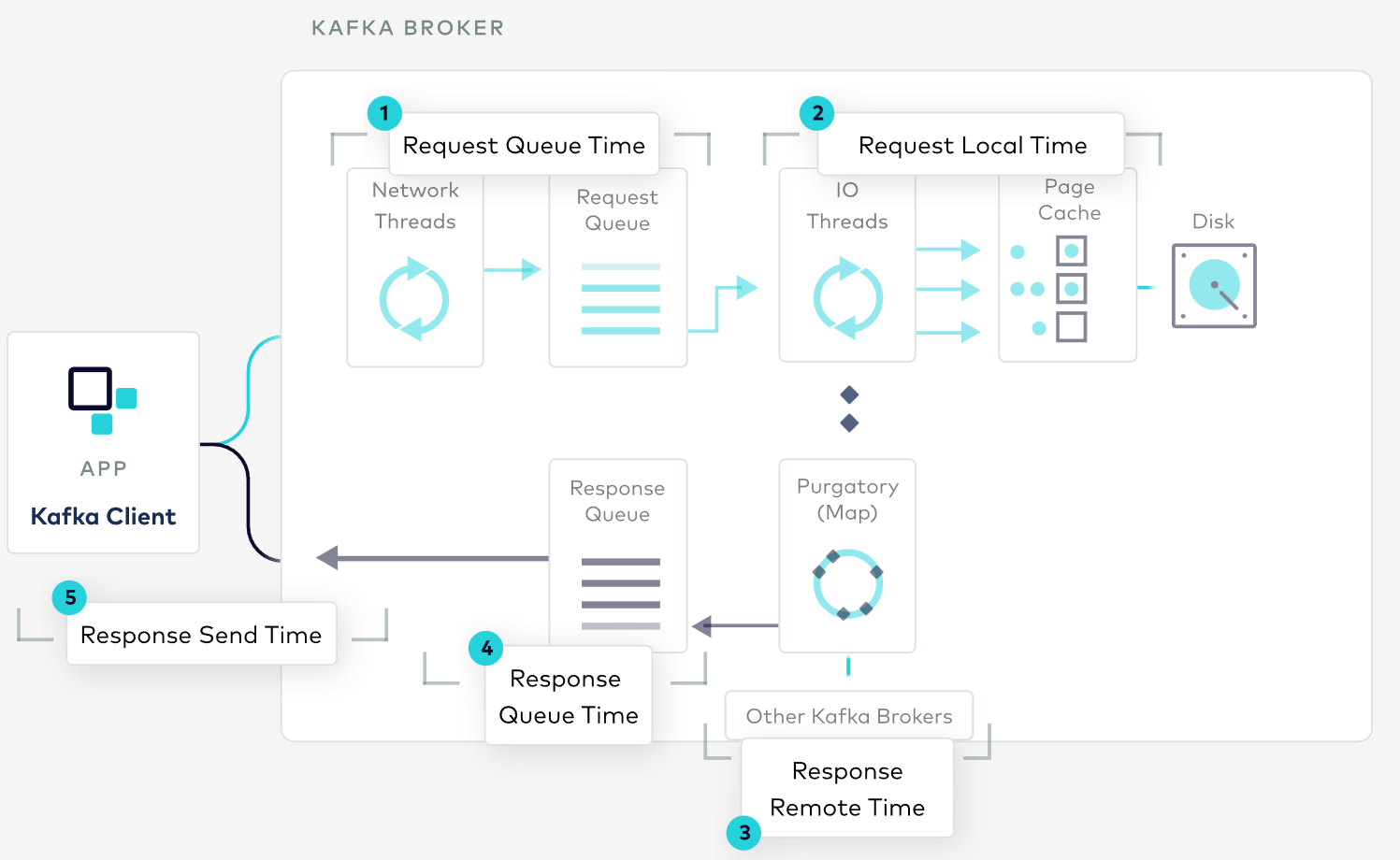
Kafka’s internals have many moving parts spanning network, I/O, replication, and persistence. Confluent Developer ships with two unique, interactive diagrams that help you understand how these different modules fit together, measure their performance and tune their configuration, providing a solid mental model for how the system works under the hood.
A single home for Apache Kafka learning
Confluent Developer covers all you need to know about Apache Kafka, event streaming, and Confluent Cloud. There is a vast amount of information on the site, and we’ll be adding to it over the coming releases. We hope you find the site both exciting and informative.
Find out more at dev.confluent.io.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Powering AI Agents With Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


